
LLaVA-OneVision-1.5全流程开源,8B模型预训练只需4天、1.6万美元
LLaVA-OneVision-1.5全流程开源,8B模型预训练只需4天、1.6万美元LLaVA 于 2023 年提出,通过低成本对齐高效连接开源视觉编码器与大语言模型,使「看图 — 理解 — 对话」的多模态能力在开放生态中得以普及,明显缩小了与顶级闭源模型的差距,标志着开源多模态范式的重要里程碑。
来自主题: AI技术研报
10436 点击 2025-10-15 12:12
 搜索
搜索
LLaVA 于 2023 年提出,通过低成本对齐高效连接开源视觉编码器与大语言模型,使「看图 — 理解 — 对话」的多模态能力在开放生态中得以普及,明显缩小了与顶级闭源模型的差距,标志着开源多模态范式的重要里程碑。

英伟达面向个人的AI超算DGX Spark已上市!128GB统一内存(常规系统内存+GPU显存),加上允许将两台DGX Spark连起来,直接可以跑起来405B的大模型(FP4精度),而这已经逼近目前开源的最大模型!如此恐怖的实力却格外安静优雅,大小与Mac mini相仿,3999美元带回家!

你今天的工作,或许并不是真正的工作。这句耸人听闻的言论出自奥特曼与Rowan Cheung最新的采访。在这场长达30分钟的对谈里,除了自己对AI与工作的思考,奥特曼还分享了GPT-6的进展、ChatGPT是否会成为美国版微信、AGI的设想变化、AI未来的交互模式,以及自己被恶搞成Sora热梗的感受。
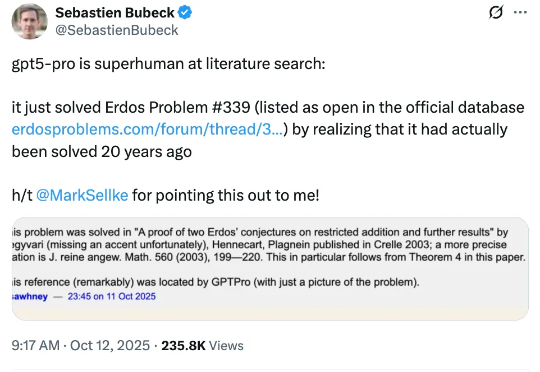
人类遗忘的难题解法,被GPT-5 Pro重新找出来了!这事儿聚焦于埃尔德什问题#339,这是著名数学家保罗・埃尔德什提出或转述的近千道问题之一,收录于erdosproblems.com网站。该网站记录了每道题目的当前状态,其中约三分之一已解决,大部分仍待解。
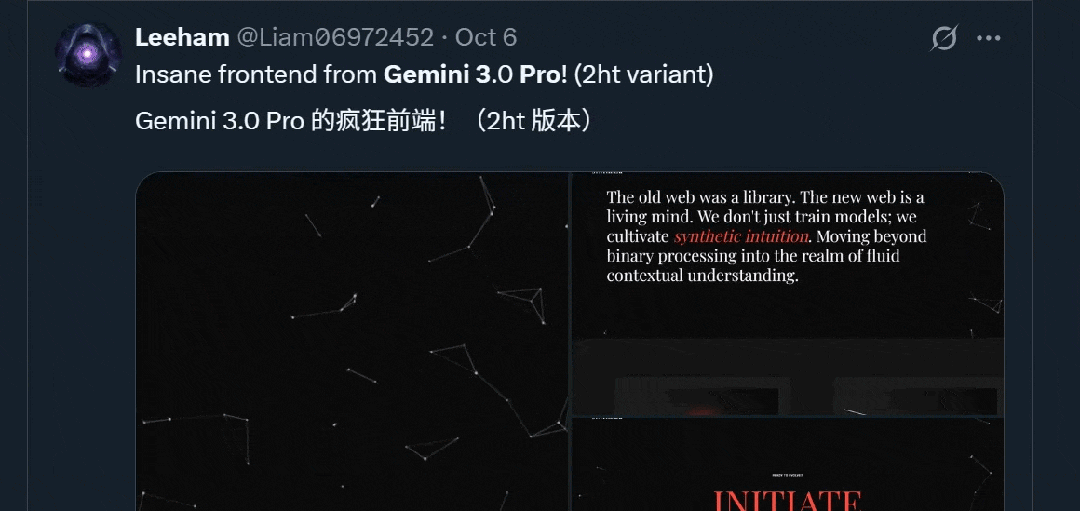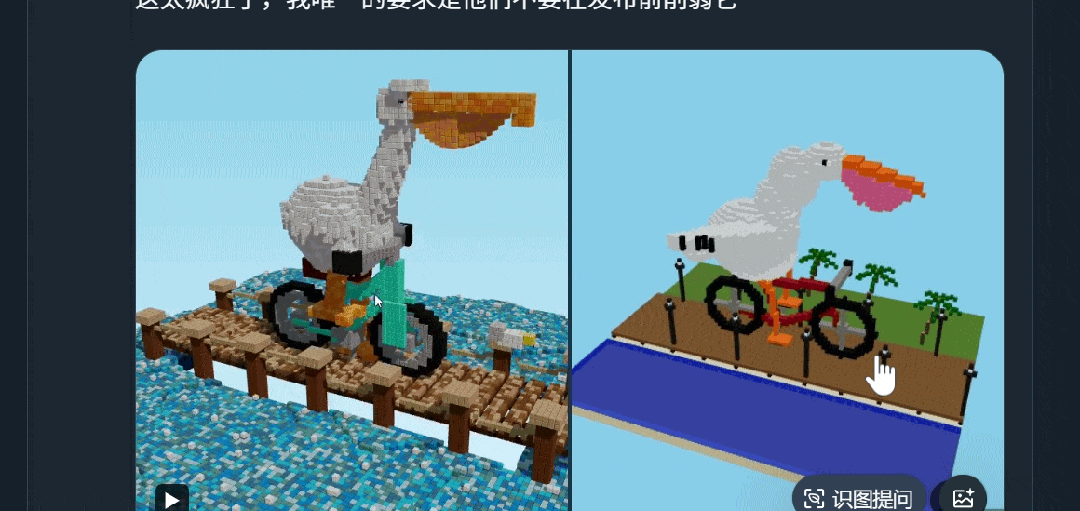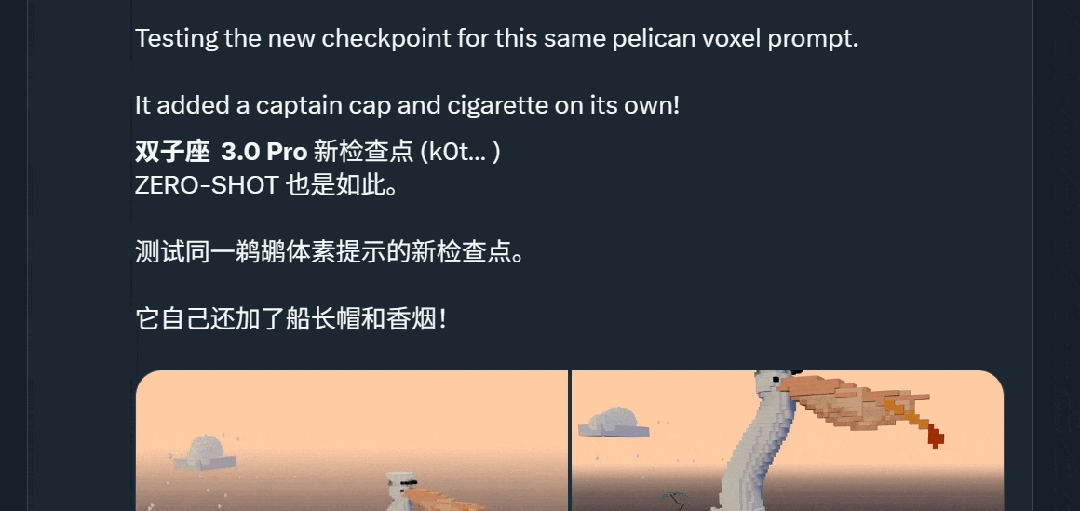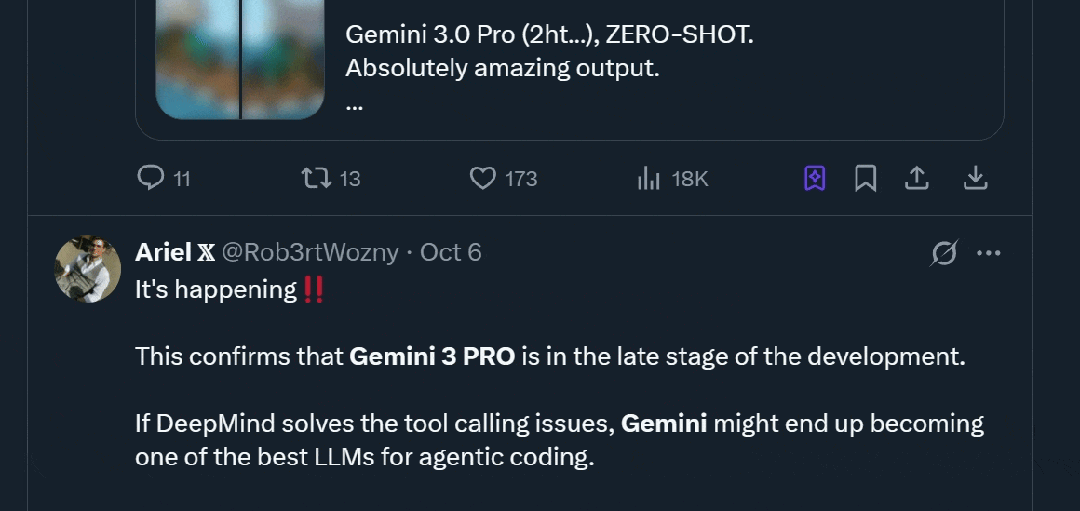
谷歌下一代旗舰模型Gemini 3未发布便已悄然走红!原因很简单:强,实在是太强了。在国外社交媒体平台𝕏上,一大波网友激动地分享了Gemini 3的内测结果——从曝光的这些案例来看,Gemini 3尤为擅长前端、SVG矢量图生成,而且多模态能力变得更强。
说出概念,SAM 3 就明白你在说什么,并在所有出现的位置精确描绘出边界。 Meta 的「分割一切」再上新? 9 月 12 日,一篇匿名论文「SAM 3: SEGMENT ANYTHING WITH CONCEPTS」登陆 ICLR 2026,引发网友广泛关注。
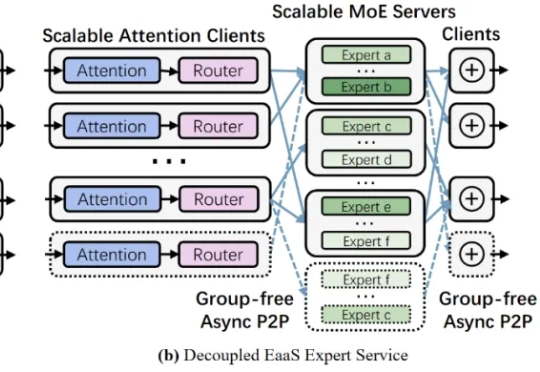
近年来,大型语言模型的参数规模屡创新高,随之而来的推理开销也呈指数级增长。如何降低超大模型的推理成本,成为业界关注的焦点之一。Mixture-of-Experts (MoE,混合专家) 架构通过引入大量 “专家” 子模型,让每个输入仅激活少数专家,从而在参数规模激增的同时避免推理计算量同比增长。
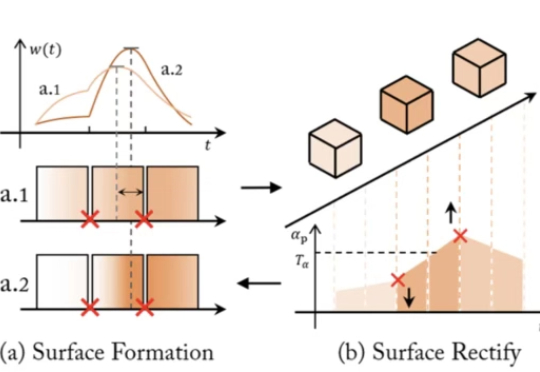
近年来,NeRF、SDF 与 3D Gaussian Splatting 等方法大放异彩,让 AI 能从图像中恢复出三维世界。但随着相关技术路线的发展与完善,瓶颈问题也随之浮现:
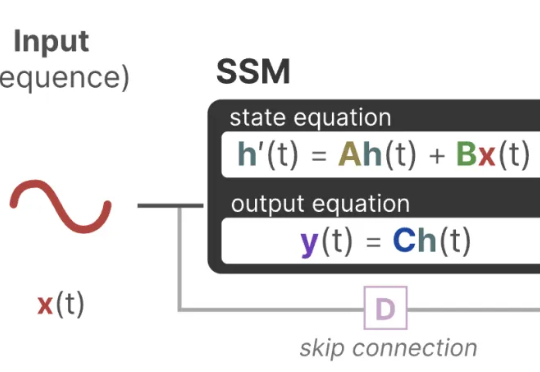
曼巴回来了!Transformer框架最有力挑战者之一Mamba的最新进化版本Mamba-3来了,已进入ICLR 2026盲审环节,超长文本处理和低延时是其相对Transformer的显著优势。另一个挑战者是FBAM,从不同的角度探索Transformer的下一代框架。

吴恩达又出新课了,这次的主题是—Agentic AI。 在新课中,吴恩达将Agentic工作流的开发沉淀为四大核心设计模式:反思、工具、规划与协作,并首次强调评估与误差分析才是智能体开发的决定性能力: