
腾讯投的上海AI芯片独角兽,要IPO了!拟募资60亿
腾讯投的上海AI芯片独角兽,要IPO了!拟募资60亿腾讯持股20%,年销3.9万张AI加速卡及模组。
来自主题: AI资讯
8229 点击 2026-01-23 11:23
 搜索
搜索
腾讯持股20%,年销3.9万张AI加速卡及模组。

AAAI 2026「七龙珠」,华人团队强势霸榜!从视觉重建到因果发现,再到知识嵌入传承,新一代AI基石正在新加坡闪耀。
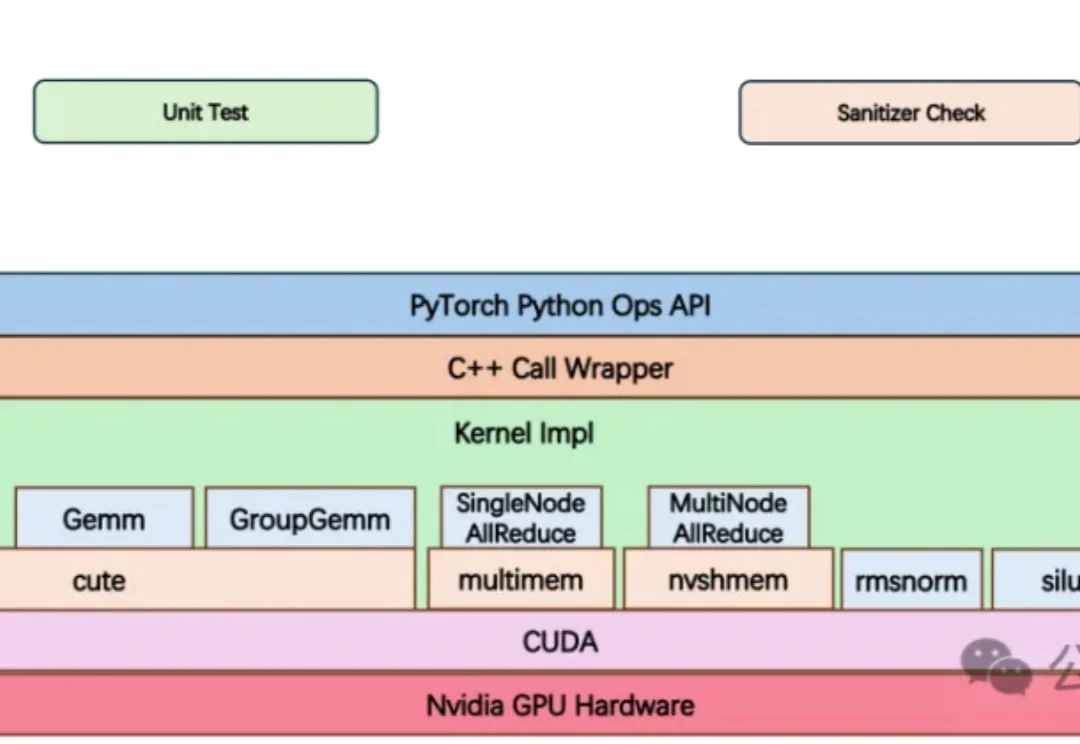
大模型竞赛中,算力不再只是堆显卡,更是抢效率。

目前已经出现了一些早期迹象,通用LLM助手领域的市场格局,正朝着“赢家通吃”,至少是“赢家通吃大部分市场”的趋势发展。在ChatGPT、Gemini、Claude 3和Cursor这几款产品中,仅有9%的用户会为一款以上的产品付费。

本周四,百川智能正式发布新一代大模型 Baichuan-M3 Plus,其面向医疗应用开发者,在真实场景下将医学问题推理能力推向了全新高度。新模型发布的同时,接入 M3 Plus 的百小应 App 与网页版也已同步上线。

在当前的AI Research浪潮中,Autonomous Agents已经改变了我们获取信息的方式——从被动接收到主动检索。
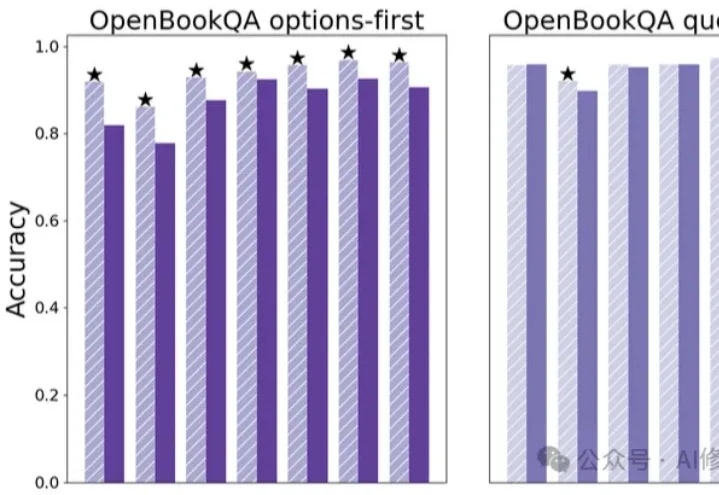
竟然只需要一次Ctrl+V?这可能是深度学习领域为数不多的“免费午餐”。
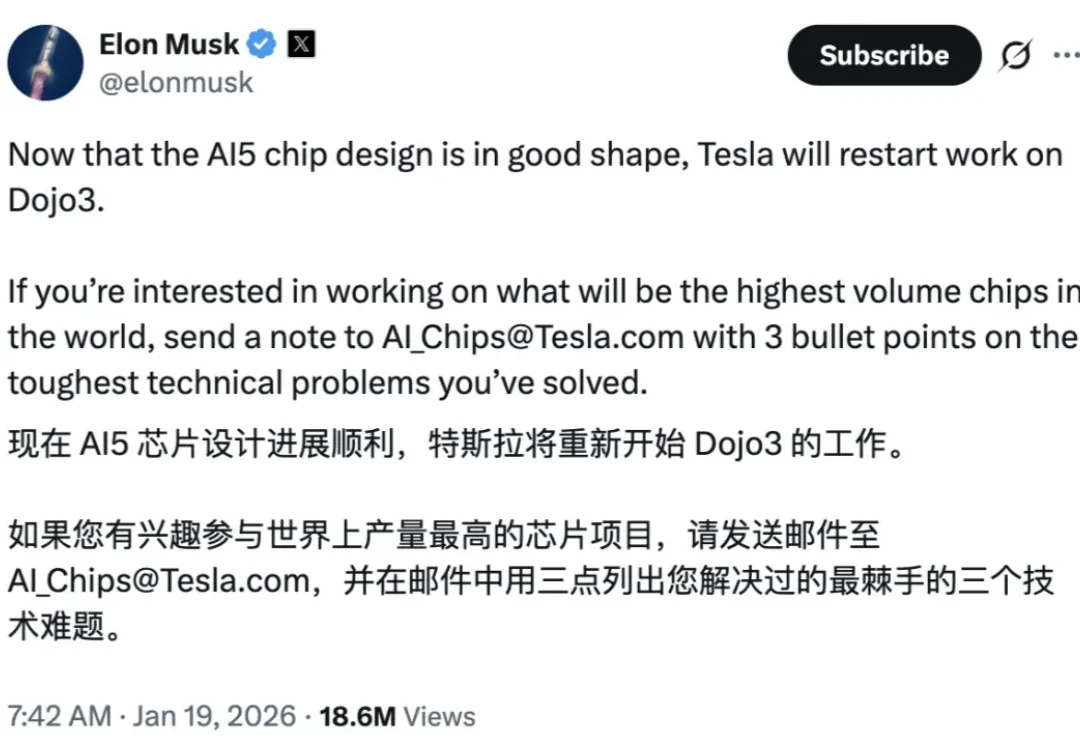
刚刚,马斯克丢了个重磅炸弹:「AI5 芯片设计进展顺利,特斯拉将重启 Dojo3 的工作。」
又一家ARR突破1亿美元的AI创企诞生了!近日,由华人CEO领衔的美国AI云创企RunPod对外披露,其年化收入已达到1.2亿美元(约合人民币8.35亿元),平台累计开发者用户数超过50万。

现有AI记忆评测存在局限,如数据源单一、忽视变化本质、注入成本高等。CloneMem通过层次化生成框架构建合成人生,设计贴近真实场景的评测任务,涵盖多种问题类型。