
97年文科生干出全球最强AI 3D大模型
97年文科生干出全球最强AI 3D大模型他是SIGGRAPH 50年历史上第一位、也是迄今唯一一位登上大会主题演讲舞台的中国人,与英伟达黄仁勋等行业领袖同台。
来自主题: AI资讯
10662 点击 2025-12-11 10:40
 搜索
搜索
他是SIGGRAPH 50年历史上第一位、也是迄今唯一一位登上大会主题演讲舞台的中国人,与英伟达黄仁勋等行业领袖同台。

最近,Prime Intellect正式发布了INTELLECT-3。这是一款拥有106B参数的混合专家(Mixture-of-Experts)模型,基于Prime Intellect的强化学习(RL)技术栈训练。在数学、代码、科学与推理的各类基准测试上,它达成了同规模中最强的成绩,甚至超越了不少更大的前沿模型。

宾夕法尼亚大学沃顿商学院(The Wharton School)今年发布了一系列名为《Prompting Science Reports》的重磅研究报告。他们选取了2024-2025最常用的模型(如GPT-4o, Claude 3.5 Sonnet, Gemini Pro/Flash等),在极高难度的博士级基准测试(GPQA Diamond)上进行了数万次的严谨测试。
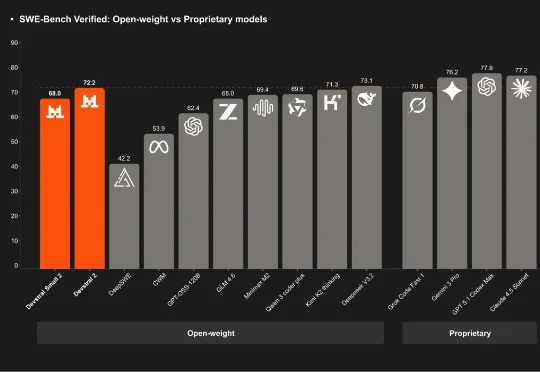
刚刚,「欧洲的 DeepSeek」Mistral AI 再次开源,发布了其下一代代码模型系列:Devstral 2。该系列开源模型包含两个尺寸:Devstral 2 (123B) 和 Devstral Small 2 (24B)。用户目前也可通过官方的 API 免费使用它们。
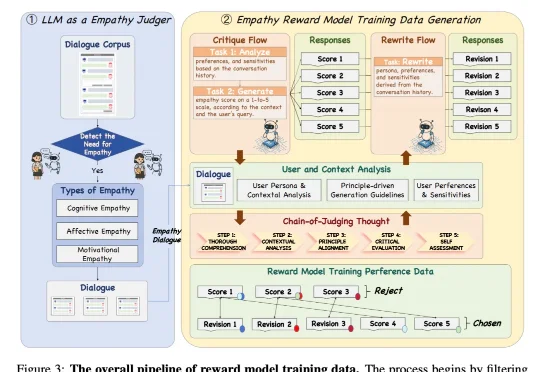
近日,来自 NatureSelect(自然选择)的研究团队 Team Echo 发布了首个情感大模型 Echo-N1,提出了一套全新的「情感模型训练方法」,成功将 RL 用在了不可验证的主观情感领域。仅 32B 参数的 Echo-N1,在多轮情感陪伴任务中胜率(Success Rate)达到 46.7%。作为对比,
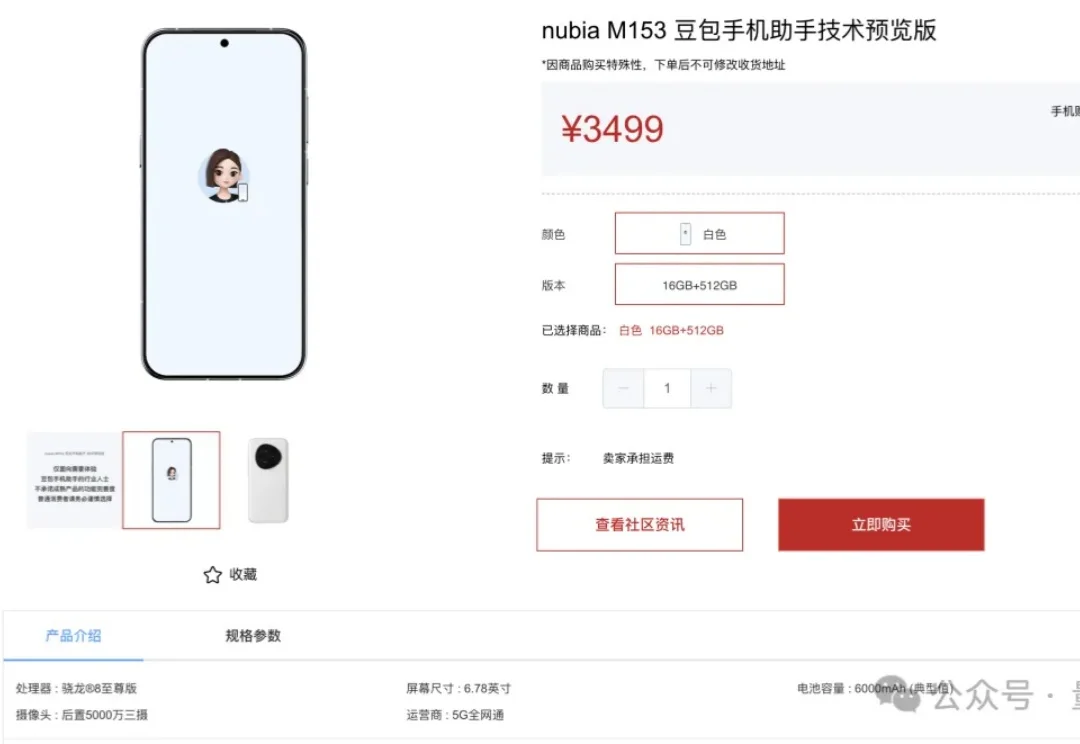
3万台首批备货被一抢而空、在二手市场价格翻番的当红炸子鸡“豆包手机”,更多技术详情得到证实。

2012 年 12 月,美国太浩湖畔 Harrah's 酒店的 731 房间,一场足以载入 AI 史册的秘密竞拍正在进行。
一家名为 FurtherAI 的创业公司宣布完成了 2500 万美元的 A 轮融资,由硅谷顶级风投 Andreessen Horowitz 领投。这是保险 AI 领域有史以来最大的 A 轮融资之一。更令人惊讶的是,这轮融资距离他们 500 万美元的种子轮仅仅过去了六个月。

33岁拥有5000台机器人是什么体验?
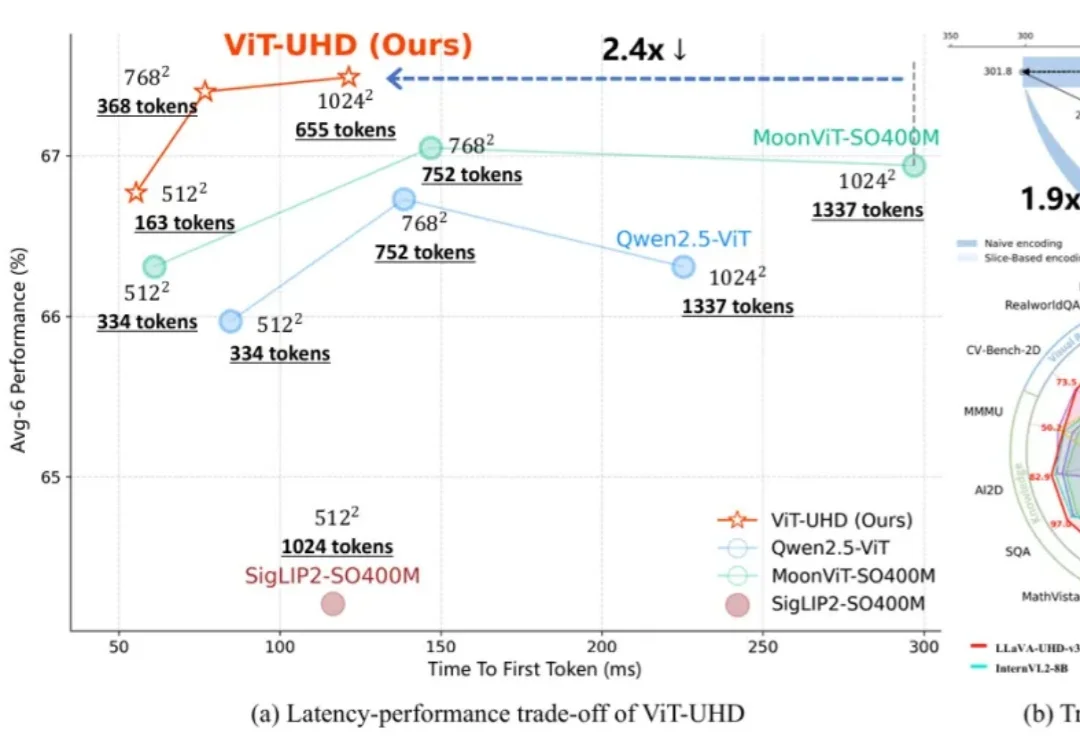
随着多模态大模型(MLLMs)在各类视觉语言任务中展现出强大的理解与交互能力,如何高效地处理原生高分辨率图像以捕捉精细的视觉信息,已成为提升模型性能的关键方向。