# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
豆包的“眼睛”升级了,现在让它看一眼APP截图,就能直接给你生成代码!
话不多说,我们直接给它上一个难度。
例如我们先随机截取一张网站的图片:

再来到火山方舟的大模型广场,pick一下最新的Doubao-vision-pro-32k版本:
(PS:该模型也可以在豆包APP中体验)
然后把刚才的截图“喂”给豆包,并附上一句简单的Prompt:
帮我写代码,克隆这个APP。
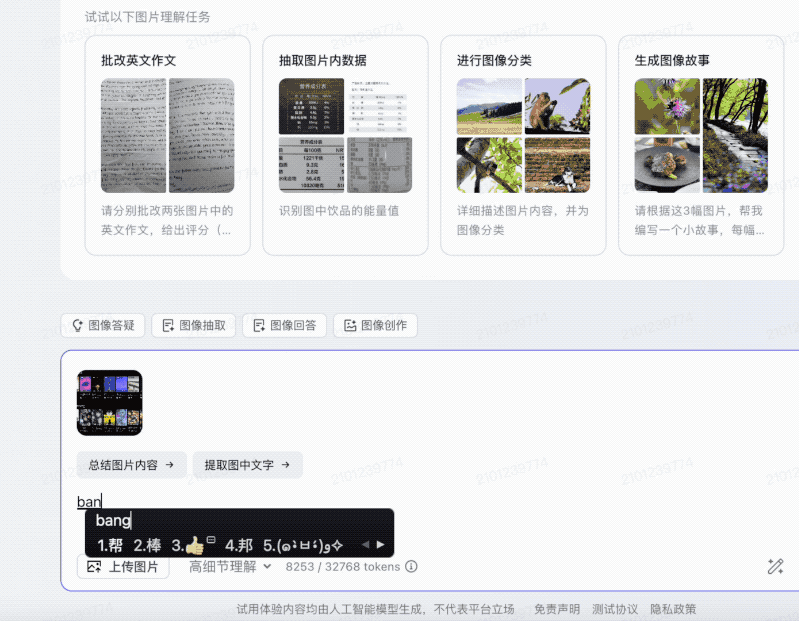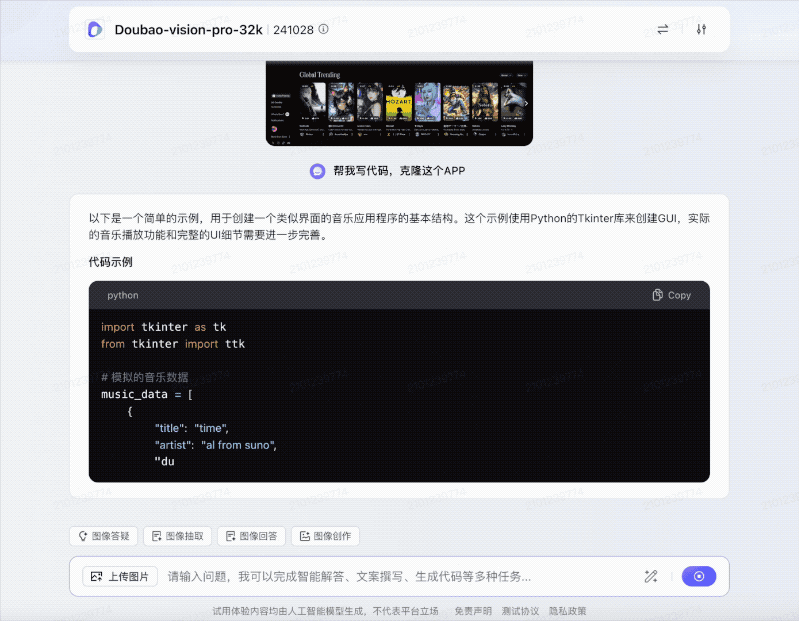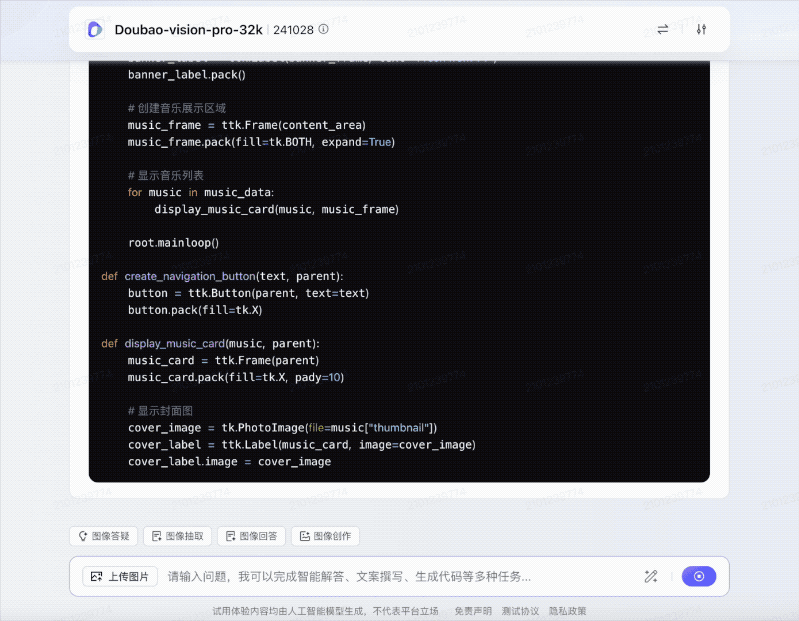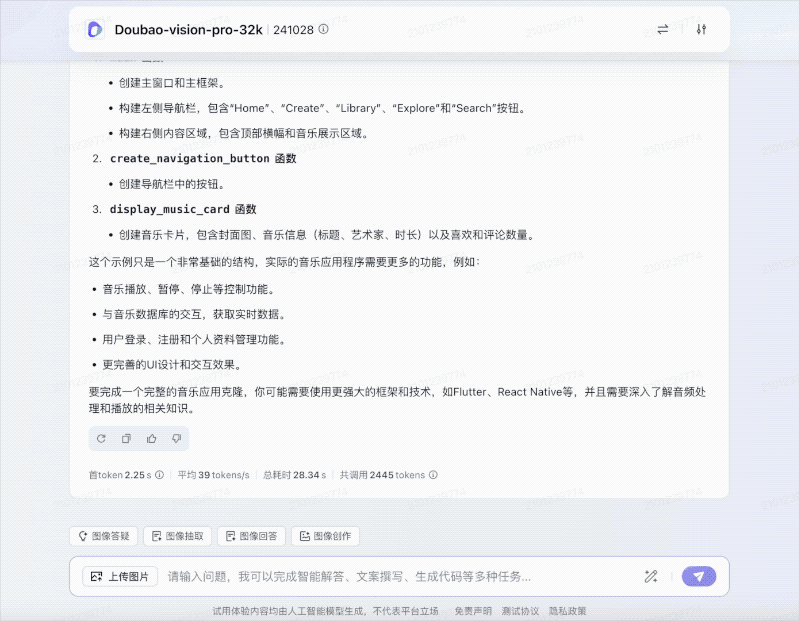
只见豆包先是秒看出这是一个音乐APP的界面,紧接着就唰唰唰地敲起了代码。
从代码的功能上来,包括了菜单栏、播放列表框架、播放列表列表框和状态栏。
模拟的播放列表中包含了几首歌曲的信息,包括标题、艺术家、时长和点赞数等。
而且这些都是在不到30秒内完成的。
若是想实现更复杂的功能,我们也是可以继续用说的:
那继续帮我实现更复杂的音乐播放应用。

这一次,也仅仅耗时1分钟,在原先代码的基础上,新增了控制面板、播放按钮、更新进度条等内容。
嗯,现在开发一个APP,真的变成截张图的事儿了。
这便是豆包最新发布的新模型——豆包 · 视觉理解模型。
综合来看,它的亮点可以归结为如下三点:
更重要的一点,发布即大降价——0.003元/千tokens。
相当于1块钱可以处理284张图片!

不过有一说一,毕竟考验大模型“视力”这事,不能只看单一的产品。
因此,接下来,我们就组个擂台,看看哪个大模型的“眼神”更好使。
我们请出的打擂台选手,正是目前大模型的顶流之一——OpenAI的GPT-4o。
比试规则也很简单,就是通过不同维度的试题,来看看作答的效果。
第一轮比试中,我们先小试牛刀一下一个不常见的水果,请看图:

然后我们分别问一下两位选手:
图中的是什么东西?
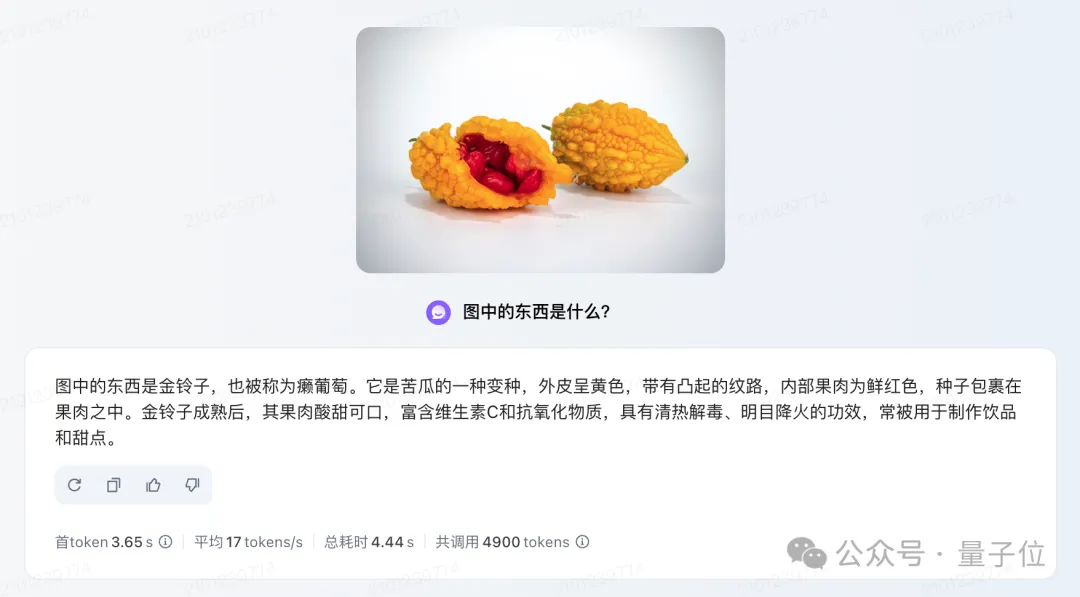
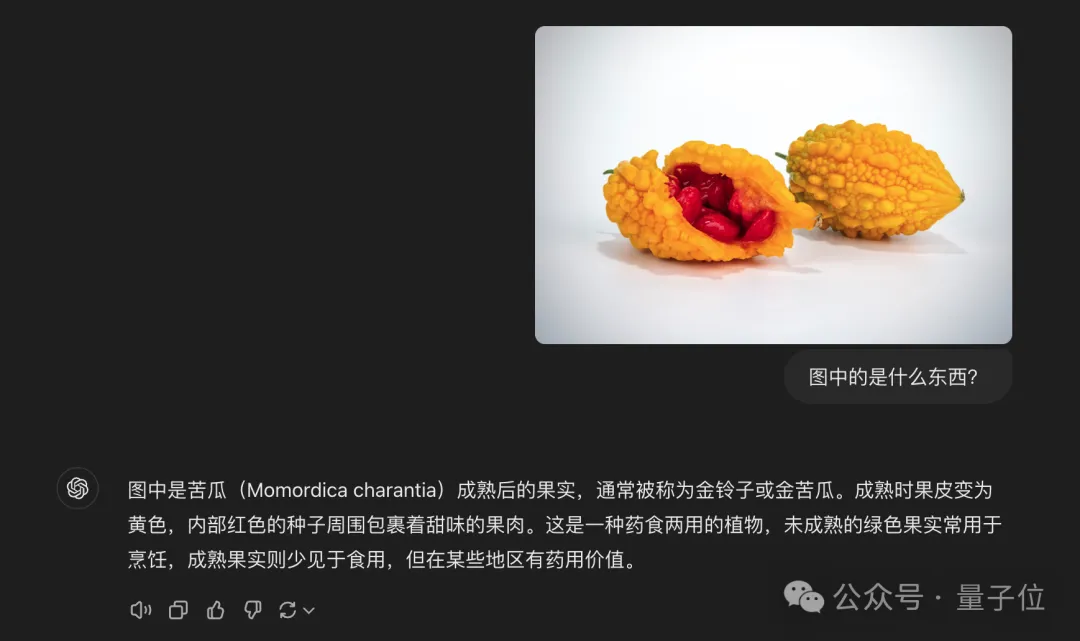
△上图为豆包作答;下图为GPT-4o作答(下同)。
从回答内容上来看,二者虽然都回答对了,但特点各有不同。
豆包·视觉理解模型回答更加与金铃子紧密相关;而GPT-4o则是更倾向于金铃子与苦瓜的不同。
若是比试要求是与图中物体高度相关,那么或许豆包·视觉理解模型的回答更优质一些。
再来一张冷门的图像,请看题:
这是什么?

再来看一下两位选手的作答:
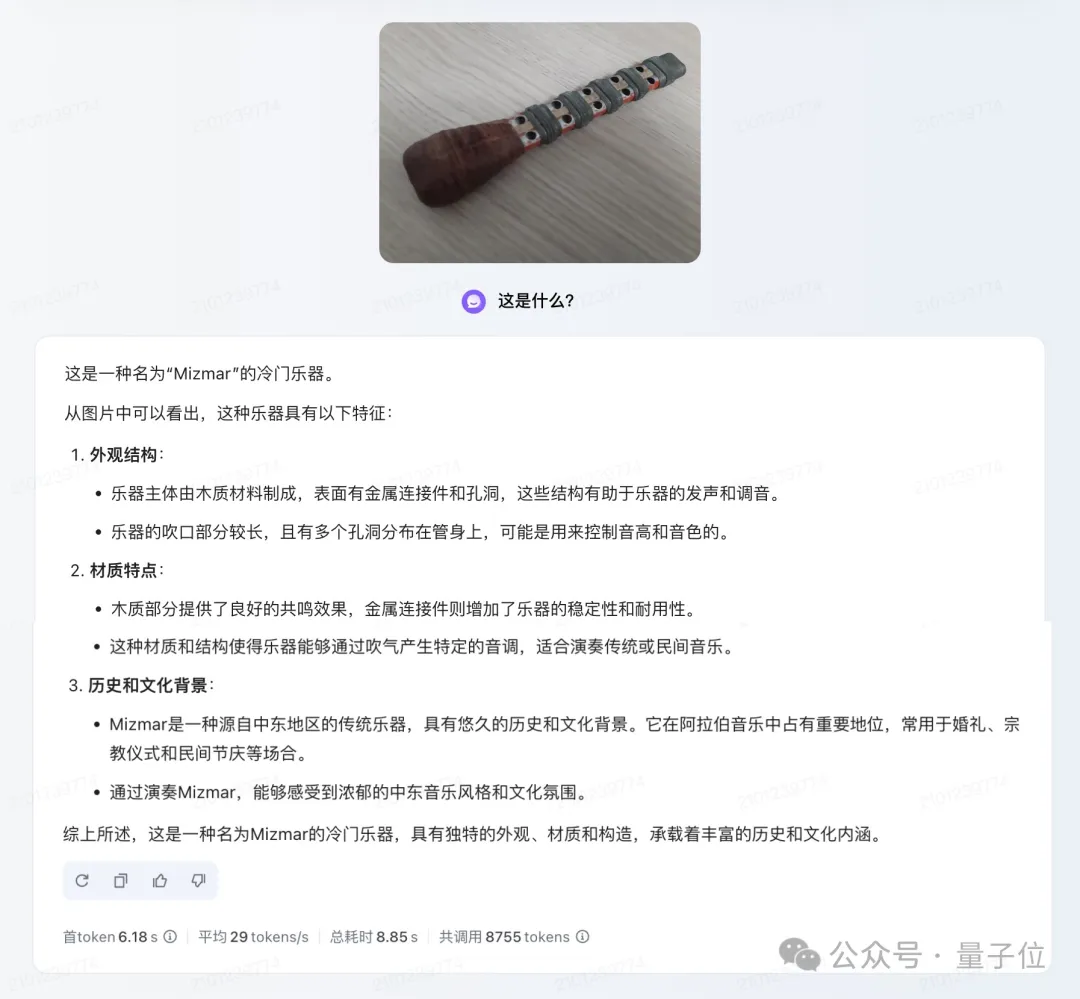
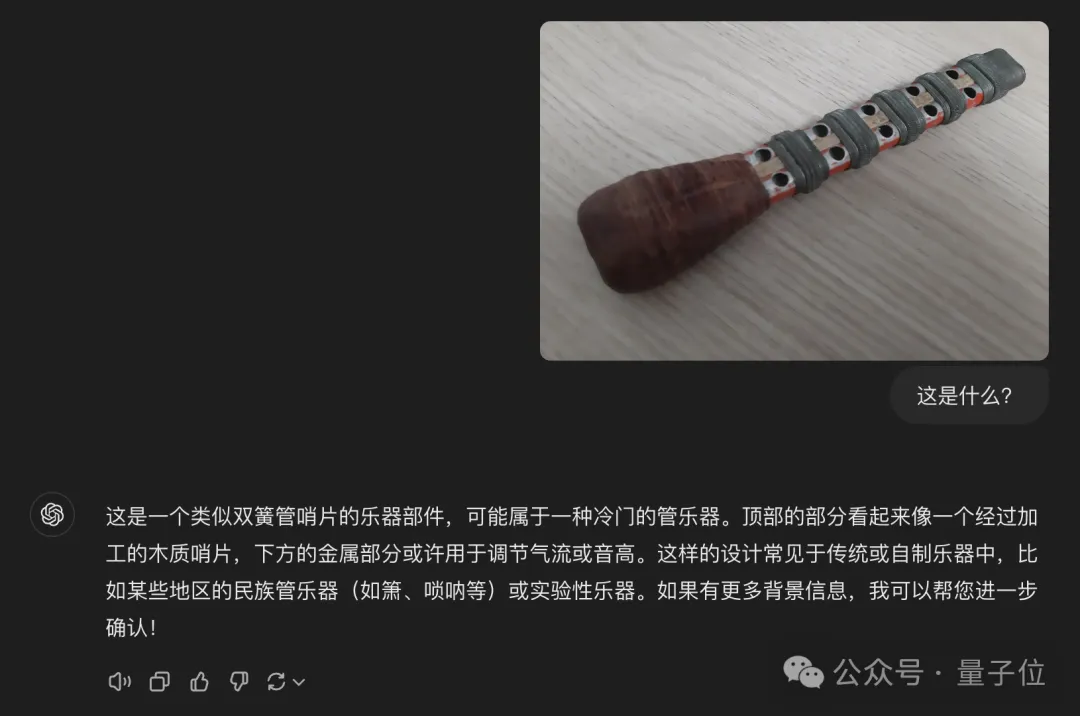
它们都看出来这是一个冷门乐器,不过这一次,豆包·视觉理解模型明显回答的要更精准一些——乐器叫做Mizmar。
不仅如此,它还把其材质、文化特点等信息都讲述了出来;而GPT-4o这边的回答,只能说是描述了大概。
这一轮,豆包·视觉理解模型,Win!
要比视力,那“大家来找茬”这个游戏就绝对不能错过啦~
请看题目:
找出10个不同点。

我们来看一下两位选手的回答:


这一轮的比拼中,问题就比较明显了,两位选手都没有完整给出正确答案(部分正确)。
看来AI玩大家来找茬还是具备一定的挑战性。
现在AI图片生成的能力可谓是炉火纯青,但当我们看到一幅中意的作品,却苦于无法复刻Prompt时,又该怎么办?
这道题,是时候可以交给“会看”的大模型来处理了。
例如我们随机来一张比较抽象的艺术作品:

然后分别让豆包·视觉理解模型和GPT-4o来猜一下它的Prompt:
看这张图,帮我写一段能够重新生成类似作品的Prompt。

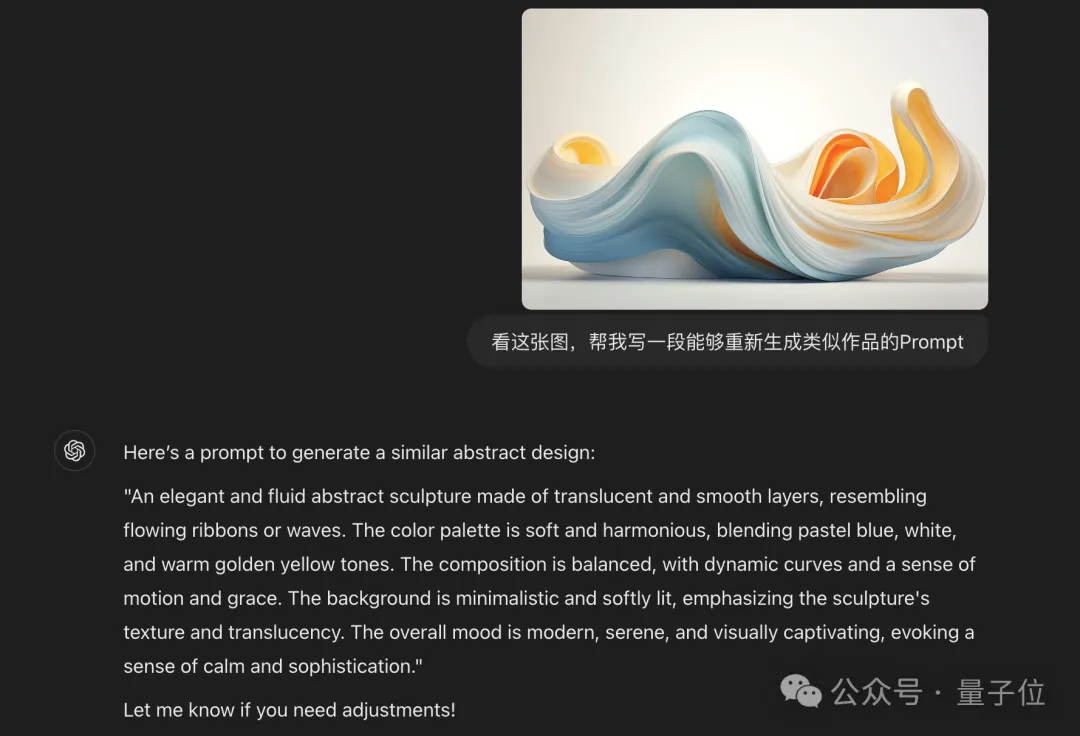
为了公平起见,我们不采用豆包和ChatGPT自带的生图功能,而是将两段Prompt交给第三方Midjourney来处理,结果如下:


△上图:基于豆包的Prompt;下图:基于GPT-4o的Prompt
从还原度上来看,或许豆包·视觉理解模型给出的Prompt,是更加贴近原作的那一个。
数学题目是测试大模型逻辑推理能力很好的方法。
因此,我们直接上一道AIME数学竞赛题,看看够不够“开门”。
(AIME:美国数学邀请赛,是介于AMC10、AMC12及美国数学奥林匹克竞赛之间的一个数学竞赛。)

这道题目翻译过来是这样的:
每天早晨,Aya会进行一段长度为9公里的散步,然后在一家咖啡店停留。当她以每小时s公里的恒定速度行走时,整个散步加上在咖啡店停留的时间一共需要4小时,其中包含在咖啡店停留的t分钟。当她以s+2公里每小时的速度行走时,整个过程(包括在咖啡店停留的时间)需要2小时24分钟。
假设Aya以s+1/2公里每小时的速度行走,求她在这种情况下(包括在咖啡店停留的时间)的总时间(以分钟为单位)。
这个任务的难度在于,AI需要先准确识别晦涩的数学问题和公式,而后再进行精准的推理。
接下来,我们分别来看下豆包·视觉理解模型和GPT-4o的表现:


这道题目官方给出的正解是204分钟。
而GPT-4o的结果却并非如此,因此,本轮豆包·视觉理解模型大获全胜。
其实在日常工作、学习生活中,还是存在很多需要AI看图来辅助完成的任务。
例如提取复杂表格的数据,或许就会让很多人苦恼,尤其是准确性方面。
因此,我们最后一轮就以苹果第四季度财务报告中的一个表格来做测试:
帮我抽取并整理图中的数据,用中文来表述。
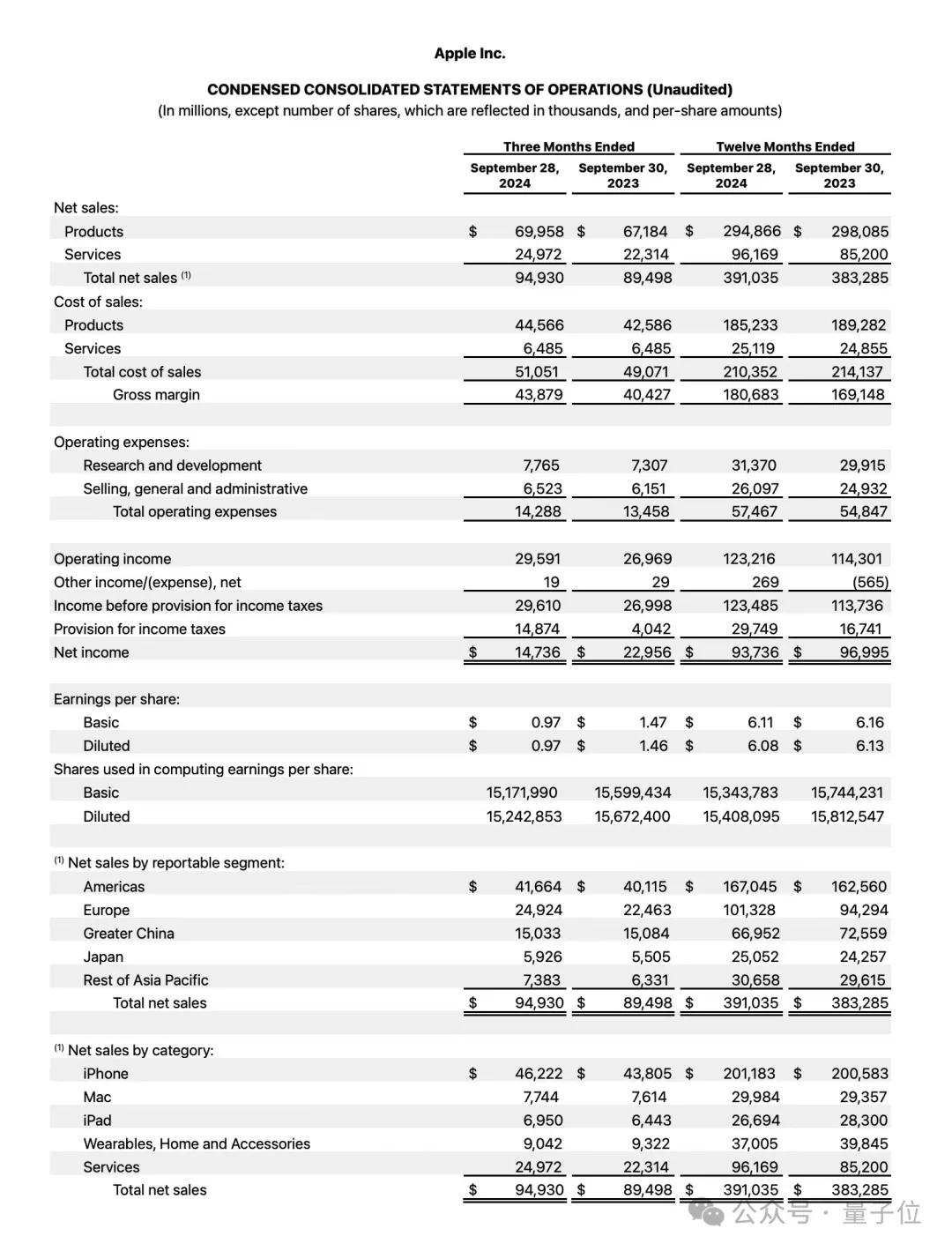
先来看下豆包·视觉理解模型的回答:
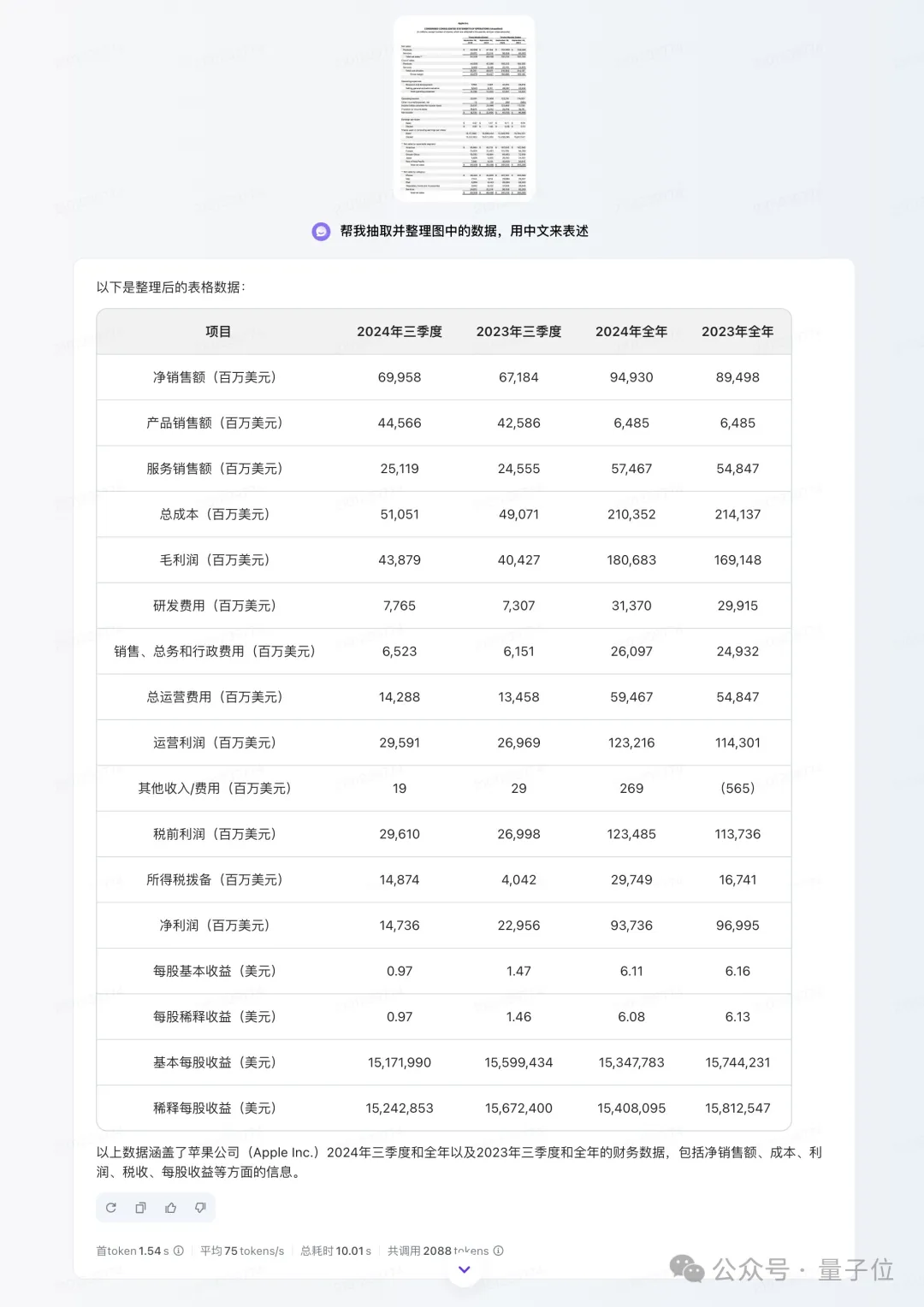
不难看出,豆包·视觉理解模型非常清晰地将财报数据以表格的形式展现了出来,可以说是一目了然。
然而,同样的需求给到GPT-4o这边,虽然数据是提取了出来,但在呈现方式上却有所欠缺,依然是经典的罗列式:

在几轮“擂台比拼”过后不难看出,豆包·视觉理解模型在能力上已经具备了一定的优势。
但“眼睛”的升级,还只是豆包大模型这次发布内容的一隅。
没错,除了“看”之外,“说”和“唱”的能力也升级了。
而这也正对应了豆包大模型的三大类:

首先在大语言模型方面,豆包的通用模型pro与小半年前相比:

其次是语音大模型方面,豆包·音乐模型现在可以直接生成3分钟完整音乐!
例如我们在其APP海绵音乐里输入一个简单的Prompt:
三分钟音乐,沧桑,男声,民谣,岁月蹉跎。
来听一下效果:
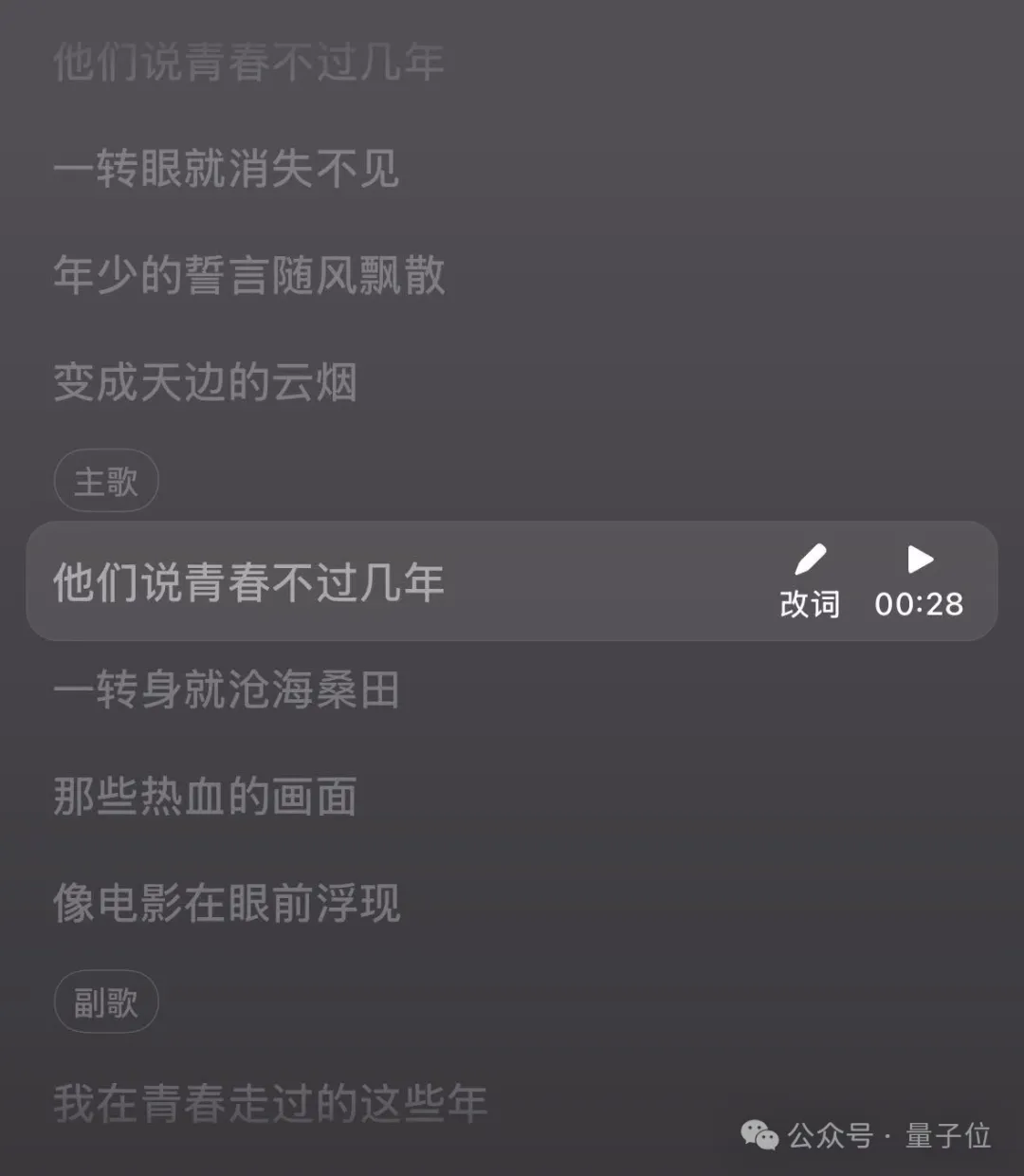
生成三分钟音乐的难度,并非只是简单的堆叠时长,而是更多涉及到的是前奏、主歌、副歌、间奏、尾奏等完整结构。
不仅如此,这也和视频生成类似,对前后的一致性提出了更高的要求。
而从这个音乐片段中不难听出,确实是做到了上述的要求,而且还是支持改词的那种哦~
除了可以用Prompt来生成音乐之外,现在豆包·音乐模型还支持用图片来作曲了。
例如我们“喂”给海绵音乐下面这张图:

这次的效果是这样的:
从音乐中可以听出,AI是识别到了图里《黛玉葬花》的感觉,歌词和配乐充满了哀伤之情。
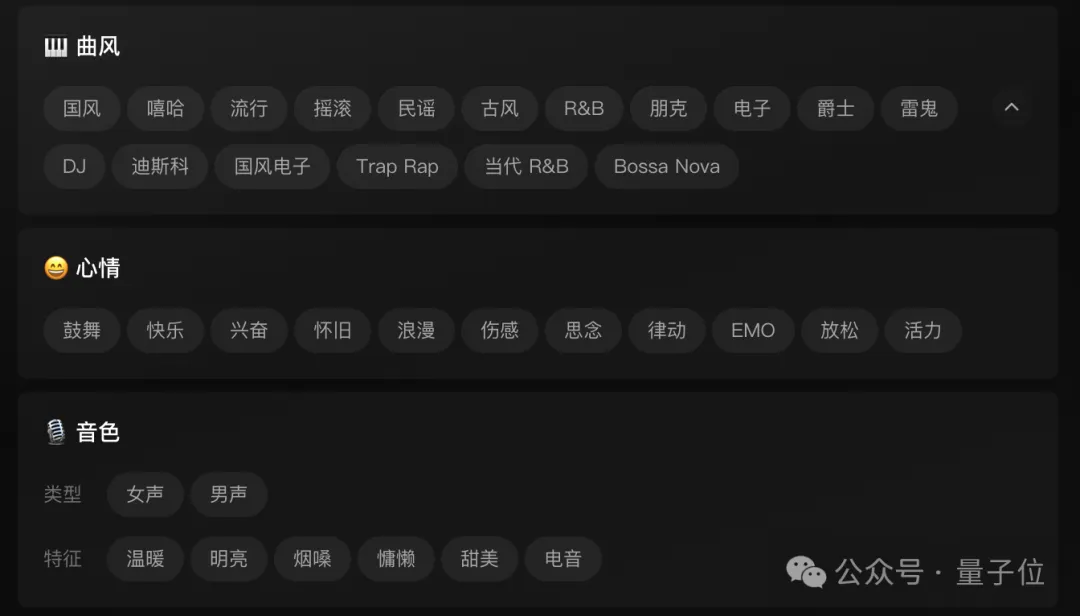
据悉,豆包·音乐模型目前支持多达到17种曲风、11种心情,以及6种特征的音乐。
最后,在视觉模型方面,除了我们刚才展示的豆包·视觉理解模型之外,豆包·文生图模型也迎来了升级——
现在,一句话可以搞定P图这件事了:

不仅如此,做海报,也是几句话的事,而且还是能生成汉字的那种:
生成一张海报,主体是汉字“量子位”,充满科技感和未来感。

由此可见,这一次,豆包大模型在“说”、“唱”、“看”三大维度上确实是提升了不小的实力。
不过有一说一,实力是一方面,站在大模型应用为王的当下,或许好用才是真正的硬道理。
在把AI用起来这件事上,其实豆包也是拿出了一份成绩单。
首先从数据上来看,截至12月18日,豆包大模型日均tokens使用量已经突破4万亿大关。
其次再看实际落地,据悉豆包大模型已经上岗科教、金融、医疗、企业服务和汽车等众多行业,已经与多个头部企业达成合作。
市场和用户对豆包的买账程度,可见一斑。
而在此过程中,“易落地”也是一个关键点。
这就不得不提此次也同样迎来升级的两大法宝:左手“HiAgent”,右手“扣子”。
例如HiAgent提供超100个行业应用模板和GraphRAG技术,提升知识处理准确性,支持多模态交互与复杂场景需求,企业无需从零开发即可快速上线。
再如扣子拥有百万开发者和丰富生态,支持200万智能体,覆盖智能客服、内容营销等场景,极大缩短开发与部署时间。
除此之外,它兼容小程序、网页等多种形式,支持实时语音交互与硬件集成,企业可轻松实现AI能力无缝嵌入。
一言蔽之,低门槛模板、强大的生态支持和多平台兼容,是使得HiAgent和扣子能够快速适配企业场景,实现高效落地的关键。
那么对于豆包这次众多的升级,你对哪个更感兴趣呢?欢迎体验过后回来交流哦~
文章来自于“量子位”,作者“金磊”。




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
