

大模型也能切片,微软SliceGPT让LLAMA-2计算效率大增
大模型也能切片,微软SliceGPT让LLAMA-2计算效率大增删除权重矩阵的一些行和列,让 LLAMA-2 70B 的参数量减少 25%,模型还能保持 99% 的零样本任务性能,同时计算效率大大提升。这就是微软 SliceGPT 的威力。
来自主题: AI技术研报
4640 点击 2024-01-30 13:43
删除权重矩阵的一些行和列,让 LLAMA-2 70B 的参数量减少 25%,模型还能保持 99% 的零样本任务性能,同时计算效率大大提升。这就是微软 SliceGPT 的威力。
Meta 正式发布 Code Llama 70B,这是 Code Llama 系列有史以来最大、性能最好的型号。

Quora联合创始人兼首席执行官Adam D'Angelo发文宣布,已从硅谷风投巨擘Andreessen Horowitz 处筹集7500万美元。这笔资金将用于加速公司AI 聊天平台Poe的发展,其中大部分会投入支持AI开发者的创作货币化。
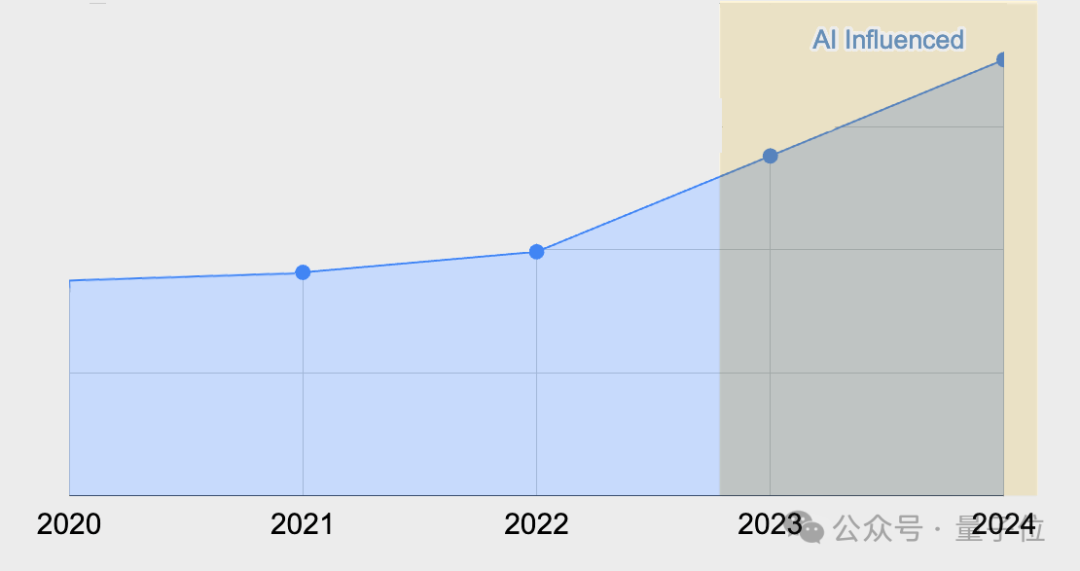
一家名为GitClear的公司分析了近四年超过1.5亿行代码后发现,随着GitHub Copilot工具的加入,代码流失率(即代码写入后不久又被返工修改、删除的情况)出现了显著上升: 2023年为7.1%,而2020年时仅为3.3%,翻了一番。

爆肝7个月,谷歌祭出了AI视频大模型Lumiere,直接改变了游戏规则!全新架构让视频时长和一致性全面飞升,时长直接碾压Gen-2和Pika。
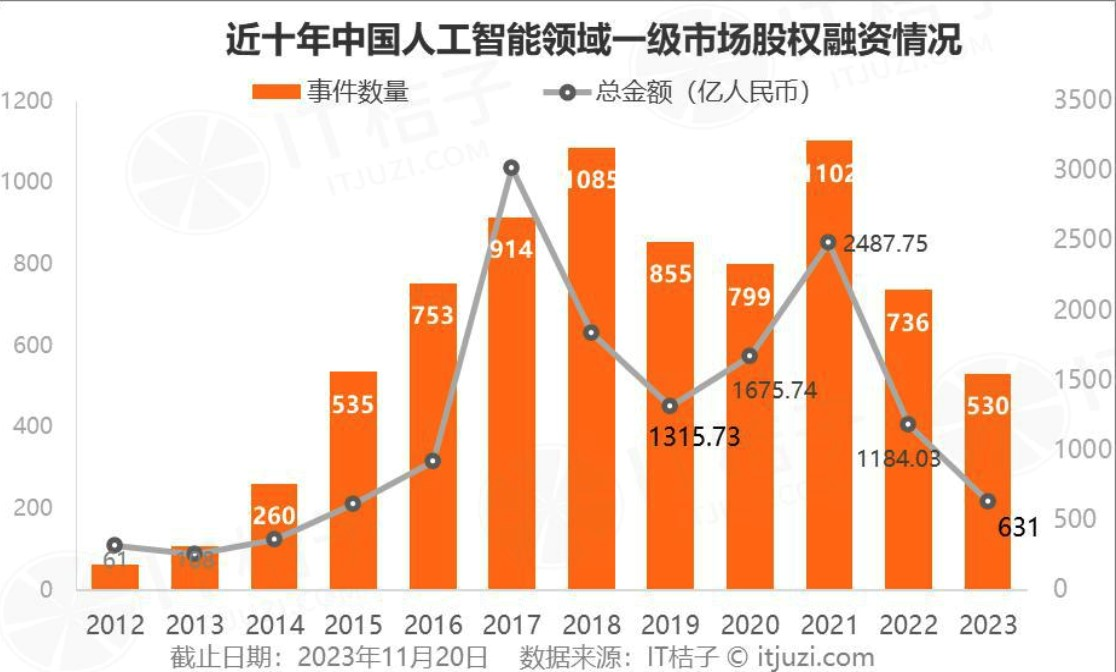
据The information的Creator Economy Database最新数据,在数据库覆盖的350多家全球创业公司中,2023年募得资金量继续螺旋式下降,至约17亿美元,其中人工智能初创企业在融资份额中占比最大,超3.24亿美元。

昨天,Meta、纽约大学的研究者用「自我奖励方法」,让大模型自己生成自己的微调数据,从而在 Llama 2 70B 的迭代微调后超越了 GPT-4。今天,英伟达的全新对话 QA 模型「ChatQA-70B」在不使用任何 GPT 模型数据的情况下,在 10 个对话 QA 数据集上的平均得分略胜于 GPT-4。

谷歌CEO劈柴在公开信中承认:谷歌的裁员计划还要持续一整年,还有更多岗位会被淘汰,且持续一整年。根据Layoffs数据,开年不到一个月,科技公司总共已裁掉7,785名员工。AI真来淘汰人类了?

Mixtral 8x7B模型开源后,AI社区再次迎来一大波微调实践。来自Nous Research应用研究小组团队微调出新一代大模型Nous-Hermes 2 Mixtral 8x7B,在主流基准测试中击败了Mixtral Instruct。

不得不说,现在拍写真真是“简单到放肆”了。真人不用出镜,不用费心凹姿势、搞发型,只需一张本人图像,等待几秒钟,就能获得7种完全不同风格: