
「耀速科技」获数千万元战略投资,推动“AI+器官芯片”助力新药研发新范式
「耀速科技」获数千万元战略投资,推动“AI+器官芯片”助力新药研发新范式近期,美国FDA正式宣布计划逐步取消在单抗疗法等药物研发中对动物实验的强制性要求。
来自主题: AI资讯
8973 点击 2025-04-28 16:28
 搜索
搜索
近期,美国FDA正式宣布计划逐步取消在单抗疗法等药物研发中对动物实验的强制性要求。

最近,北京大学陈宝权教授带领团队在三维形状生成和三维数据对齐方面取得新的突破。在三维数据生成方面,团队提出了3D自回归模型新范式,有望打破3D扩散模型在三维生成方面的垄断地位。
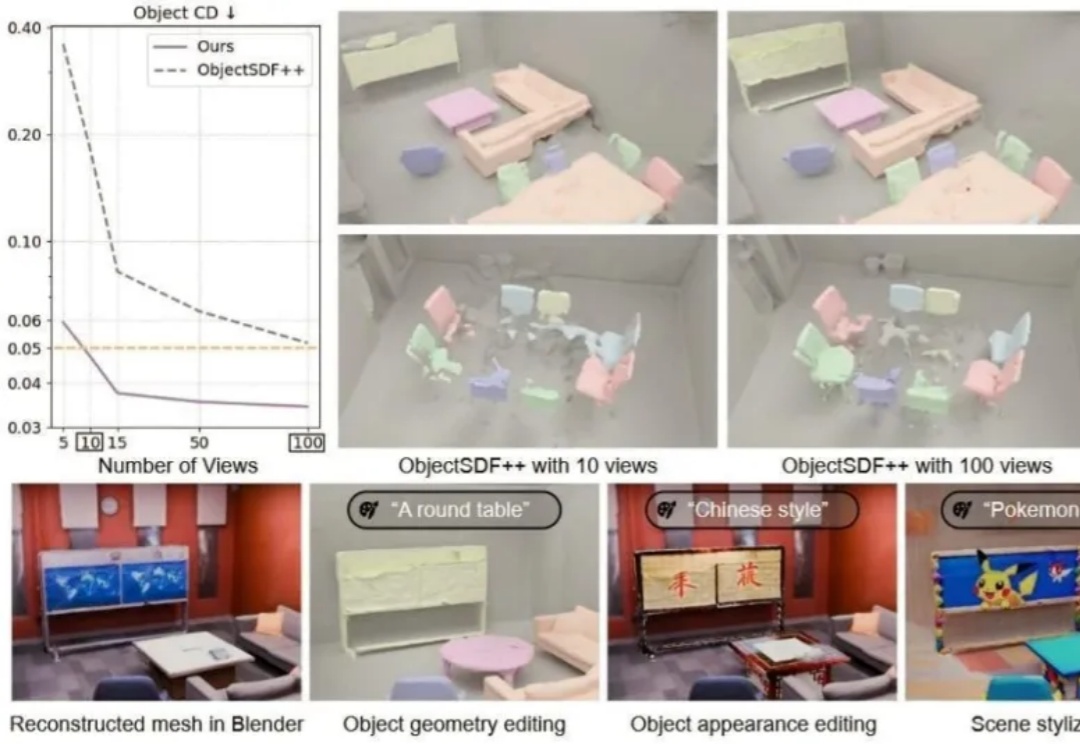
你是否设想过,仅凭几张随手拍摄的照片,就能重建出一个完整、细节丰富且可自由交互的3D场景?

用户仅仅通过输入文字,就能生成一个3D世界。

随着3D Gaussian Splatting(3DGS)成为新一代高效三维建模技术,它的自适应特性却悄然埋下了安全隐患。
无论你是技术创造者还是使用者,理解这场认知革命都至关重要。我们正在从「AI as tools」向「AI as thinking partners」转变,这不仅改变了技术的能力边界,也改变了我们与技术协作的方式。

近日,上海人工智能实验室(上海 AI 实验室)开源了生成式世界模型 AETHER。该模型全部由合成数据训练而成,不仅在传统重建与生成任务中表现领先,更首次赋予大模型在真实世界中的 3D 空间决策与规划能力,
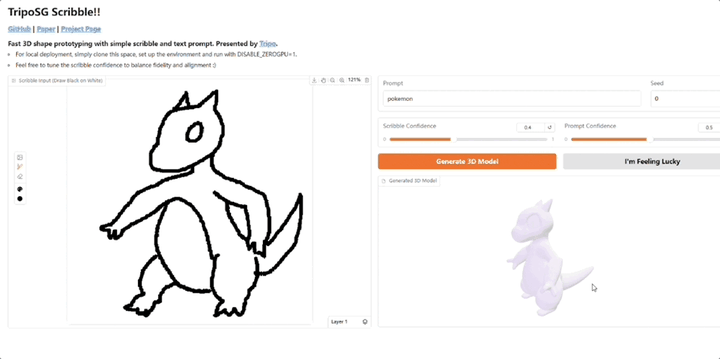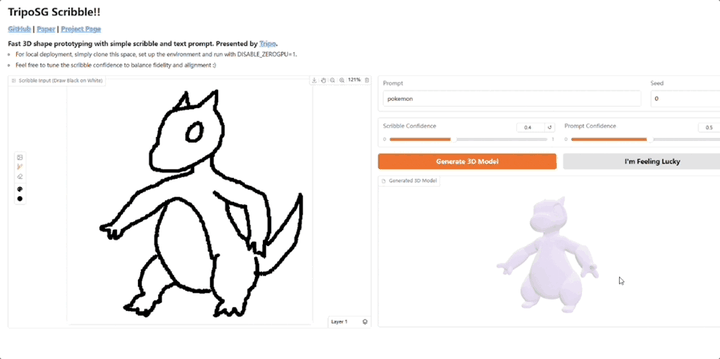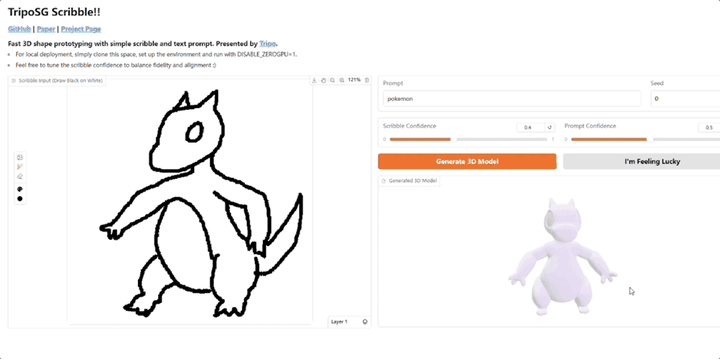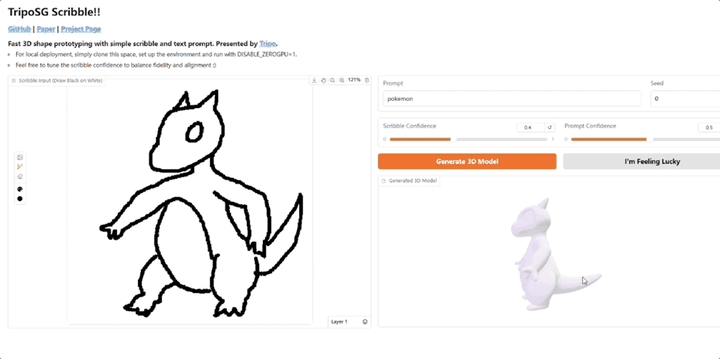
3D生成明星玩家VAST,又又又又又开源了!Tripo Doodle(内部代号TripoSG Scribble) ,能够将简单的2D草图和文本提示(Text Prompt)实时转化为精细的3D模型。它改进了传统3D建模学习曲线陡峭、耗时耗力的痛点,尤其是在初期“打形”阶段。

具身智能的突破离不开高质量数据。目前,具身合成数据有两条主要技术路线之争:“视频合成+3D重建”or “端到端3D生成”。英伟达在CES 2025指出“尚无互联网规模的机器人数据”,自动驾驶已具备城市级仿真,但家庭等复杂室内环境缺乏3D合成平台。
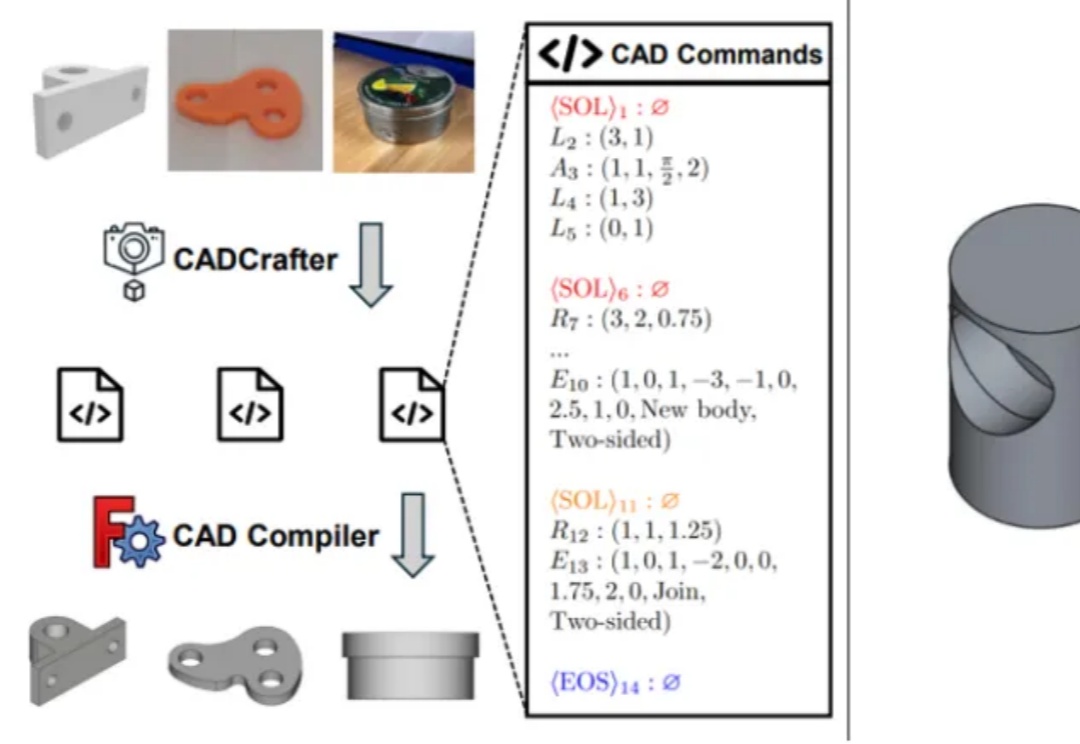
单张图直接就能生成可编辑的CAD工程文件!