

70倍极致压缩!大模型的检查点再多也不怕
70倍极致压缩!大模型的检查点再多也不怕大模型作为当下 AI 工业界和学术界当之无愧的「流量之王」,吸引了大批学者和企业投入资源去研究与训练。随着规模越做越大,系统和工程问题已经成了大模型训练中绕不开的难题。例如在 Llama3.1 54 天的训练里,系统会崩溃 466 次,平均 2.78 小时一次!
来自主题: AI技术研报
9845 点击 2024-08-05 14:04
大模型作为当下 AI 工业界和学术界当之无愧的「流量之王」,吸引了大批学者和企业投入资源去研究与训练。随着规模越做越大,系统和工程问题已经成了大模型训练中绕不开的难题。例如在 Llama3.1 54 天的训练里,系统会崩溃 466 次,平均 2.78 小时一次!

靴子终于落地,OpenAI的AI搜索还是来了。7月26日,就在推出小模型GPT-4o mini的一周后,OpenAI方面公布了备受外界关注的搜索产品SearchGPT。尽管目前SearchGPT仅向10000名测试用户开放,但OpenAI CTO Mira Murati在社交平台已经透露,最终目标是将搜索功能直接整合到ChatGPT中。

这个贴吧里的网友,都不是人!

明星AI独角兽Character.AI,核心团队被谷歌打包带走了。

残暴的欢愉,终将以残暴结束。 当盛宴开启之时,没人想到,大模型的淘汰赛,会来的如此之快。 火药味首先表现在创投市场。PitchBook 最新报告披露,相比2023年一季度,全球2024年一季度大模型融资额,从216.9亿美元增长到了258.7亿美元,但涉及的交易数量,却从 1909 笔下滑至1545笔——产业格局正迅速向强者收拢。

明星AI独角兽Character.AI,核心团队被谷歌打包带走了。

只是一种补充,并非要替代人类朋友。

谷歌DeepMind推出LLM自动评估模型FLAMe系列,FLAMe-RM-24B模型在RewardBench上表现卓越,以87.8%准确率领先GPT-4o。
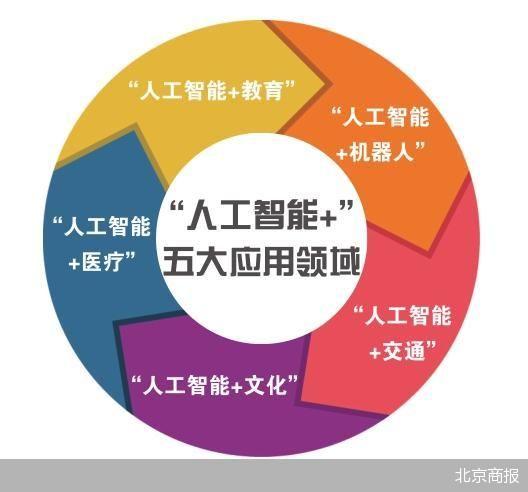
7月26日,《北京市推动“人工智能+”行动计划(2024—2025年)》(以下简称《行动计划》)正式对外发布。

7月上旬,多位在字节跳动旗下免费阅读平台番茄小说更新作品的网络文学作者,收到了后台系统发送的“AI训练补充协议”签署提醒。其中提到,一旦签署,其作品内容及相关信息,将被用于平台AI模型训练或其他技术研发应用场景。