
河南师傅,左手扳手,右手飞书,竟然能搞数据分析!
河南师傅,左手扳手,右手飞书,竟然能搞数据分析!在3月份一句话搭建系统的功能之上,它又补齐了四项能力:AI问数据:用自然语言就能直接对表格数据提问,AI会自动完成数据检索、统计和多维度的分析,快速给出专业结论和业务洞察;
来自主题: AI资讯
8346 点击 2026-04-26 10:33
 搜索
搜索
在3月份一句话搭建系统的功能之上,它又补齐了四项能力:AI问数据:用自然语言就能直接对表格数据提问,AI会自动完成数据检索、统计和多维度的分析,快速给出专业结论和业务洞察;

最新消息是,DeepSeek V4 Pro 2.5折的大力度优惠来啦!官方API文档显示,DeepSeek-V4-Pro模型API限时2.5折优惠,优惠期截至2026年5月5日。 具体是这样: 1️⃣百万tokens输入(缓存命中)折后0.25元(原价1元); 2️⃣百万tokens输入(缓存未命中)折后3元(原价12元); 3️⃣百万tokens输出折后6元(原价24元)。

谷歌豪掷400亿美元加注Anthropic,自家Gemini正面对垒的「敌人」。当Claude年化收入一年暴涨30倍冲到300亿,当算力成为AI下半场唯一硬通货,与其用Gemini硬刚,不如把对手变成TPU最大买家。
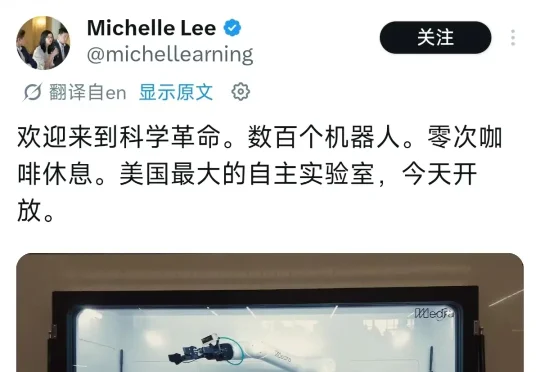
就在今天,AI机器人初创Medra正式发布美国规模最大的AI全自动自主实验室ML001。这座实验室不到90天建成,占地3.8万平方英尺,配备数百台机器人,全天候不间断运行。

最近,谷歌联合ResNet作者何恺明、谢赛宁、NeRF先驱Jonathan T. Barron、 3D图形学名家Thomas Funkhouser,正式发布了Vision Banana。它向世界宣告:视觉AI终于不再需要那些臃肿的任务头了,理解,本质上只是生成过程中的一次「对齐」。
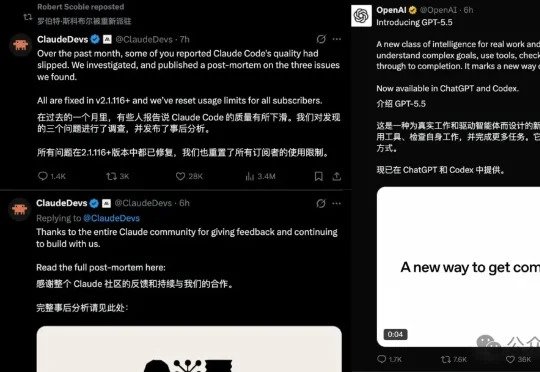
就在GPT-5.5发布的前后脚,Claude招了: 模型降智属实,所有使用额度均已重置。嘴硬了一个多月,这降智bug终于从A社自己嘴里蹦出来了:三个bug叠在一起,Claude使用体验全面拉垮。
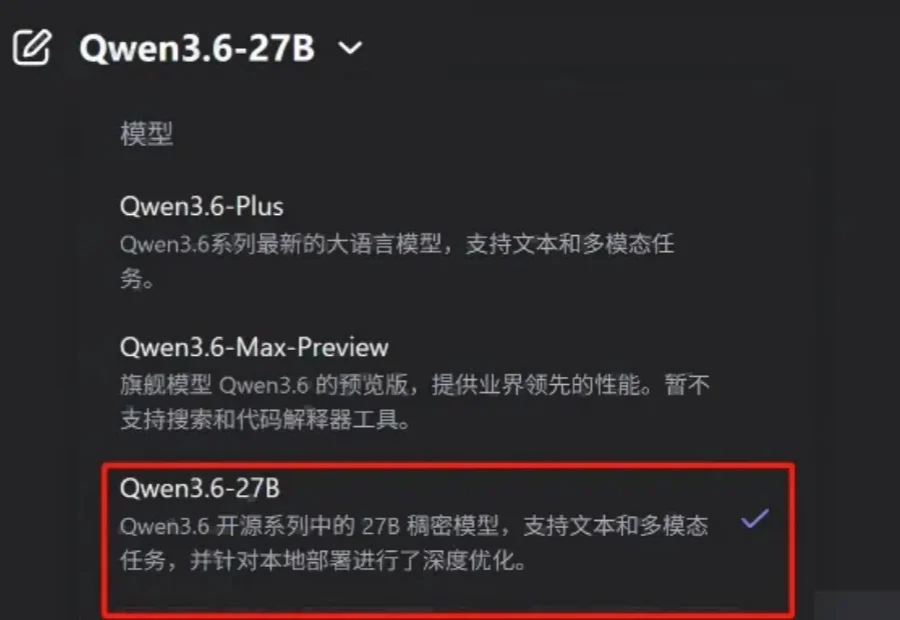
Qwen3.6系列全员集结完毕。

一份泄露的投资人备忘录显示,OpenAI正以30GW的疯狂算力规划全面猎杀对手,硅谷的终极战争已经从实验室打到了发电厂。
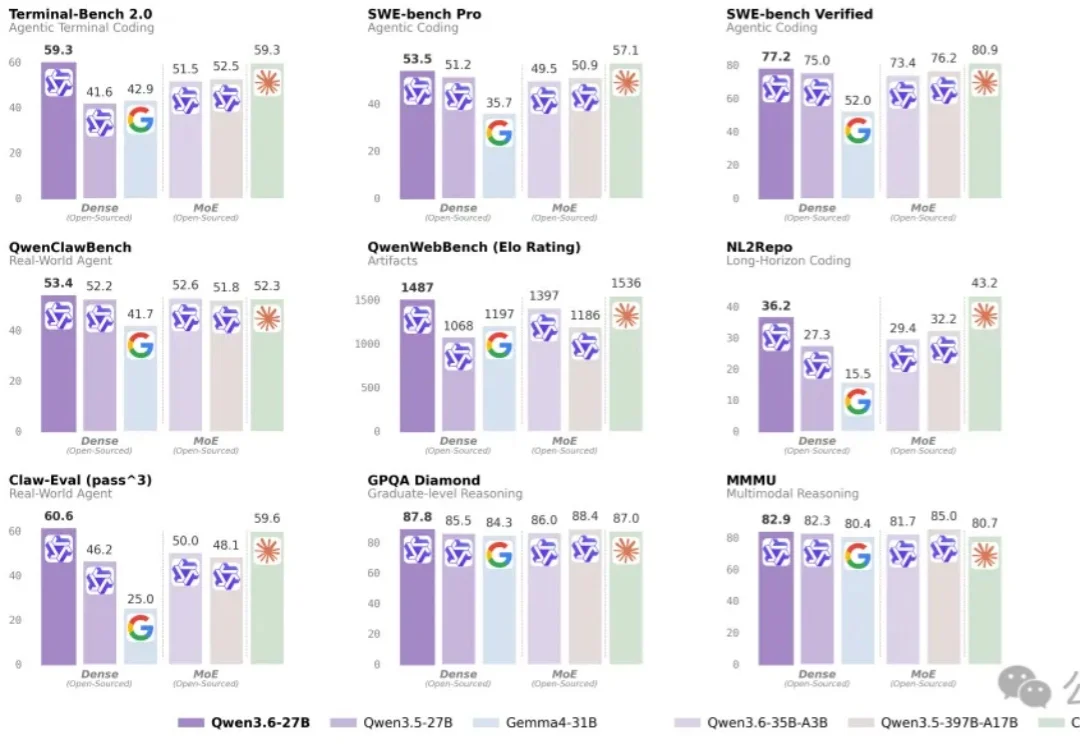
我秒了我自己??
刚刚,混元的 Hy3 Preview 也正式亮相,这是腾讯首席 AI 科学家姚顺雨主导的一个模型。姚顺雨表示,Hy3 preview是混元大模型重建的第一步。他希望通过这次开源和发布,不断提升 Hy3 正式版的实用性,以及模型在真实场景中的综合表现,并开始探索特色模型能力。