
独家丨全球首个AI游戏社区Aippy完成千万美元首轮融资,估值17亿元
独家丨全球首个AI游戏社区Aippy完成千万美元首轮融资,估值17亿元全球首个AI游戏社区Aippy近日完成数千万美元首轮融资,由歌未资本(Glowill Capital)投资,投后估值达到2.5亿美元(约合17亿元人民币)。该产品由港股上市公司赤子城科技(以下简称“赤子城”)孵化,掌舵人Evan(叶椿建)是赤子城联合创始人,
来自主题: AI资讯
8563 点击 2026-06-02 11:53
 搜索
搜索
全球首个AI游戏社区Aippy近日完成数千万美元首轮融资,由歌未资本(Glowill Capital)投资,投后估值达到2.5亿美元(约合17亿元人民币)。该产品由港股上市公司赤子城科技(以下简称“赤子城”)孵化,掌舵人Evan(叶椿建)是赤子城联合创始人,
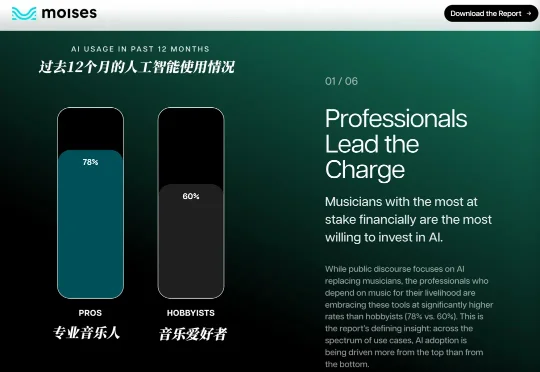
音乐产业正在经历一个新的“奥德赛时期”,变量无疑来自AI。到目前为止,专业音乐人们大都对使用AI讳莫如深,但一些报告称,AI已经在行业里广为普及。今年3月,moises和Water & Music联合发布的报告称,专业音乐人的AI使用率达到78%。

时隔近十个月,微脉再次向港交所递交上市申请,以“中国医院合作模式全病程管理市场第一”的身份冲刺“AI全病程管理第一股”。2023年至2025年,公司营收从6.28亿元增长至8.63亿元,毛利率从18.9%提升至21.7%,毛利率提升、营收持续增长,乍看是一份不错的成绩单。
上一篇文章,和大家聊了一下这个项目,做了一个整体性的复盘,但主要是以业务和团队等方面说的,但是实现方案和大模型相关评估上,说的不多,这篇文章,我们就在产品实现方案和大模型这块来聊一下。

这一瓶颈是结构性的——这意味着每次请求都必须经过业内成本最高、功耗最大的芯片。这种低效正是总部位于韩国和美国的初创公司 XCENA 试图解决的问题。 这家成立四年的初创公司设计了一款芯片,将计算能力置于更接近 DRAM 的位置

6月1日,上海证券交易所上市审核委员会召开2026年第31次上市审核委员会审议会议,审议结果显示,宇树科技股份有限公司(首发):符合发行条件、上市条件和信息披露要求。从3月20日上交所受理宇树科技IPO申请,到6月1日过会,用时仅73天。

2026年5月30日,半导体研究机构SemiAnalysis发布深度报告《AI Dark Output: The Visible Cost of Invisible Output》,提出了一个“暗产出”的概念,判断AI正在大规模创造真实经济价值,但这些价值在GDP、价格指数和就业统计中几乎无迹可寻,规模“可能不亚于工业革命”。

OpenAI 公布了他们语音黑客松的四个入围项目,目前正在公开投票。 四个入围项目 这是 OpenAI 和 Cerebral Valley 在旧金山联合办的一场黑客松。5 月 27 日,在 OpenAI 总部,参与者带着自己的语音 Agent 原型到现场展示。

这半年我自己做了一款次留70%,月留存30%的个人助手产品,也把市场上所有和沾边的产品都上手用过一遍。想来写写这几个月对这个领域的一手的产品观察。第一部分是做产品的过程,第二部分是一手的观察和判断,按需取用~
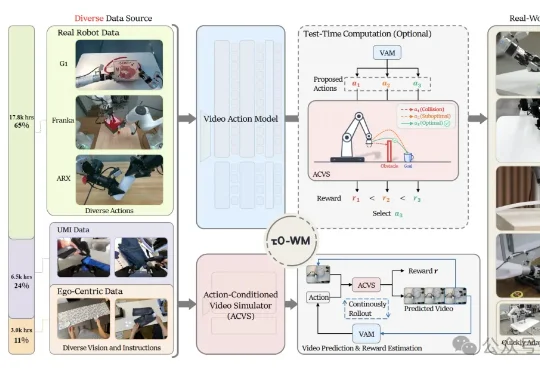
刚刚,上海创智学院副教授、智元机器人首席科学家罗剑岚带队,发布全球最大规模的开源预训练具身世界模型——τ0-World Model(τ0-WM)。整个τ0-WM参数量达到5B,预训练数据规模高达约3万小时。其中,真机遥操作数据第一次成了绝对主力,占到了1.78万小时。