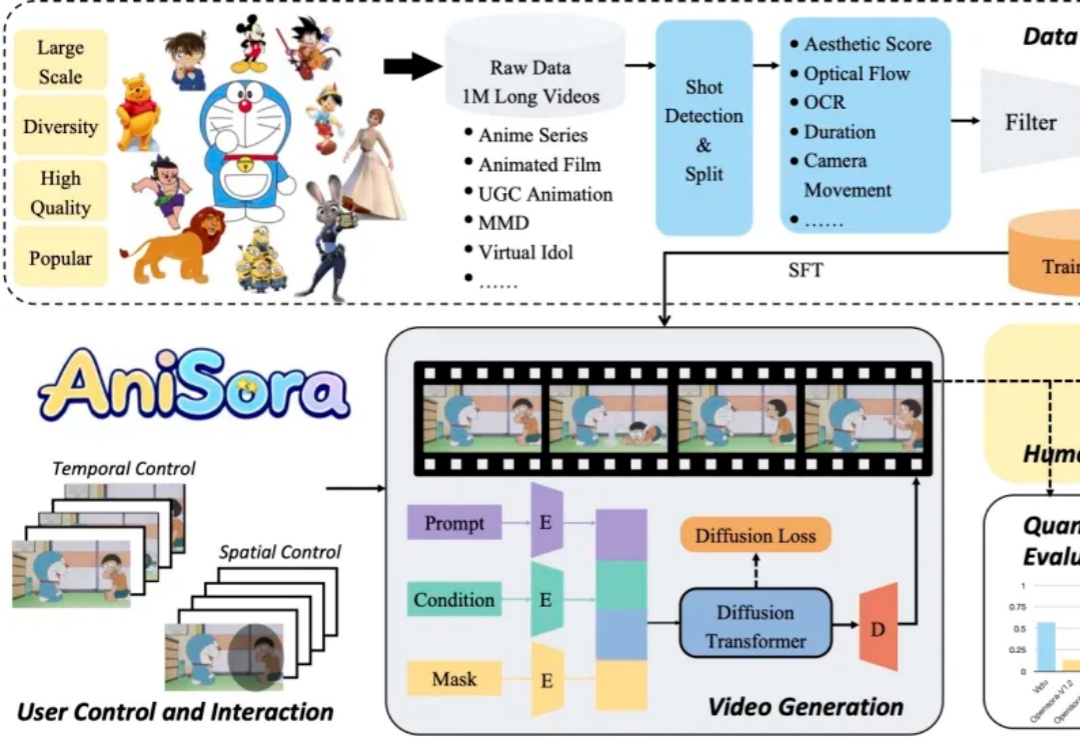
Dify、n8n、Coze、Fastgpt、Ragflow到底该怎么选?超详细指南~
Dify、n8n、Coze、Fastgpt、Ragflow到底该怎么选?超详细指南~大家好,我是袋鼠帝 一直以来,分享了不少关于工作流平台、LLM应用平台的不少干货文章。 主要包含:Dify、Coze、n8n、Fastgpt、Ragflow。大家好,我是袋鼠帝 一直以来,分享了不少关于工作流平台、LLM应用平台的不少干货文章。 主要包含:Dify、Coze、n8n、Fastgpt、Ragflow
来自主题: AI技术研报
8548 点击 2025-05-22 09:11