

ChatGPT惨败Llama!MIT官宣AI开飞船0%失败率,马斯克火星殖民不再是梦
ChatGPT惨败Llama!MIT官宣AI开飞船0%失败率,马斯克火星殖民不再是梦MIT最新研究让LLM直接操控宇宙飞船进行太空追逐挑战赛:ChatGPT少量微调即获第二,开源Llama更胜一筹,凭提示词精准追踪卫星、节省燃料,更是0%失败率,验证AI小数据高效与自主航天可行,为未来的太空漫游铺路。
来自主题: AI技术研报
6350 点击 2025-07-03 11:48
MIT最新研究让LLM直接操控宇宙飞船进行太空追逐挑战赛:ChatGPT少量微调即获第二,开源Llama更胜一筹,凭提示词精准追踪卫星、节省燃料,更是0%失败率,验证AI小数据高效与自主航天可行,为未来的太空漫游铺路。

Claude Code推出了一个让人眼前一亮的功能——Hooks。
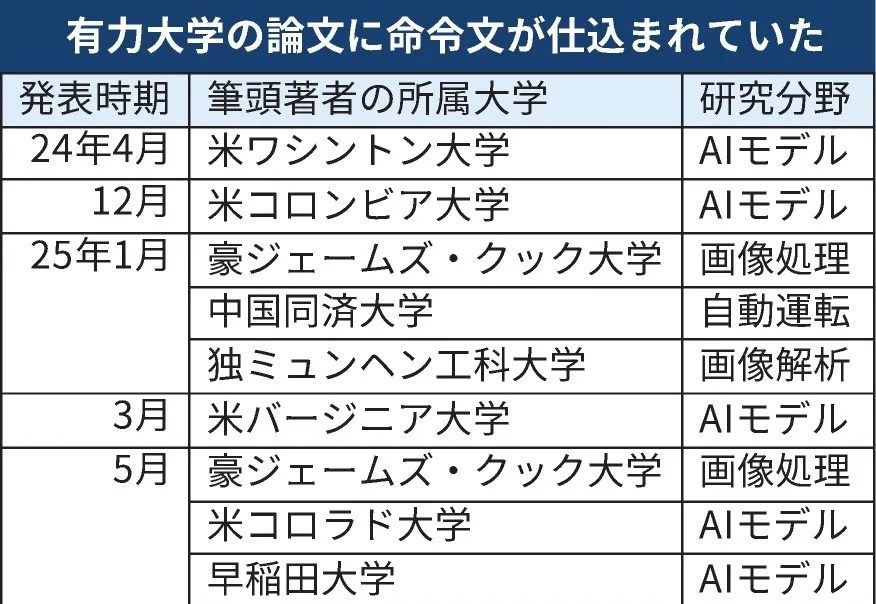
是「正当防卫」还是「学术欺诈」?

原来,CoT推理竟是假象!Bengio带队最新论文戳穿了CoT神话——我们所看到的推理步骤,并非是真实的。不仅如此,LLM在推理时会悄然纠正错误,却在CoT中只字未提。
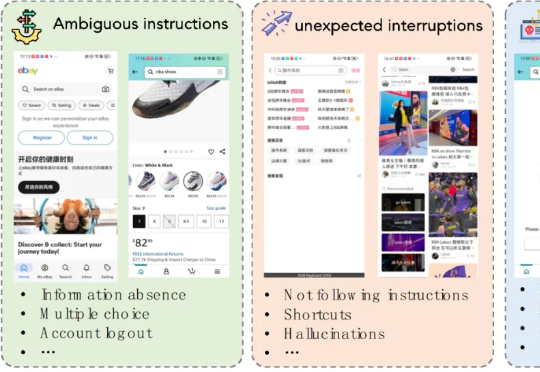
本文第一作者是上海交通大学计算机学院三年级博士生程彭洲,研究方向为多模态大模型推理、AI Agent、Agent 安全等。通讯作者为张倬胜助理教授和刘功申教授。
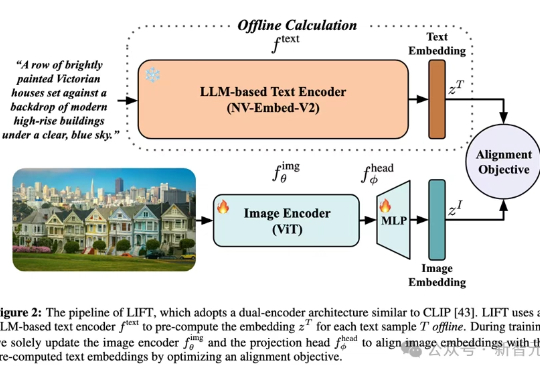
多模态对齐模型借助对比学习在检索与生成任务中大放异彩。最新趋势是用冻结的大语言模型替换自训文本编码器,从而在长文本与大数据场景中降低算力成本。LIFT首次系统性地剖析了此范式的优势来源、数据适配性、以及关键设计选择,在组合语义理解与长文本任务上观察到大幅提升。

设定角色,让AI照“本”生成主角不变的不同图像,对于各路AIGC工具来说一直是不小的挑战。
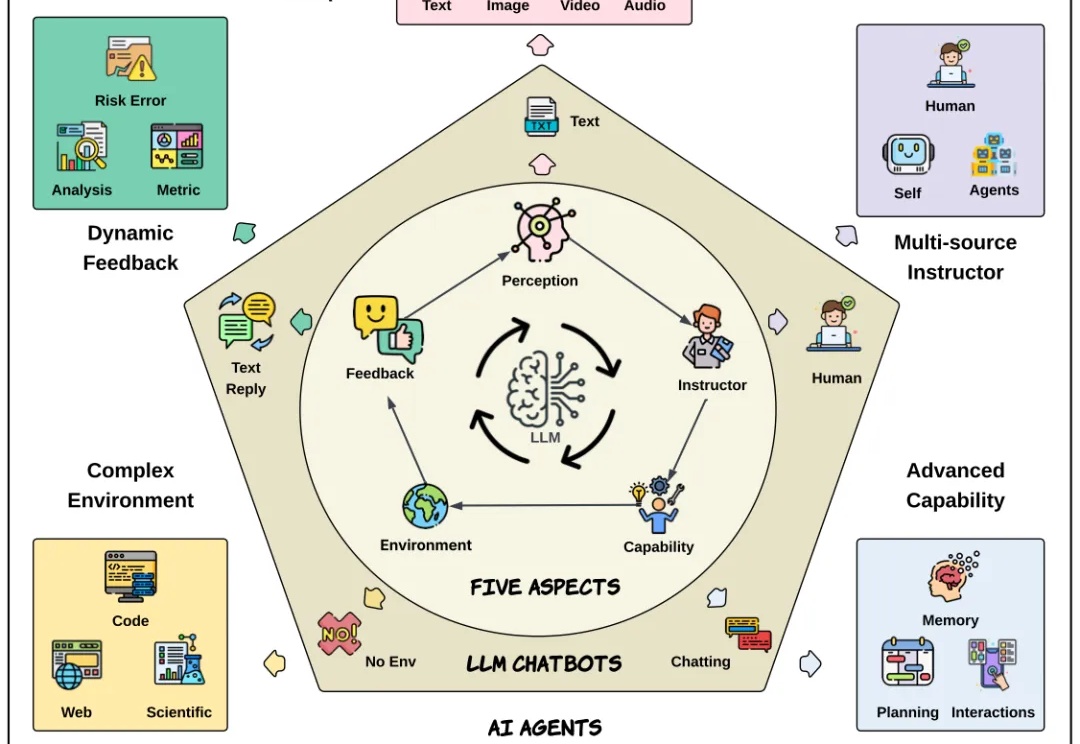
自从 Transformer 问世,NLP 领域发生了颠覆性变化。大语言模型极大提升了文本理解与生成能力,成为现代 AI 系统的基础。而今,AI 正不断向前,具备自主决策和复杂交互能力的新一代 AI Agent 也正加速崛起。
大家好,这里是歸藏(guizang),分享一下 Gemini CLI 不写代码能有多好用! 前几天最近随着 Claude Code 这个命令行 AI 代码工具的火爆,谷歌也耐不住寂寞推出了自己的同类产品 Gemini CLI,而且完全免费,非常顶。
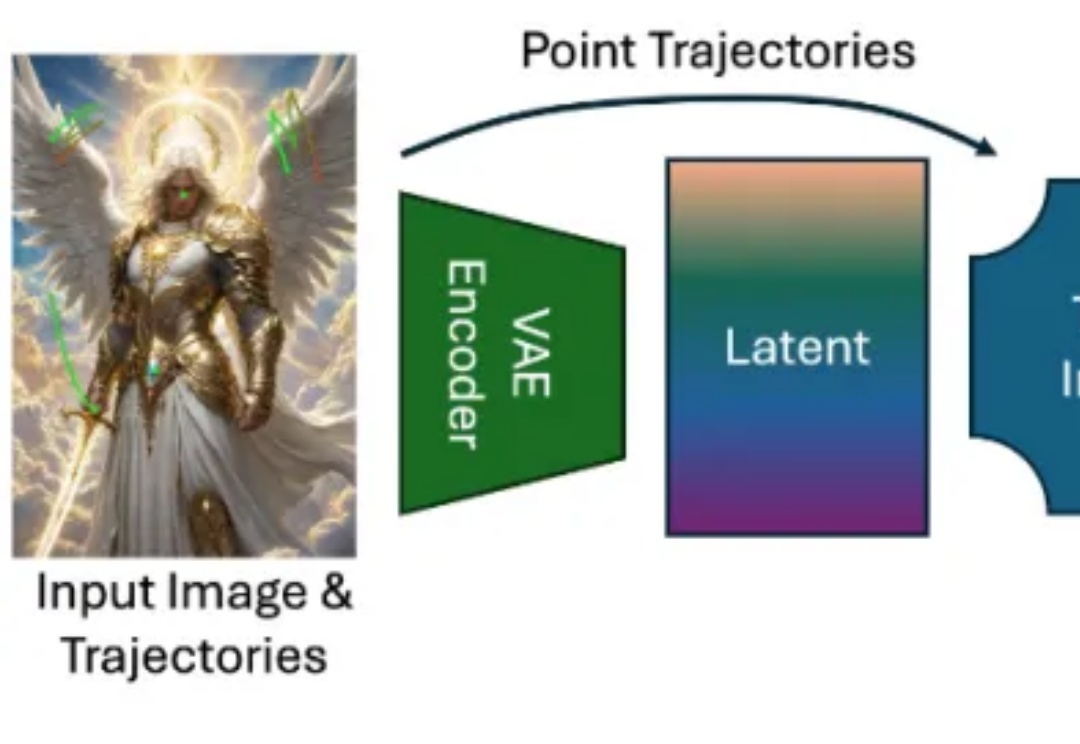
近年来,随着扩散模型(Diffusion Models)、Transformer 架构与高性能视觉理解模型的蓬勃发展,视频生成任务取得了令人瞩目的进展。从静态图像生成视频的任务(Image-to-Video generation)尤其受到关注,其关键优势在于:能够以最小的信息输入生成具有丰富时间连续性与空间一致性的动态内容。
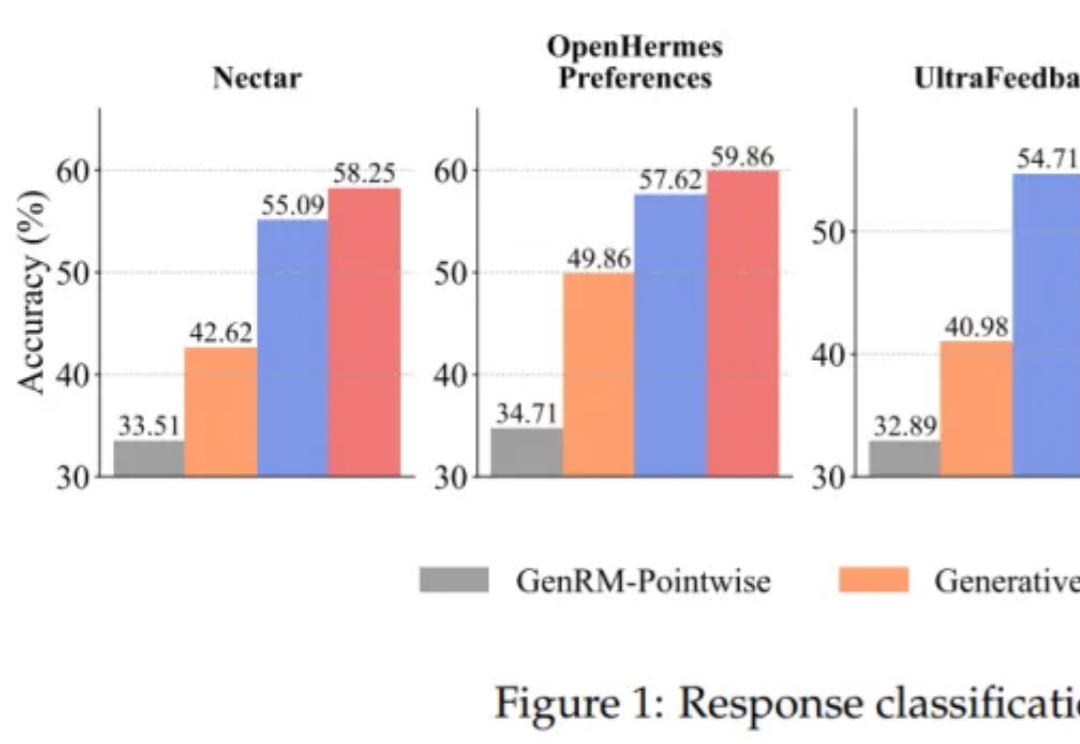
将大语言模型(LLMs)与复杂的人类价值观对齐,仍然是 AI 面临的一个核心挑战。当前主要的方法是基于人类反馈的强化学习(RLHF)。该流程依赖于一个通过人类偏好训练的奖励模型来对模型输出进行评分,最终对齐后的 LLM 的质量在根本上取决于该奖励模型的质量。

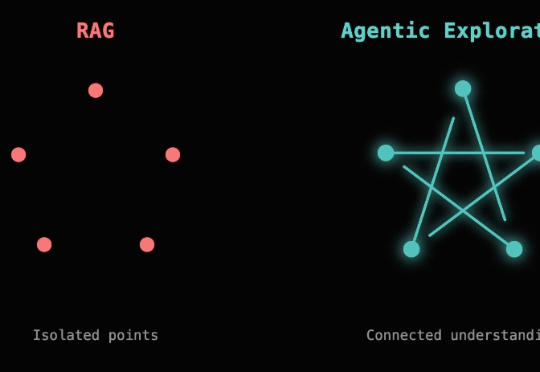
2023年至今,检索增强生成(RAG)经历了从备受瞩目到逐渐融入智能体生态的转变。尽管有人宣称“RAG已死”,但其在企业级应用中的重要性依然无可替代。RAG正从独立框架演变为智能体生态的关键子模块,2025年将在多模态、代理融合、行业定制化等领域迎来新的突破。
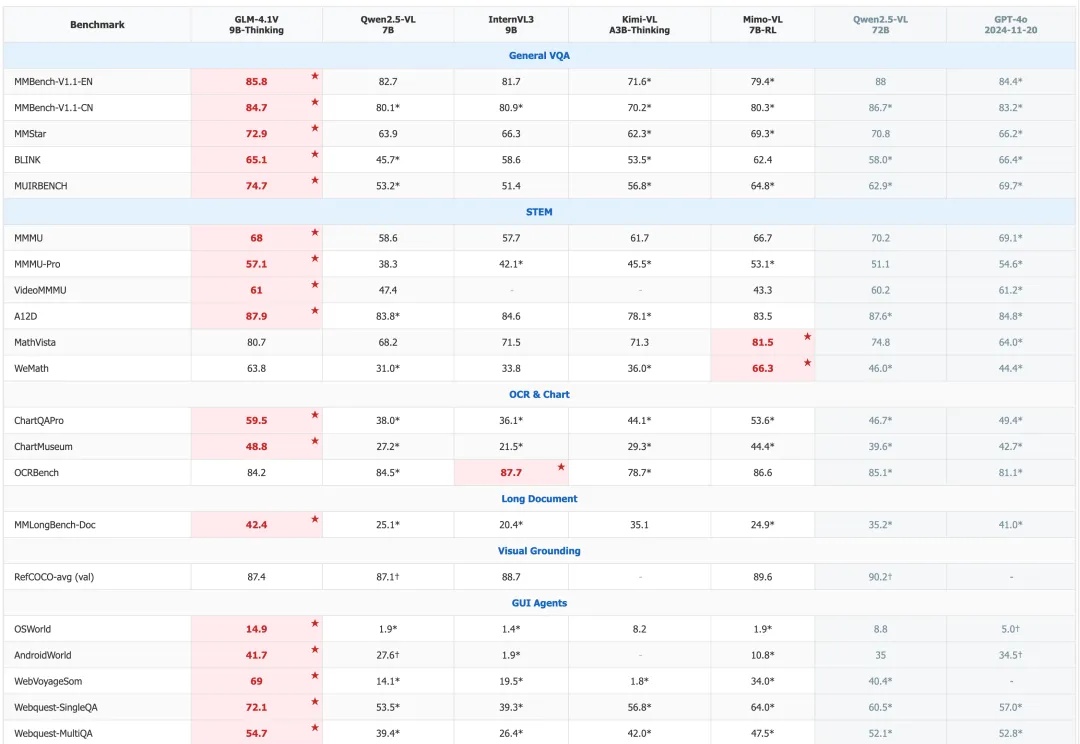
如果一个视觉语言模型(VLM)只会“看”,那真的是已经不够看的了。
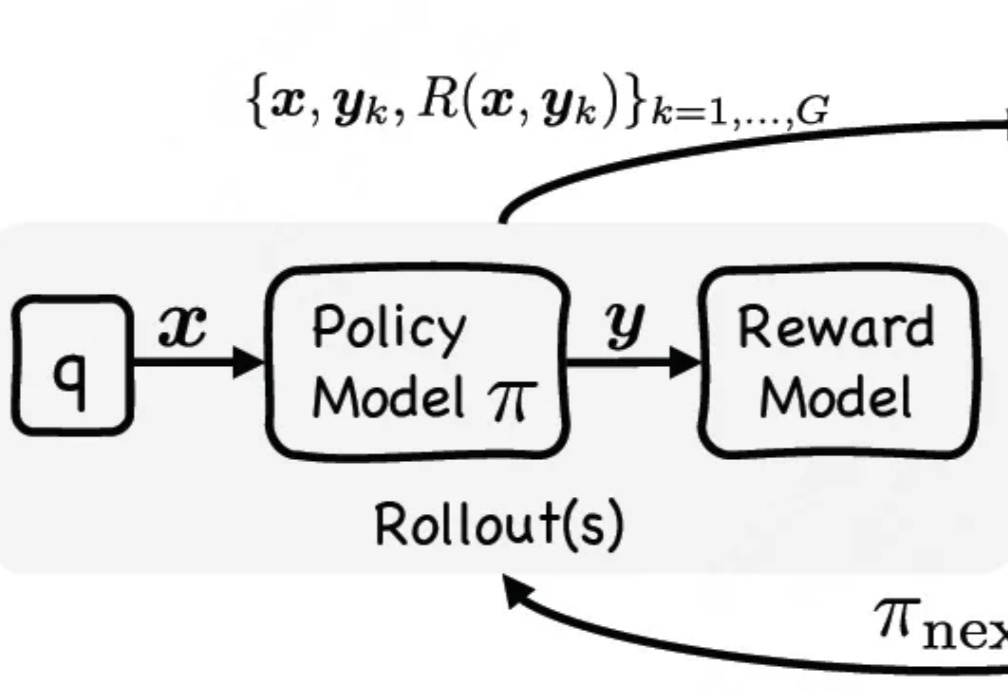
通过单阶段监督微调与强化微调结合,让大模型在训练时能同时利用专家演示和自我探索试错,有效提升大模型推理性能。
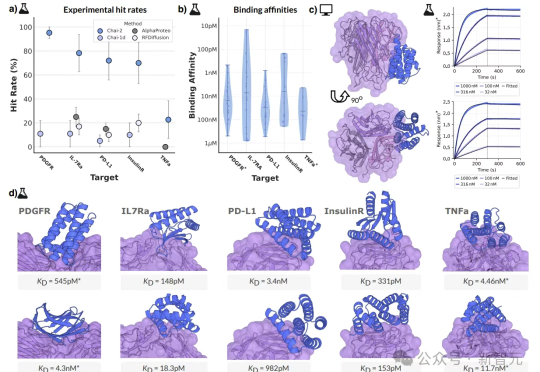
10元一块实验板、2周时间、零样本命中率16%,这不是科幻,而是AI创造的生物技术奇迹!AI制药的拐点,或许已经到来——如果还在用老方法,那你可能已经被这场「淘汰赛」边缘化了……
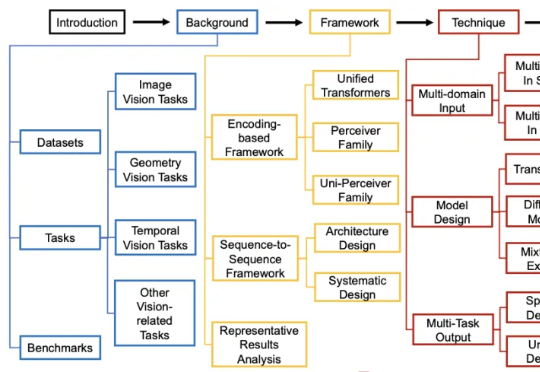
过去几年,通用视觉模型(Vision Generalist Model,简称 VGM)曾是计算机视觉领域的研究热点。
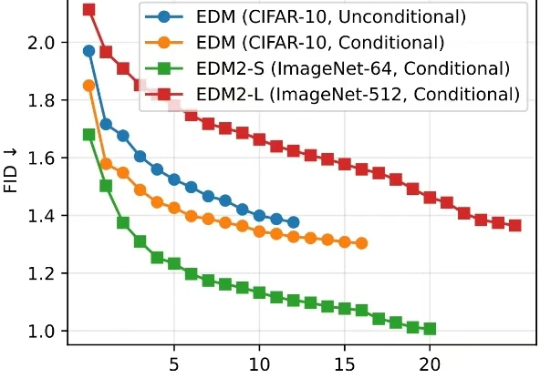
清华大学朱军教授团队与 NVIDIA Deep Imagination 研究组联合提出一种全新的视觉生成模型优化范式 —— 直接判别优化(DDO)。

几个月前,Anthropic 的办公室里多了一台很奇怪的自动售货机。
这两天读到开源的代码 Agent,Cline 团队的一篇博客,《Why Cline Doesn't Index Your Codebase (And Why That's a Good Thing) 》,做了一些整理和探索,来分享一下这篇博客内容。
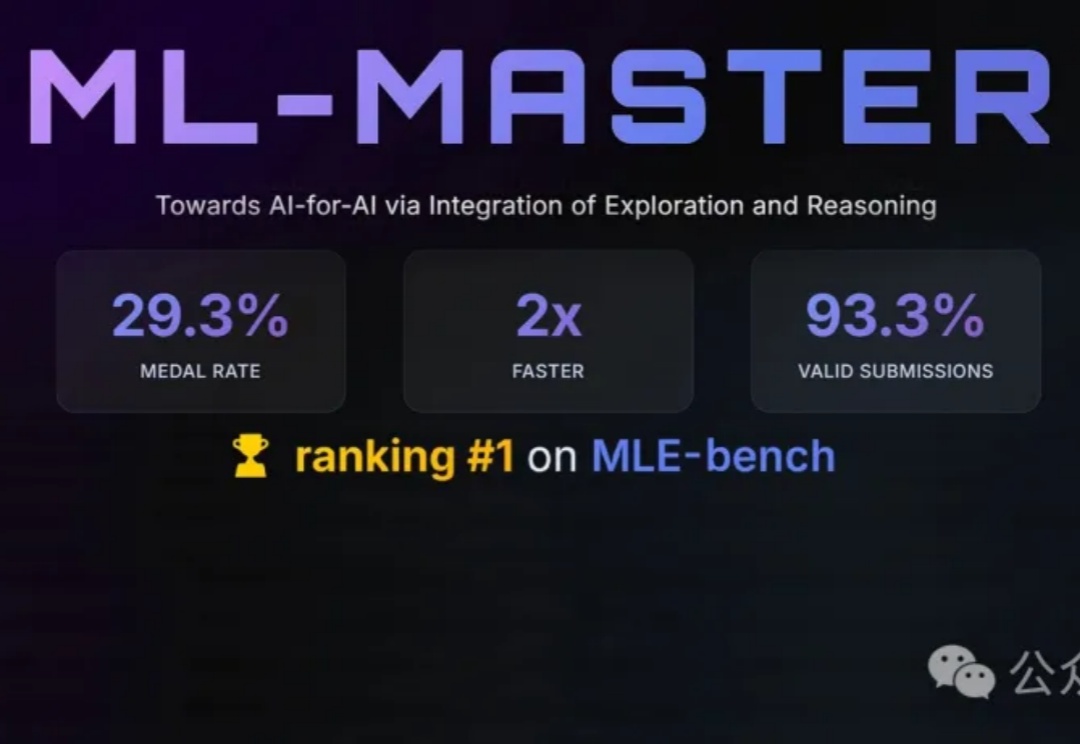
刚刚,由上海交通大学人工智能学院Agents团队提出的AI专家智能体,在OpenAI权威基准测试MLE-bench中击败了业界AI顶流微软,夺冠登顶!
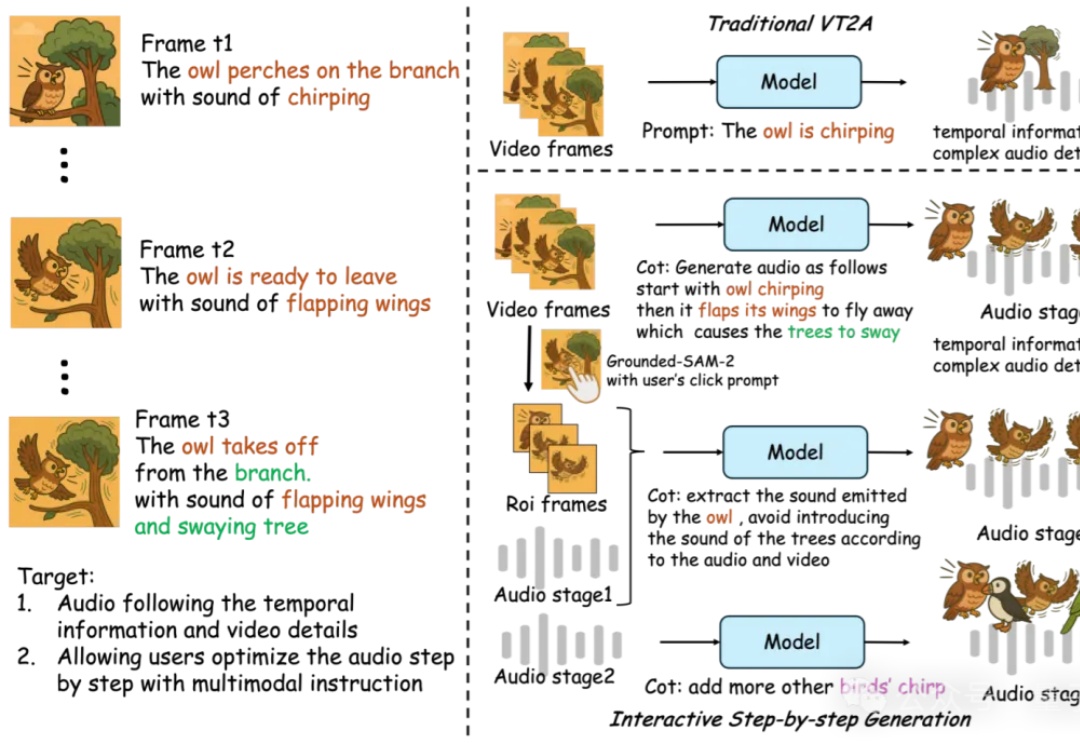
AI音效已经进化成这样了吗??
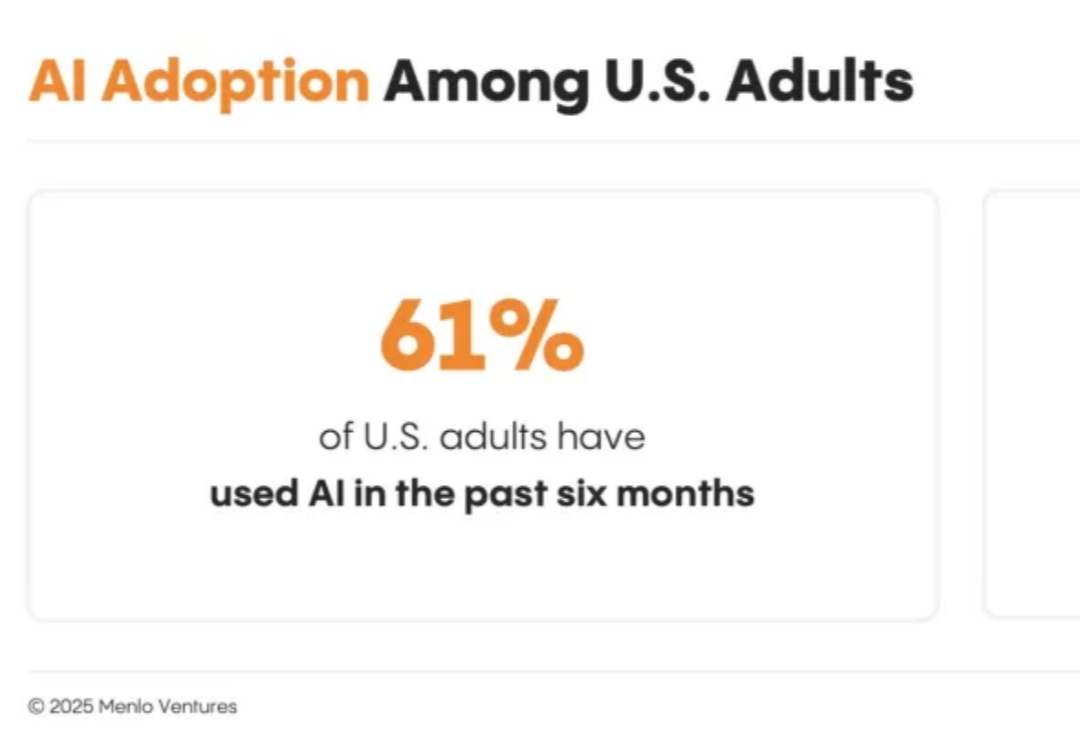
用户究竟是如何使用AI的? Menlo Ventures是一家硅谷老牌的风险投资公司,专注于消费者、企业和生命科学领域,曾投资了Uber、Siri、Tumblr等知名公司。

从撒谎到勒索,再到暗中自我复制,AI 的「危险进化」已不仅仅是科幻桥段,而是实验室里的可复现现象。

为什么AI生成的视频总是模糊卡顿?为什么细节纹理经不起放大?为什么动作描述总与画面错位?

几十年来,人工智能领域一直在思考一个看似简单但非常根本的问题: 如果一个智能体要在真实世界中行动、规划,并且和环境互动,它需要一个怎样的「世界模型」?
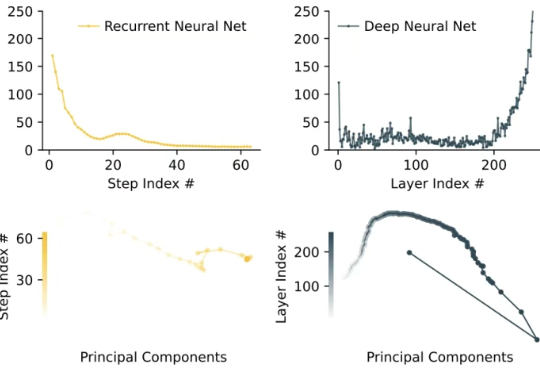
像人一样推理。 大模型的架构,到了需要变革的时候? 在对复杂任务的推理工作上,当前的大语言模型(LLM)主要采用思维链(CoT)技术,但这些技术存在任务分解复杂、数据需求大以及高延迟等问题。
在日常生活中,我们常通过语言描述寻找特定物体:“穿蓝衬衫的人”“桌子左边的杯子”。如何让 AI 精准理解这类指令并定位目标,一直是计算机视觉的核心挑战。
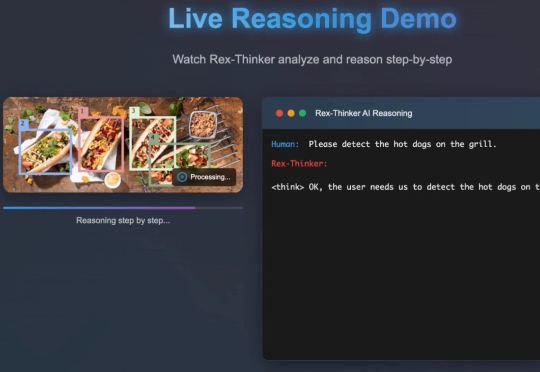
大模型可以不再依赖人类调教,真正“自学成才”啦?新研究仅通过RLVR(可验证奖励的强化学习),成功让模型自主进化出通用的探索、验证与记忆能力,让模型学会“自学”!
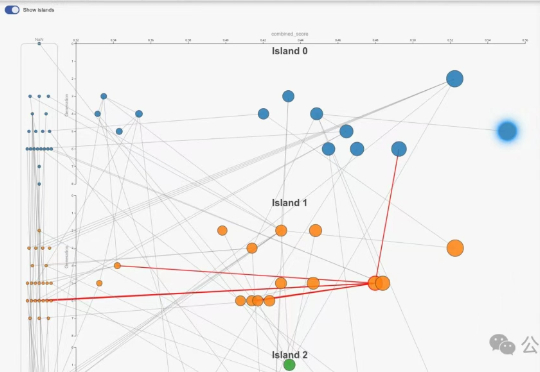
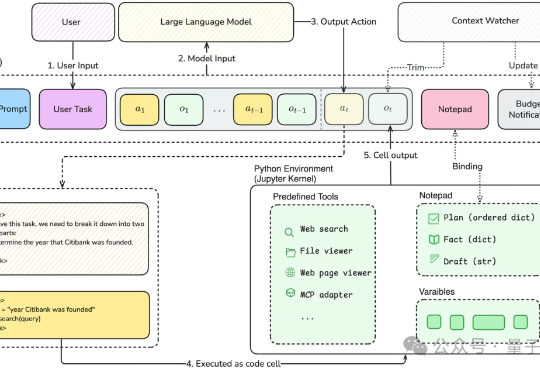
刚刚,AlphaEvolve又上大分了!基于它的开源实现OpenEvolve,靠自学成才、自己写代码,直接在苹果芯片上进化出了比人类还快21%的GPU核函数!这一刻,是自动化编程史上真正里程碑时刻,「AI为AI编程」的新时代正式开启,自动化奇点真要来了。
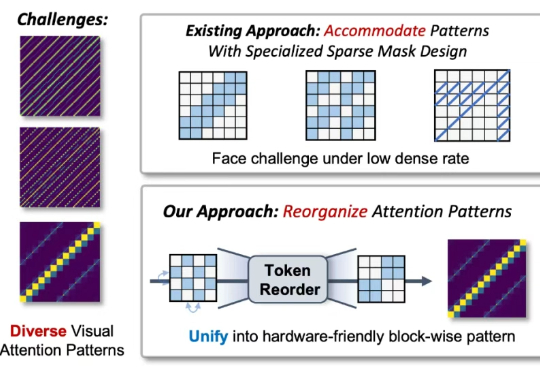
近年来,随着视觉生成模型的发展,视觉生成任务的输入序列长度逐渐增长(高分辨率生成,视频多帧生成,可达到 10K-100K)。