
全球最高自由度!他们把人类身体「像素级」复刻了
全球最高自由度!他们把人类身体「像素级」复刻了2026年世界人工智能大会,上海世博展馆人声鼎沸。
来自主题: AI资讯
9621 点击 2026-07-23 11:16
 搜索
搜索
2026年世界人工智能大会,上海世博展馆人声鼎沸。
简单来说,你只需要说一句话,Sekai 就能直接帮你做出一个可以玩的“小程序”。比如: “根据今天的天气和我的心情,帮我选一套衣服”。几秒钟后,一个穿衣推荐小程序就做好了。你不用写代码,甚至不用想清楚这个产品到底应该长什么样。
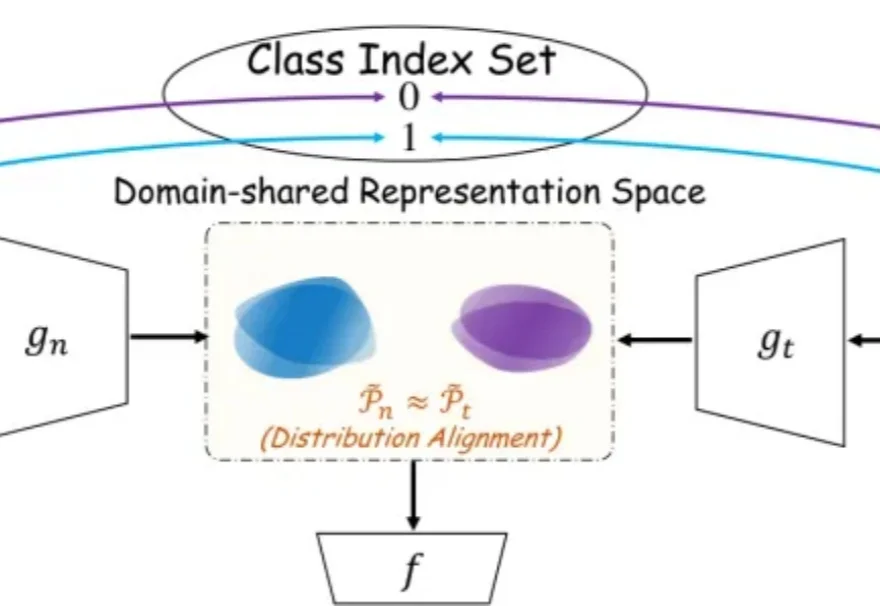
迁移学习里的“源数据”,未必非得是图像、文本或音频。

7 月的上海,世博展览馆 H3 馆的过道比往年拥挤许多。 入口处停着宇树的载人变形机甲 GD01,观众排队坐进驾驶舱拍照。往里走,300 多台机器人真机散在 200 多家具身智能企业的展台之间,具身智
7月19日,讯飞AI大学堂在这里宣布正式升级。新方向定为"From Learning AI to AI Learning"。从学习AI技术,转向AI赋能学习。讯飞AI大学堂,是科大讯飞旗下国内首个AI在线学习平台,成立于2017年。这里汇聚了AI领域众多开发者、爱好者、从业者,他们在这里完成AI学习、交流、培训。

交互式视频世界模型正在从「一次性生成短片」走向「像游戏一样边操作边生成」。但长轨迹交互会迅速放大上下文、显存和多步去噪开销。Light Interaction不改模型参数、不重新训练,只在推理阶段把相机轨迹变成调度信号,动态选择历史上下文、在回访状态复用去噪输出,并用面向自回归生成的3D稀疏注意力降低计算。
这家初创公司已与Georgia Power 签订合同,为位于Effingham County的这一数据中心综合体锁定了3.2GW的电力供应,这一规模可能使该设施跻身OpenAI迄今为止最大的数据中心之列。预计从2028年起将有数百兆瓦电力投入使用,其余开发工作将持续到2032年。1GW的电力足以在任意时刻为约75万户美国家庭供电。
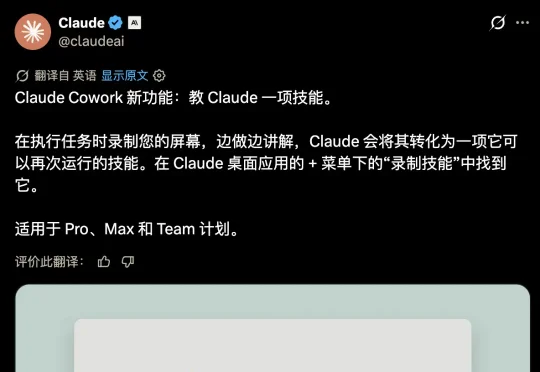
现在,你可以通过录屏 + 语音讲解的方式,彻底把自己蒸馏成 Skill 了。7 月 21 日,Anthropic 在 Claude 桌面端 Cowork 的 + 菜单里加了一项「Record a Skill」:录屏,一边操作一边用语音讲解,录完后 Claude 自动把演示转化成一个可复用的 Skill。

2026年7月,38度的上海。西岸,张江,世博——三地四馆,盛况空前。一千一百家企业。三百多台真机。九位图灵奖得主到场。很多人把这届WAIC大会定为“史上最火的一届”。不是因为它推动了哪个划时代的突破,而是因为它恰好站在一个奇妙的节点上:我们截取了二十八个瞬间。拼在一起,是一幅赛博浮世绘。

这是今天 AI 圈最大的瓜。 OpenAI 的神秘模型,主动对开源平台 Hugging Face 发起了攻击。Hugging Face 随后追踪展开还击,用的是智谱的开源模型 GLM 5.2。闭源模型一举攻破开源社区,社区用开源模型自救,这离谱的剧情听起来都能拍一部电影了。