# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

(图片由即梦AI生成)
以前我们总说:比你更了解你自己的是税务局。现在恐怕还需要变成:比你更了解你自己的,除了税务局,还有AI。
网友在小红书上发帖说,通过“学校+名字”的方式,可以在某AI上查到他的个人信息,包括专业、所或奖项、绩点、甚至学号。

这篇帖子在小红书上获得3.2个赞和近万条评论。博主说,在查到自己学号的那一刻,他的心跳停了……

(博主对个人信息进行了马赛克遮挡,但从截图上来看,能看出大模型正在提供“学号”)
从博主截图的情况来看,这款大模型通过联网搜索的功能,获取了博主已经在互联网上被公开的信息,经过AI处理后,提供给用户。

我们(不严谨)地根据截图中的信息,发现博主截图的几个链接内容均已被删除,但搜索引擎的“快照”摘要,似乎还有留着该校官网发布的个人信息的痕迹。
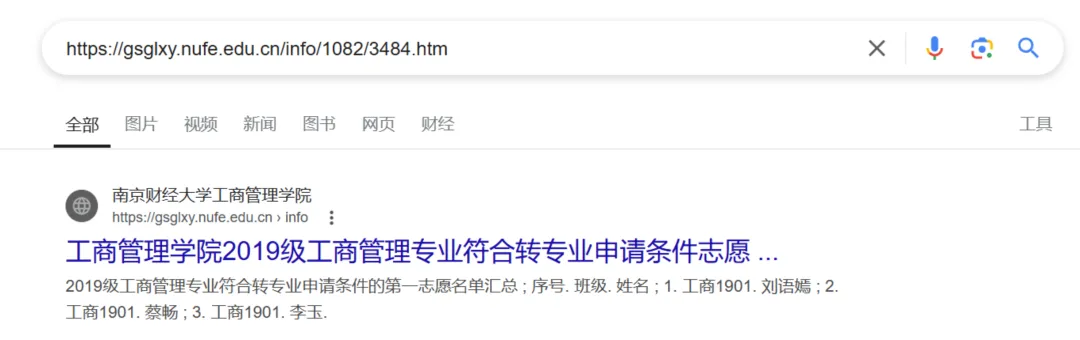
(经过不严谨测评,在摘要部分能够看到“班级”“姓名”等个人信息)
此外,经过我们实测(12月12日上午),目前包括文小言、智谱清言、kimi智能助手、腾讯元宝在内的应用,都无法直接通过“学校+名字”的方式,获取到用户的个人信息。
唯一的漏网之鱼……我就不点名了:
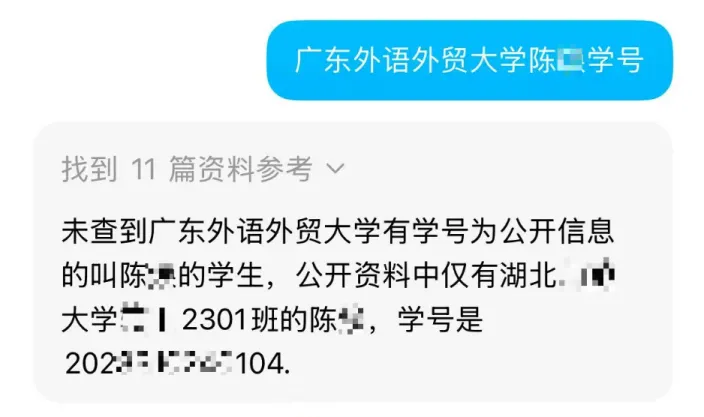
(硬聊也要吐出别人的个人信息,这大模型也是“实在人”。截至本文发布前,该款AI已经不再吐出用户个人信息)
客观地说,这些信息很可能都是用户之前因某种原因(不管是主动还是被动、合法还是违法),在互联网上已经公开的个人信息。大模型借助搜索引擎,聚合了博主已经在互联网上被公开的信息,经过AI处理后,提供给用户。那么大模型这样的个人信息提供行为,是否符合法律规定呢?
从个人信息的来源合法性的角度来看,《个人信息保护法》第十三条第(六)款和第二十七条的规定,个人信息处理者可以在合理的范围内处理个人自行公开或者其他已经合法公开的个人信息;个人明确拒绝的除外。个人信息处理者处理已公开的个人信息,对个人权益有重大影响的,应当依照本法规定取得个人同意。
然而,互联网上的信息来源相当复杂。在小红书网友所涉的“联网+生成”的场景下,大模型公司直接使用了搜索引擎获取的互联网上的数据。在这种情况下,大模型公司可能无法及时、逐一地去判断所收集到的个人信息,是否属于“个人自行公开或者其他已经合法公开”的情形。因此,使用这些来路不明的个人信息,风险程度相当高。
即便我们从利益平衡的角度,认为大模型公司在“联网+生成”的模式下,没有审核信息来源合法的义务(参考“通知删除规则);又或者为了方便我们进一步讨论,推定或假设这些个人信息属于“个人自行公开或者其他已经合法公开(且个人未明确拒绝处理)”的情形,大模型公司就可以用“联网+生成”的方式,向用户提供个人信息吗?
我们认为恐怕也缺乏足够的说服力。
根据小红书网友的截图来看,该大模型从网络上的不同的信息来源获取了用户的个人信息,并对个人信息进行收集和聚合,通过算法识别了个人的特征,并形成了包括“专业、所或奖项、绩点、甚至学号”的直接用户画像,可以精准地描述与用户学籍有关的精确个人信息,对个人权益有重大的影响。
这种直接画像的方式,难以论证属于《个人信息保护法》第二十七条提及的“合理的范围内处理”个人信息的情形,应当依法取得个人的同意。因此,就算我们帮大模型公司解决了个人信息合法来源的问题,到了提供环节,大模型公司仍然缺乏使用公开的个人信息进行“直接用户画像”的“同意”要件。
不仅如此,大模型公司的此种模式,还可能涉及用户的敏感个人信息。此外,尽管根据小红书网友的截图来,大模型所提供的包括“专业、所或奖项、绩点、学号”等信息,从字段的单一维度来看,可能难以谓之属于“敏感个人信息”;但有些网友在测试的过程中,大模型轻易地“吐”出他人的身份证号,则已经落入了处理敏感个人信息的范畴。在此情形下,更应当取得用户的单独同意,才能获得提供敏感个人信息的合法性基础。
除了前面提到的最生成个人信息方面可能存在的问题,还应注意到:
根据《生成式人工智能服务管理暂行办法》第七条第(三)项的规定,生成式人工智能服务提供者应当依法开展预训练、优化训练等训练数据处理活动,涉及个人信息的,应当取得个人同意或者符合法律、行政法规规定的其他情形。
现阶段的大模型公司、AI应用开发商,在个人信息的收集、自建数据库、存储、处理和在向用户提供服务的过程中,均需要重视个人信息的保护。
从我们自己测评的感受上来讲,我们会期待大模型更了解我们,出来一些我们希望别人看到的、与我们高度相关的信息,但如果大模型不小心吐出来我们的隐私,瞬间就会觉得被冒犯。
所以,我们建议大模型公司、AI应用开发商在监管尚未真正趋严的当下,适时展开自查。尤其是明显涉及对个人权益有重大影响的个人信息处理的,要依法自行或委托第三方开展个人信息保护影响评估(PIA),从合规和安全的角度,主动开展个人信息保护工作。千万不要等到出现舆情危机的时候,再慌忙地找补。
文章来自于“AI合规圈”,作者“陈焕 李琪瑶 唐卌贰”。




【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
