拿下全球最大临床数据库,微软甩出王炸模型!CEO放话:医疗才是AI最重要的赛道
拿下全球最大临床数据库,微软甩出王炸模型!CEO放话:医疗才是AI最重要的赛道官宣全球顶尖医院,微软要为AI医疗定制一款大模型!
来自主题: AI资讯
9805 点击 2026-06-05 09:55
 搜索
搜索
官宣全球顶尖医院,微软要为AI医疗定制一款大模型!
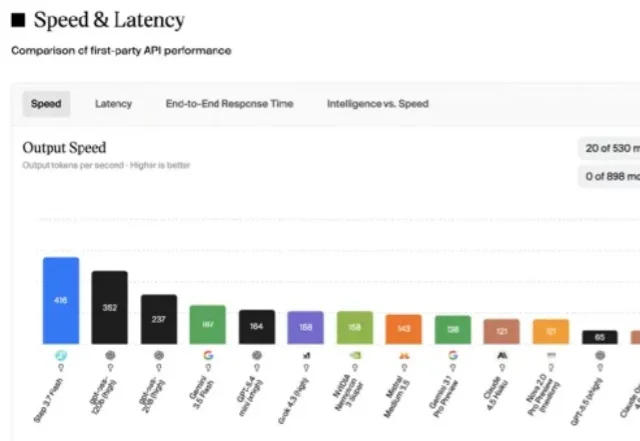
OpenRouter Trending榜单冷不丁窜出一匹国产黑马,热度暴涨稳居全球第二。

2026 AI赛道最火的概念——物理AI!
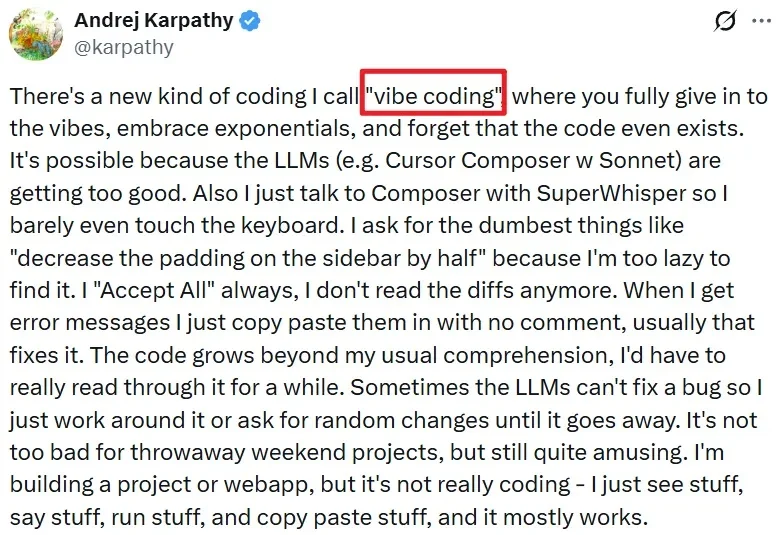
这是 Vibe Coding 的时代,这是 Vibe Working 的时代,这也是语音输入的时代……
“完全抛弃传统的代码编辑器,我直接告诉 AI 去修改代码。”

长上下文模型越来越能“记”,但真正让它们跑到线上时,最先顶不住的往往不是算力,而是KV Cache。

在ChatGPT拥有10亿用户后,AI问答这一定位,显然已经难以撑起其下一阶段的增长。另一方面,Codex每周活跃用户已超500万。很多人囿于名字,以为这是Coding产品。。。。限制了其在编程圈外的增长。

我们今天以 PDF 写论文的方式,已经持续了三百多年。然而论文其实是把一段混乱反复、充满试错的真实研究,讲成一个干净利落、足以服人的完美故事。

靠程序员发家,如今却因为AI要裁掉程序员。

8000元预算推7元玩具?AI购物或许有用,但不多。