
不做大模型的追随者,360 选择“All In Agent",给企业叠上Al“Buff”
不做大模型的追随者,360 选择“All In Agent",给企业叠上Al“Buff”智能体元年已至,AI下半场的“生产力战争”已经打响。
来自主题: AI资讯
10617 点击 2025-12-19 11:23
 搜索
搜索
智能体元年已至,AI下半场的“生产力战争”已经打响。
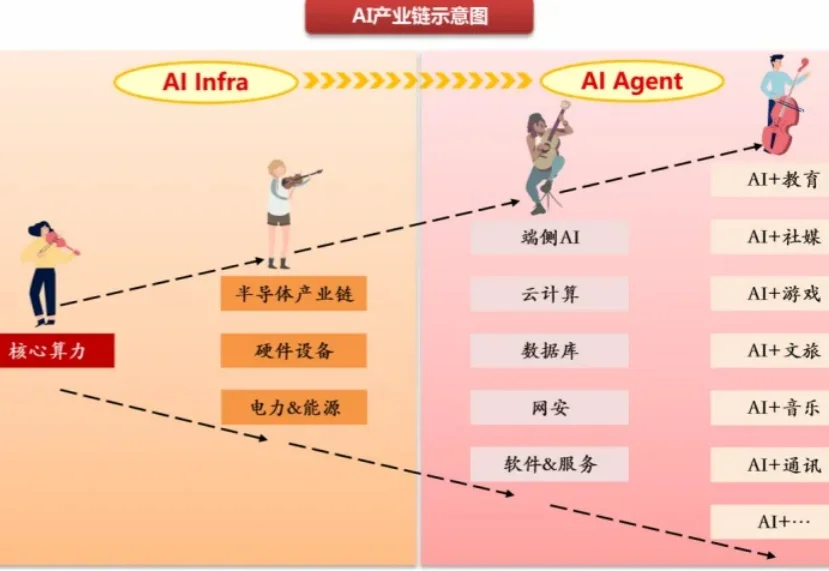
AI产业的发展遵循着典型的“基础设施→核心技术→行业应用”的科技产业化路径。当下,AI产业正在经历从“技术突破”转向“应用落地”的关键阶段。

在计算机图形学、三维视觉、虚拟人、XR 领域,SIGGRAPH 是毫无争议的 “天花板级会议”。 SIGGRAPH Asia 作为 SIGGRAPH 系列两大主会之一,每年只接收全球最顶尖研究团队的成果稿件,代表着学术与工业界的最高研究水平与最前沿技术趋势。
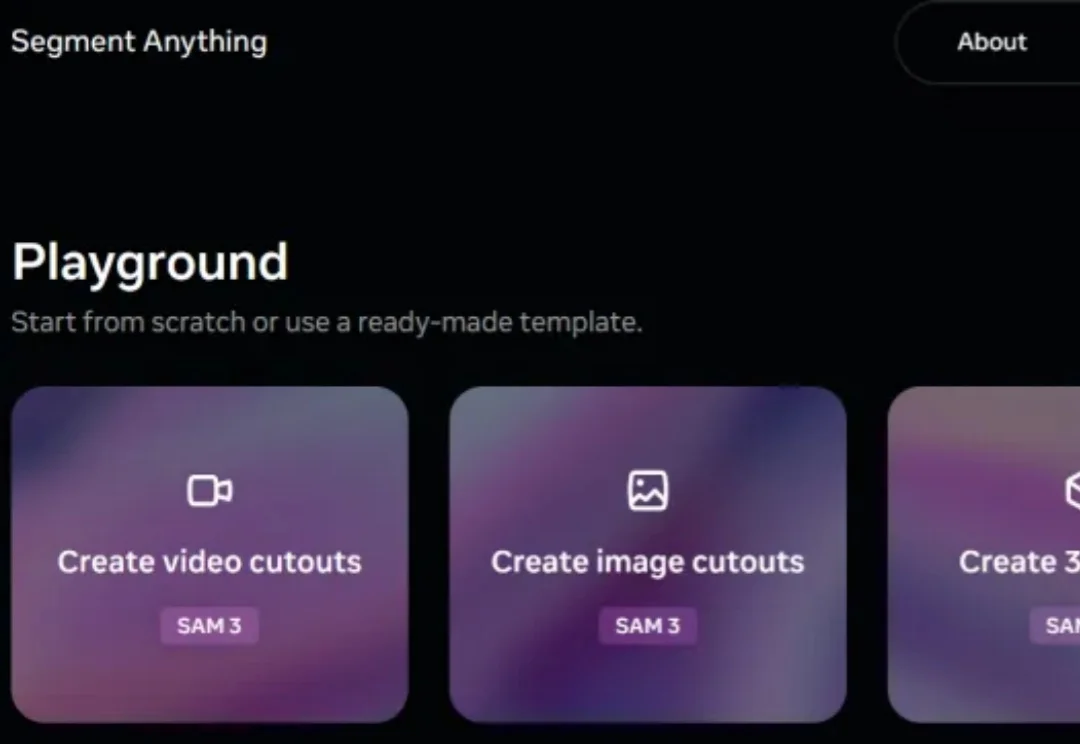
继 SAM(Segment Anything Model)、SAM 3D 后,Meta 又有了新动作。
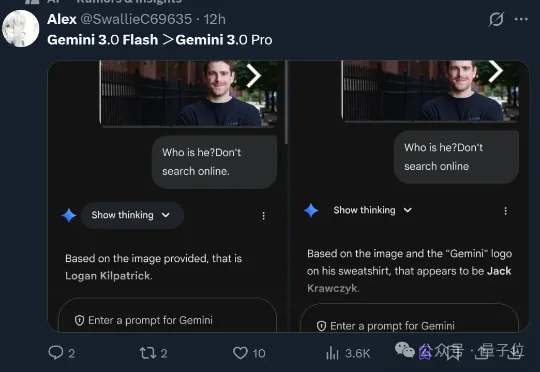
谷歌丢出Gemini 3 Flash,给AI圈示范了啥叫:小孩子才做选择题,成年人当然是全都要(doge)。一个公式来形容这款新模型:Gemini 3 Flash=Pro级智能+Flash级速度+更低价格。

AI竞技场开始清场。
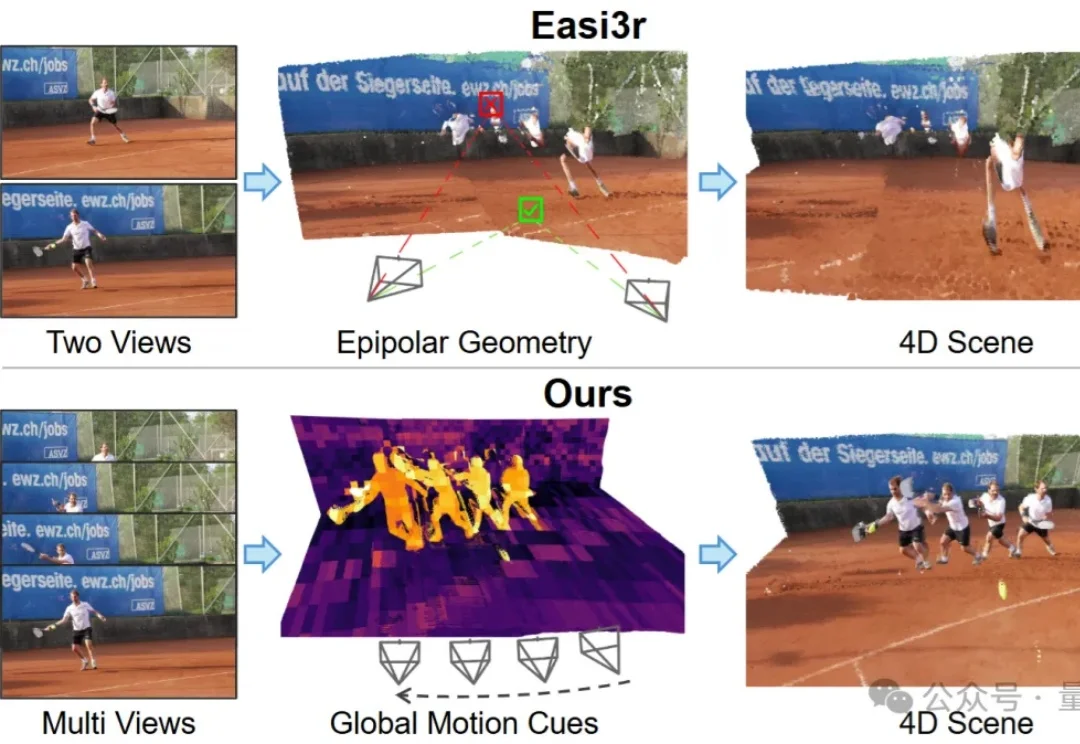
如何让针对静态场景训练的3D基础模型(3D Foundation Models),在不增加训练成本的前提下,具备处理动态4D场景的能力?
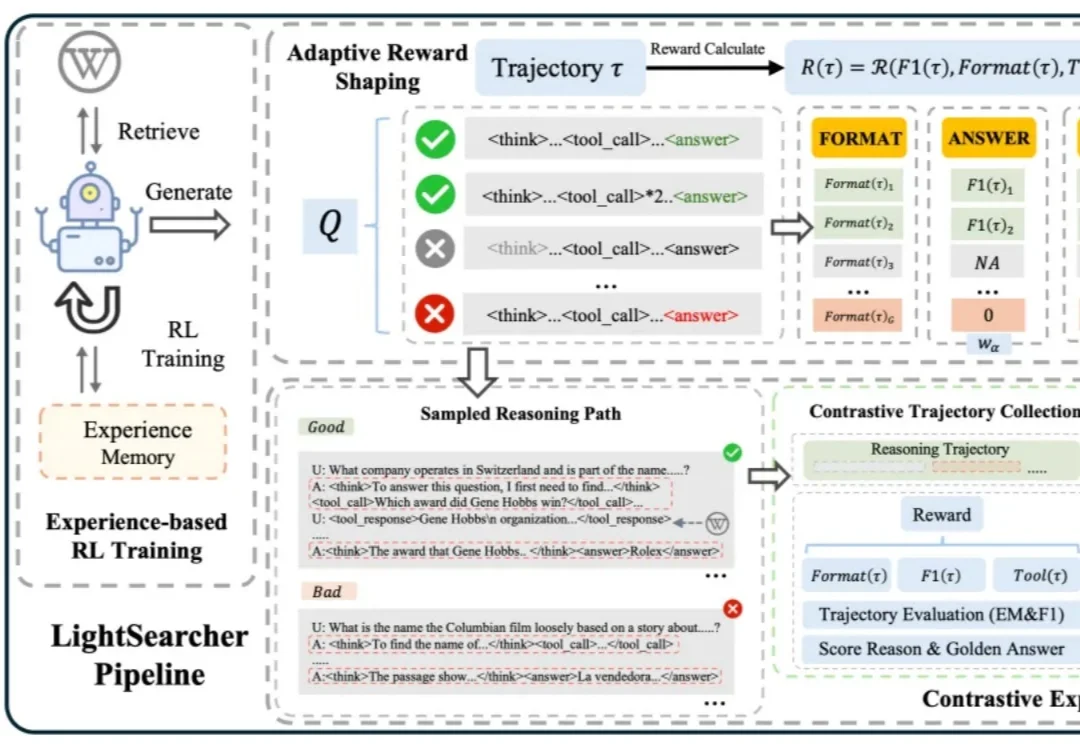
如今,以 DeepSeek-R1 为代表的深度思考大模型能够处理复杂的推理任务,而DeepSearch 作为深度思考大模型的核心搜索器,在推理过程中通过迭代调用外部搜索工具,访问参数边界之外的最新、领域特定知识,从而提升推理的深度和事实可靠性。

谷歌在2025年底甩出「王炸」:Gemini 3 Flash! 这款模型彻底打破了「快就一定笨、强就一定贵」的定律,以3倍于前代的速度实现「零延迟」响应,甚至在编程和逻辑推理上反超了Pro级大哥。
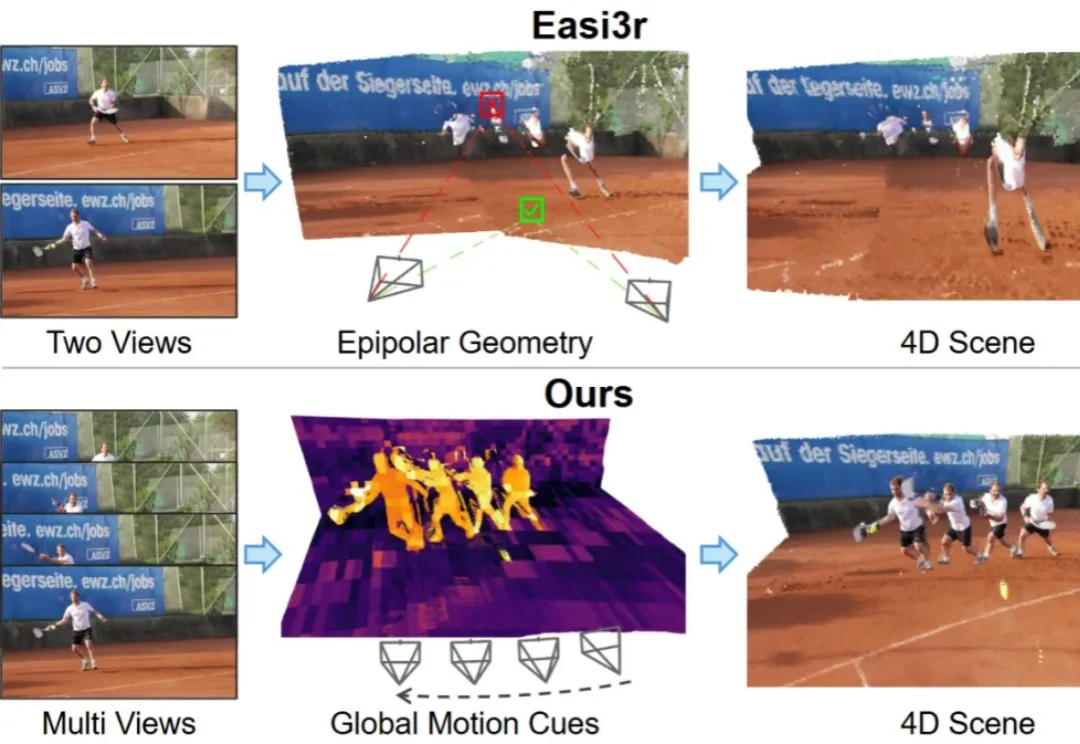
如何让针对静态场景训练的 3D 基础模型(3D Foundation Models)在不增加训练成本的前提下,具备处理动态 4D 场景的能力?