
对话 VAST 宋亚宸:3D 关乎全人类幸福,也关乎我的
对话 VAST 宋亚宸:3D 关乎全人类幸福,也关乎我的一个先相信、后看见的 AI 创业者。
来自主题: AI资讯
7164 点击 2025-06-10 12:27
 搜索
搜索
一个先相信、后看见的 AI 创业者。
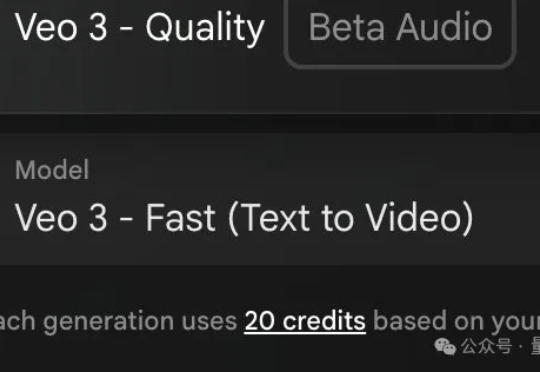
谷歌旗舰视频模型Veo 3上线不到一个月,各种玩法层出不穷。 这不,玩法再升级,只需添加一个提示词“360°”就能解锁3D世界!

3D生成模型高光时刻来临!DreamTech联手南大、复旦、牛津发布的Direct3D-S2登顶HuggingFace热榜。仅用8块GPU训练,效果超闭源模型,直指影视级精细度。

6月6日,麻省理工学院与Recursion共同宣布推出一款突破性的AI+药物研发模型Boltz-2,用于预测药物靶标 3D 结构,以及结合亲和力。

想象一下,你在一个陌生的房子里寻找合适的礼物盒包装泰迪熊,需要记住每个房间里的物品特征、位置关系,并根据反馈调整行动。

李飞飞空间智能创业公司World Labs,开源一项核心技术!

最近,大家开始用3d打印整活了:
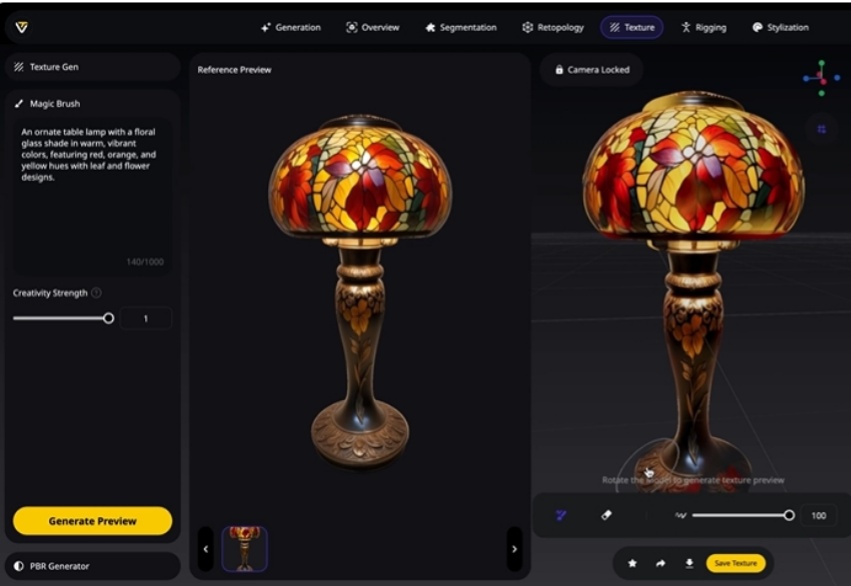
AI建模界的“作弊神器”真的来了!
从OpenAI 的 4o 到 Stable Diffusion,能够根据文本提示生成逼真图像的 AI 基础模型如今已比比皆是。相比之下,能够仅凭文本提示就生成完整、连贯的 3D 在线环境的基础模型才刚刚崭露头角。
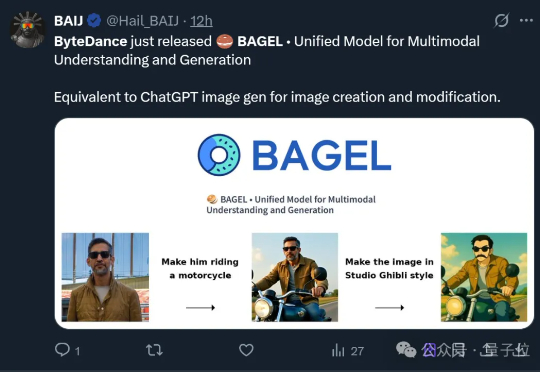
字节最近真的猛猛开源啊……这一次,他们直接开源了GPT-4o级别的图像生成能力。不止于此,其最新融合的多模态模型BAGEL主打一个“大一统”, 将带图推理、图像编辑、3D生成等功能全都集中到了一个模型。