
牛津、英伟达等提出记忆压缩新范式:训练时让模型学会断舍离
牛津、英伟达等提出记忆压缩新范式:训练时让模型学会断舍离2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。
来自主题: AI技术研报
9915 点击 2026-06-02 11:23
 搜索
搜索
2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。
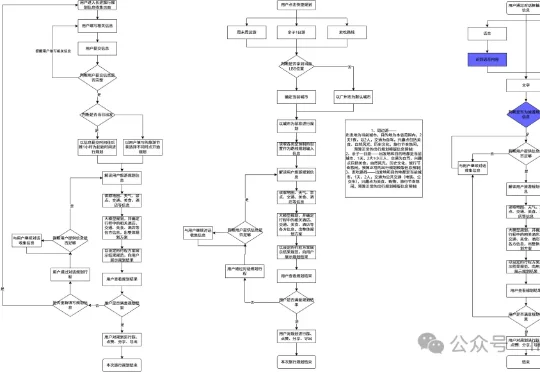
上一篇文章,和大家聊了一下这个项目,做了一个整体性的复盘,但主要是以业务和团队等方面说的,但是实现方案和大模型相关评估上,说的不多,这篇文章,我们就在产品实现方案和大模型这块来聊一下。
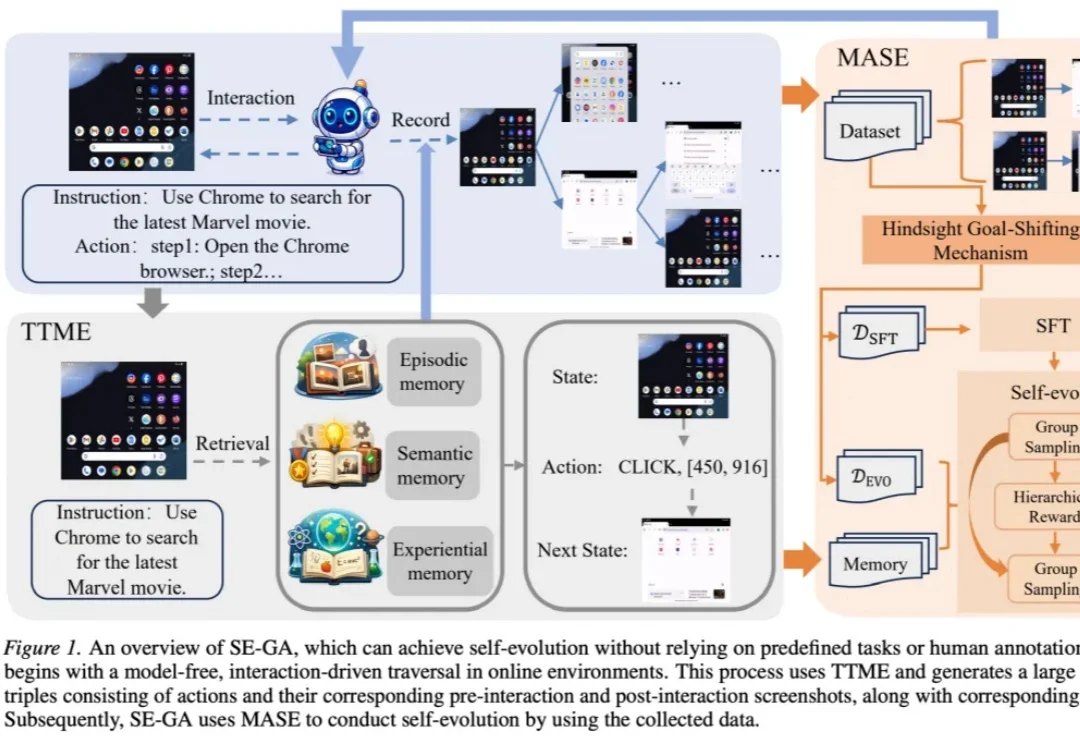
本文团队长期从事负责任的人工智能与人工智能赋能社会科学相关研究,围绕视觉生成大模型安全治理、智能体安全等方向开展系统性工作,相关成果发表于AAAI、ICML、TMM 等国际期刊与会议。

Anthropic 的老板达里奥・阿莫迪,一笑起来憨态可掬的,但做起事情来,总给人一种死脑筋的印象。

Z Potentials独家获悉,侵入式脑机接口创业公司SiClink(曦涟科技)近日连续完成数千万元种子轮和天使轮融资,蓝驰创投、高瓴创投、中科神光联合押注。
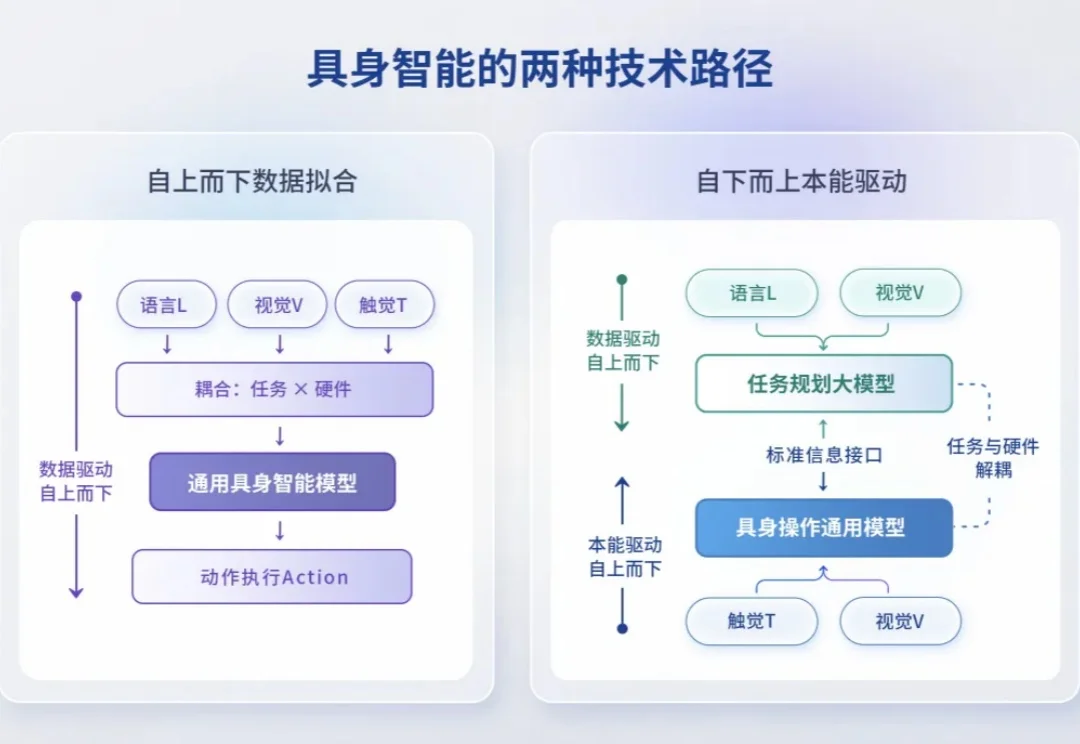
这是第一次,机器人学会了用手「盘」:
救命,只能说中国科技还是太!夯!了!现在老外来中国旅游,已经不满足于逛长城、吃火锅、看熊猫了。最新路线变成这样:深圳看无人机送外卖,杭州逛机器人公司,上海刷AI创业现场。

这一瓶颈是结构性的——这意味着每次请求都必须经过业内成本最高、功耗最大的芯片。这种低效正是总部位于韩国和美国的初创公司 XCENA 试图解决的问题。 这家成立四年的初创公司设计了一款芯片,将计算能力置于更接近 DRAM 的位置
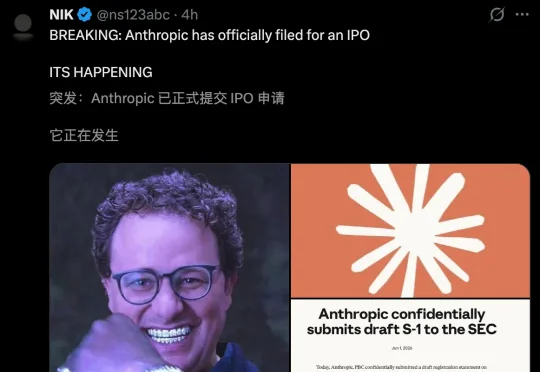
AI第一股之争,正式开打!刚刚,Anthropic秘密递交IPO申请书。就在上周,它刚以9650亿美元估值完成650亿融资,史上第一次反超OpenAI。

Mindverse 完成由美团领投的 A 轮融资,元禾璞华、韶音、变量资本和老股东追加跟投。Mindverse (心洲科技) 是少数把赌注押在模型「内部」的一家创企,它在通用大模型的基础上,用强化学习让它从复杂、多步骤的真实任务中学会如何把事做成,让模型从「知道很多」变为「能办好事」。