
速递丨独家爆料,Kimi 拟赴港IPO
速递丨独家爆料,Kimi 拟赴港IPO2026年3月26日彭博独家爆料,AI独角兽Moonshot AI(月之暗面)正处于考虑在香港进行IPO的早期阶段,计划登陆香港资本市场。
来自主题: AI资讯
9165 点击 2026-03-26 17:20
 搜索
搜索
2026年3月26日彭博独家爆料,AI独角兽Moonshot AI(月之暗面)正处于考虑在香港进行IPO的早期阶段,计划登陆香港资本市场。
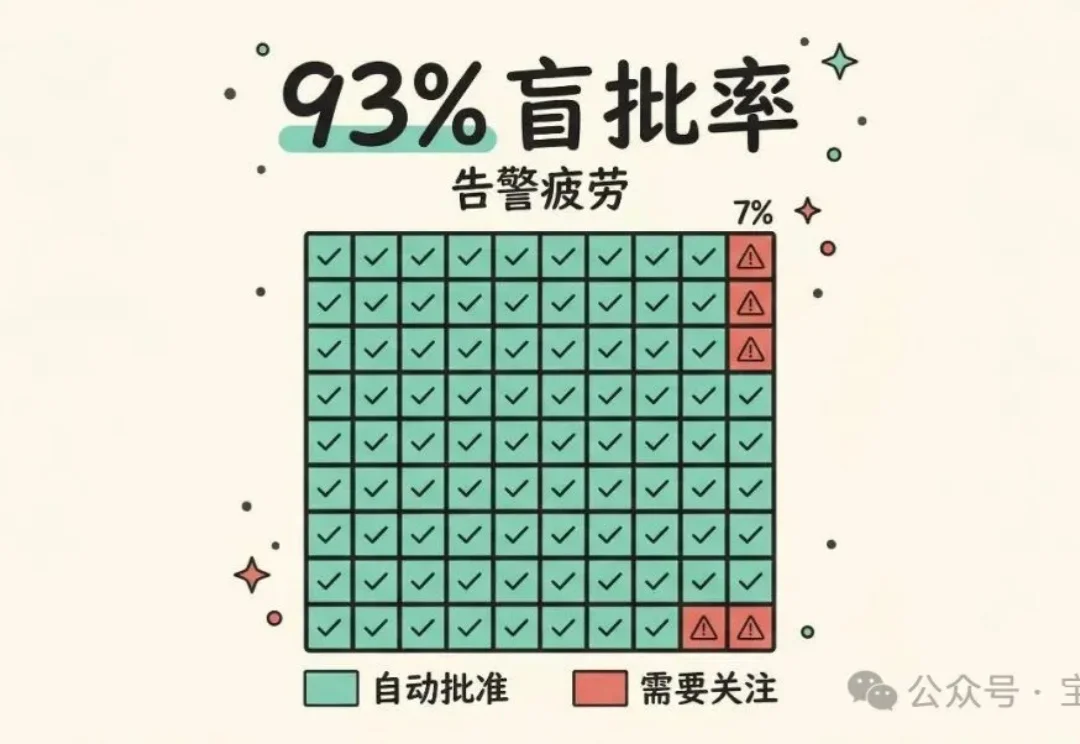
用 Claude Code 写代码的人都熟悉一个场景:Claude 每执行一个命令、每改一个文件,都要你点一次“同意”。Anthropic 的数据显示,用户 93% 的操作都会批准。也就是说,这个“安全审批”环节,绝大多数时候只是一个条件反射。
「人形机器人如果有最终形态,那一定会是有头有脸,你觉得呢?」

3月24日,Anthropic宣布Claude引入“Computer Use”能力,在Claude Cowork和Claude Code中,Claude可以直接操作用户的Mac电脑:打开文件、使用浏览器、运行开发工具,无需任何配置。该功能以研究预览版形式向Pro和Max订阅用户开放。

想象一下这样的生活片段:你拿起手机 30 秒,屏幕立刻跳出提醒,“当前心率 78,压力中等,建议深呼吸”;家里的智能摄像头静静看着午睡的宝宝,突然通过 App 提醒你:“宝宝心率偏快,呼吸略显急促,建议进屋查看”;养老院里,巡检机器人通过一次擦身而过的对视,便能感知到老人今天情绪低落,且血氧饱和度略低于往常......

谷歌一篇论文,直接让存储巨头们「集体失眠」,一夜市值蒸发几百亿!最新博客官宣TurboQuant算法,直接将缓存压到3-bit,内存占用只有1/6。

天使轮拿下2.42亿美元后,它石智航到底干啥去了?然而接下来的一年里,它石智航选择了一条截然不同的路:没有参加各种行业大会,没有频繁对外发声,没有出现在春晚或各类展示活动中,一直踏实干活。

国家超算互联网宣布启动新一轮词元赠送活动。该活动面向平台全体用户,限时免费发放单人最高3000万词元额度,以降低科研专属“龙虾”SClaw等智能体体验门槛。此外, 超算互联网用户享0.1元/百万Tokens的特惠续用价,将延至4月6日。
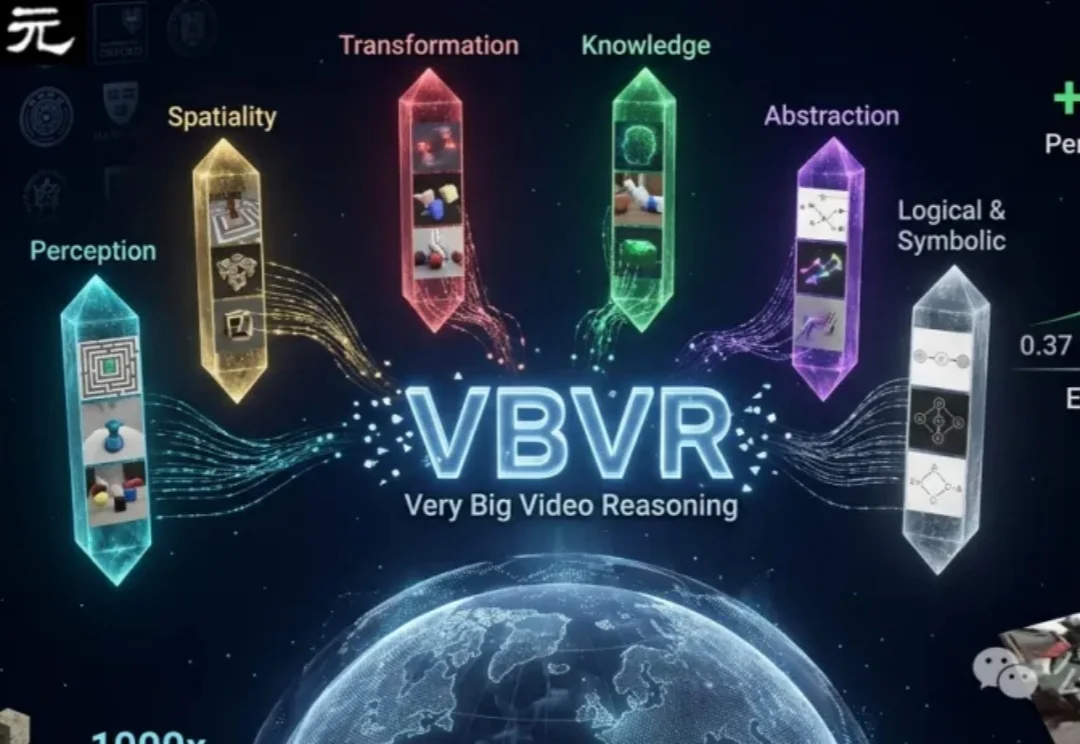
AI视频生成已能「画得像」,但不会「想得对」。VBVR推出百万级视频推理数据集,首次系统评测模型对空间、物理、逻辑和抽象的推理能力,发现顶尖模型通过率仅68%,暴露其缺乏真实认知,推动视频AI从「视觉模仿」迈向「智能推理」。
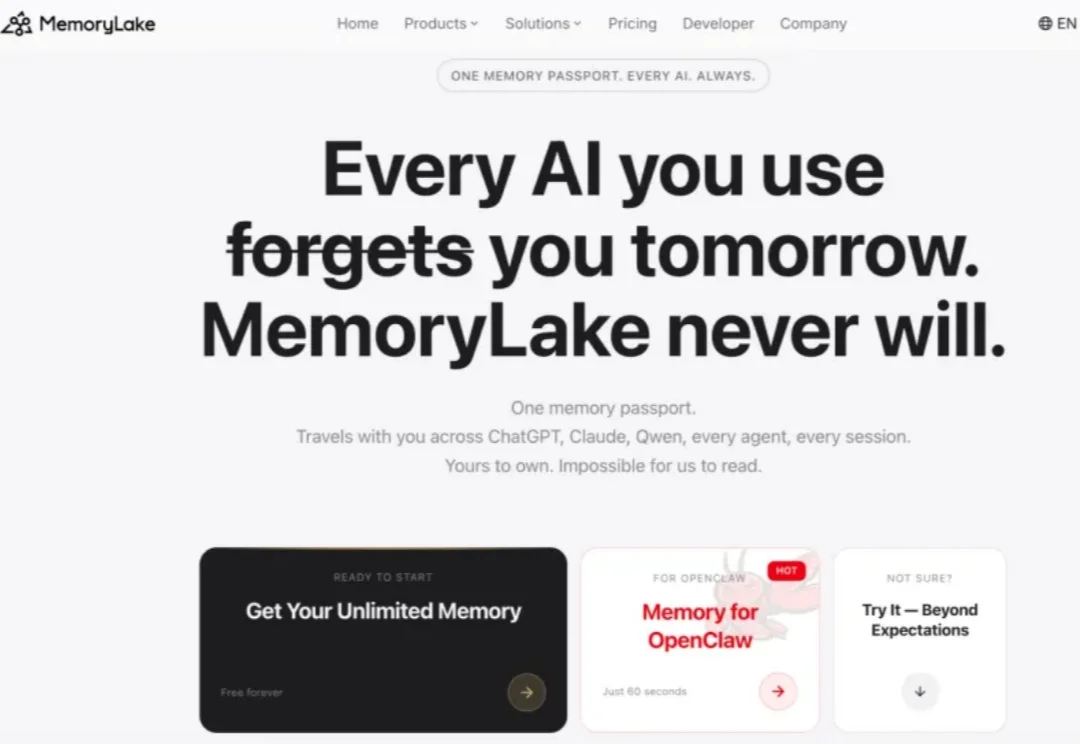
一家企业花了七周时间部署 AI:第 1 周精准回答行业分析问题,团队欢呼;第 3 周反复回答相同的错误结论,因为它“忘了”上周的修正;第 5 周在董事会汇报中引用了已被否定的数据,造成决策偏差;第 7 周项目暂停,“AI 不可信”成为共识。问题不在于 AI 不够聪明,而在于它每次醒来都是一张白纸。