# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近真是 AI 圈的大年三十初一初二初啊。。。。。
各个大厂都争先恐后的整花活!
OpenAI 放出了 o1 Pro、GPT-4o 高级语音、GPTCanavas,就跟孔雀开屏一样 ~
谷歌最近的大动作是发布了 Gemini 2.0 嘛!2.0 比 1.5 版本快一倍,而且是原生的多模态大模型,能输入和生成语言、声音、图片、视频等。
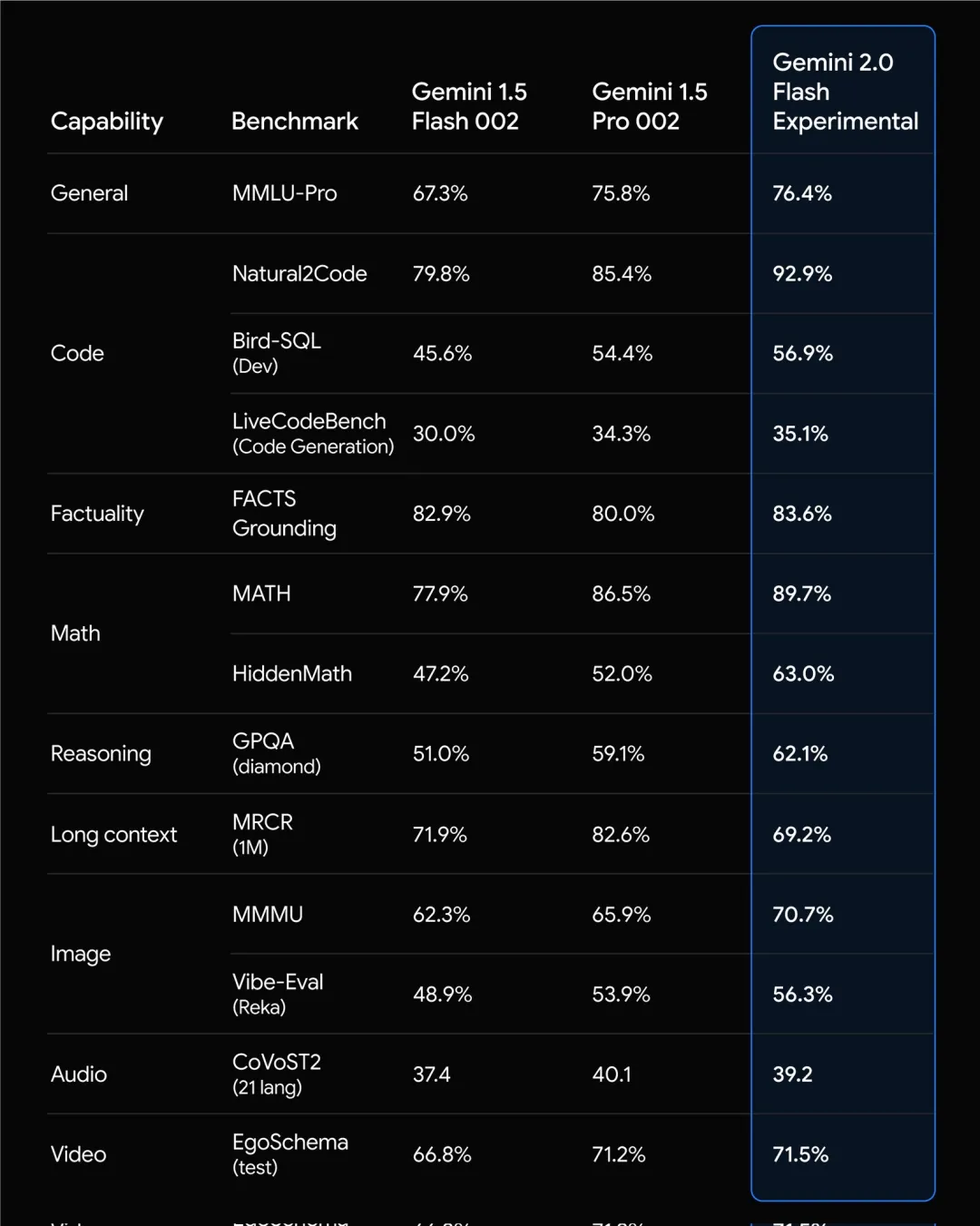
而且,最受大家震撼的是超级超级低的实时,无卡顿的多模态交互!
只能说非常牛,小瑶灰常好奇究竟咋做到的,然后就去扒了下训练背后的故事,结果!小瑶发现谷歌真正牛的是用来训练 Gemini 2.0 的芯片 Trillium!即第 6 代 TPU,比上一代 TPU 5e 性能提升可以说非常非常显著了!
这些硬件上的进步都给 AI 训练带来了实打实的好处!包括了:
要让像 Gemini 2.0 这样的多模态大语言模型加速训练,首先需要更大规模的数据和更强大的计算资源。
Trillium 的技术可以视为一名超级助手:它将庞大而复杂的计算任务分散到众多主机中,并通过高速 Jupiter 数据中心网络 紧密相连。这种协同工作就好像将 256 个芯片聚合成一个紧密合作的“大家族”。
在加速训练的过程中,Trillium 借助名为 “TPU 多切片(TPU multi-slicing)” 的技术,使得大规模训练变得更加高效。与此同时,还有一个名为 “Titanium” 的系统,它能从主机适配器到网络架构层面全面支持动态任务卸载,确保整个数据中心的运行更加顺畅。
在实际应用中,Trillium 在一个由 12 个这样的“大家族”构成、共计 3072 个芯片的环境中,实现了 99% 的扩展效率;在一个更大的 24 个“家族”、共 6144 个芯片的部署中,也依然达到 94% 的扩展效率。这意味着,即便是在训练如 GPT3-175b 这样超大规模的模型时,无论是在单一数据中心还是跨数据中心环境中,Trillium 都能以极高的效率推动模型训练进程。
官方链接:https://cloud.google.com/blog/products/compute/trillium-tpu-is-ga
快来和小瑶一起来看看具体的提升!
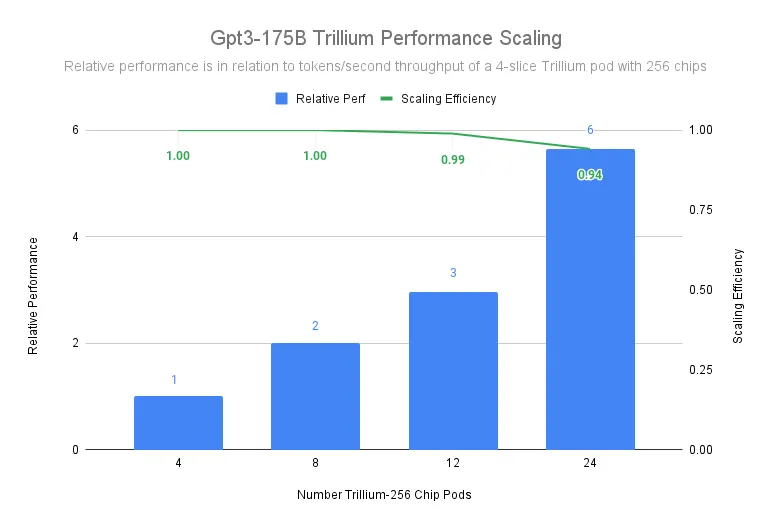
如下图所示,即使使用 1 片 Trillium-256 芯片的 Trillium-256 芯片舱作为基线,在扩展到 24 个芯片舱时,仍然能够达到超过 90% 的扩展效率。
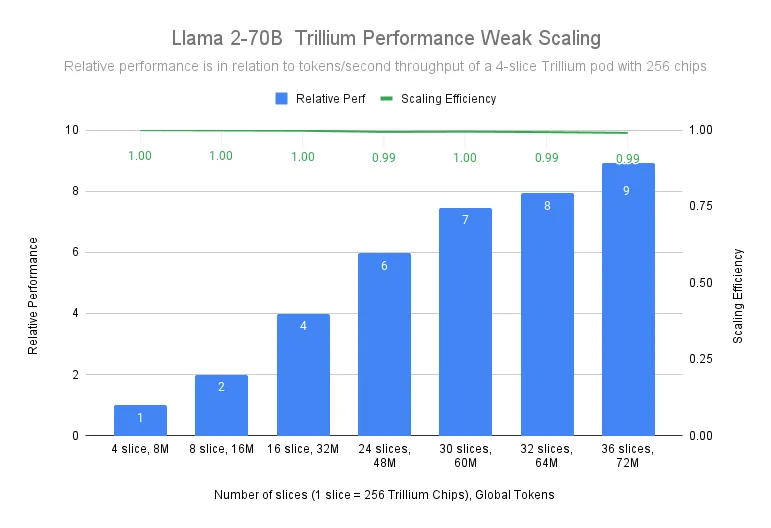
在训练 Llama-2-70B 模型时,谷歌测试表明,Trillium 从 4 片 Trillium-256 芯片舱扩展到 36 片 Trillium-256 芯片舱时,几乎实现了线性扩展,扩展效率达到了 99%
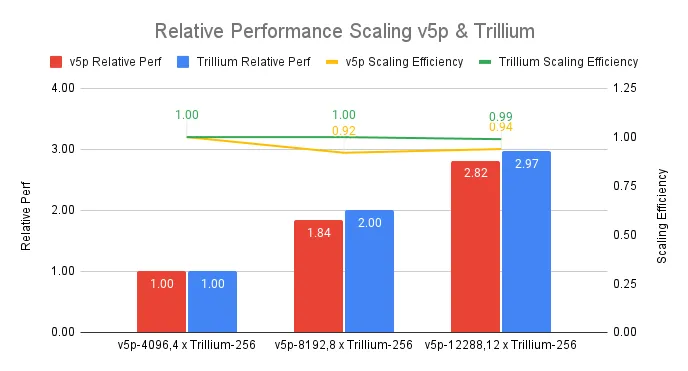
还有一个更直观的看法就是,将 Trillium TPU 与 Google 前代产品(v5p)对比一下!
在下面的图表所示,在 12-pod 规模下,Trillium 的扩展效率达到了 99%,与同等规模的 Cloud TPU v5p 集群(总峰值浮点运算次数)相比遥遥领先。
像 Gemini 这样的大语言模型(LLM)本身就具有数十亿个参数,先天强大且复杂。要高效训练这些密集型的大模型,不仅需要雄厚的计算能力,还离不开软硬件协同优化的解决方案。
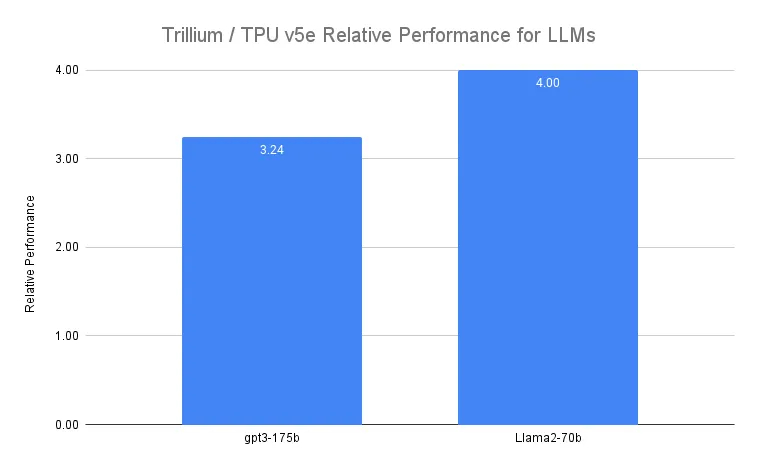
Trillium 在训练诸如 Llama-2-70b 和 gpt3-175b 这类极其庞大的 LLM 时,相较于上一代 Cloud TPU v5e 能实现高达 4 倍 的加速性能。
如下图所示:
此外,除了传统的“大模型”之外,采用 专家混合(MoE) 架构的大语言模型正日趋流行。
这类架构由多个“专家”神经网络组成,每个专家擅长处理特定的任务领域。然而,与训练一个单一、庞大的模型相比,对这些专家进行有效协同与管理,无疑提高了训练的复杂性。
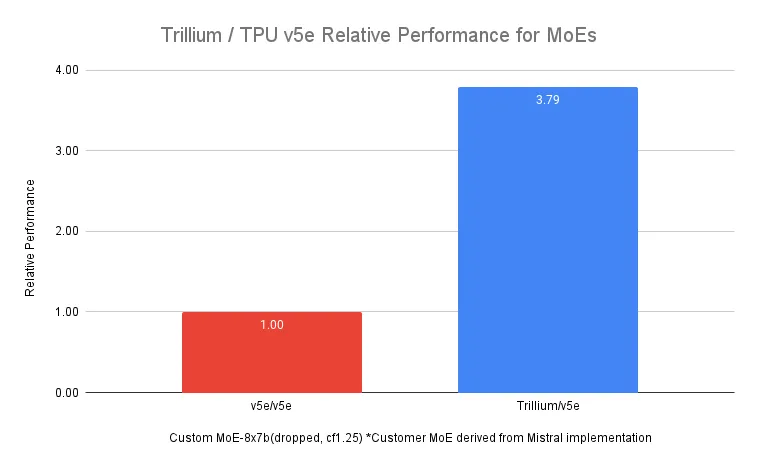
即便如此,Trillium 在训练 MoE 模型 时也依旧展现出强大的性能提升,如下图所示,相比上一代 Cloud TPU v5e 能快上 3.8 倍。
面对越来越重要的多步推理(multi-step inference)需求,具有更高处理效率的加速器变得至关重要。
Trillium 加速并优化了 AI 模型的部署,因此它在图像扩散模型和密集型大语言模型的推理性能上均表现出色。
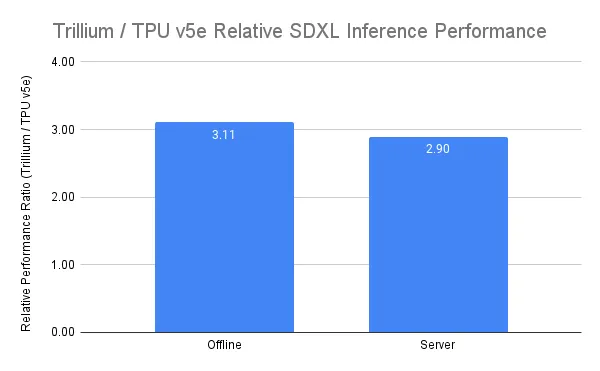
如下图所示,相较 Cloud TPU v5e,使用 Trillium 对 Stable Diffusion XL (SDXL)进行推理时,每秒图像吞吐量提升超过 3 倍;在 Llama2-70B 的推理中,每秒 Token 吞吐量提升近 2 倍。
随着第三代 SparseCore 的引入 Trillium ,其在处理嵌入密集型模型(embedding-heavy models)时的性能提升了 2 倍,在 DLRM DCNv2 模型上的性能更是提升了 5 倍。
SparseCore 是为嵌入密集型工作负载打造的数据流处理器架构,能够灵活适应多样化的计算需求。它擅长处理动态且数据相关的操作,例如散布-收集(scatter-gather)、稀疏段求和(sparse segment sum)以及分区(partitioning),从而在动态数据环境中保持高效运转。
因此,Trillium 现在不仅在规模和性能上满足训练当今最大 AI 工作负载的需求,还注重优化每美元性能。
在实际训练中,相较于 Cloud TPU v5e,Trillium 在训练密集型 大语言模型(如 Llama2-70b 和 Llama3.1-405b)时,可实现高达 2.1 倍 的性能提升;而与 Cloud TPU v5p 相比,则可获得 2.5 倍 的性能提升。
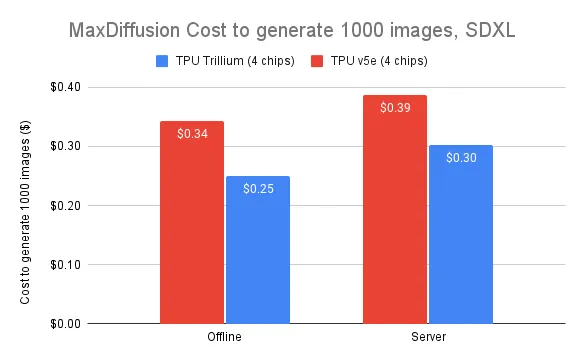
在 Trillium 上生成 1000 张图像的成本比 Cloud TPU v5e 离线推理降低 27%,比 Cloud TPU v5e 在 SDXL 上的服务器推理成本降低 22%。这意味着用户可以在保证高性能的同时,以更合理的投入获得更高的产出。
在目前人工智能创新不断攀升的时代,Trillium 再次证明了谷歌云在 AI 基础设施领域的独特优势。
相比之下,OpenAI 数次尝试自研芯片却碰壁收场,至今进度成谜。。。
而谷歌不仅能扩展至数十万颗芯片的庞大规模,更能借助软硬件协同优化,让 Trillium 成为行业新标杆。
不得不说。。底蕴深厚的老牌大厂自有其过人之处,谷歌仍是那个让人心服口服的科技巨头!
文章来自微信公众号“夕小瑶科技说”,作者“付奶茶”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
