

刚刚,全球首个GB300巨兽救场!一年烧光70亿,OpenAI内斗GPU惨烈
刚刚,全球首个GB300巨兽救场!一年烧光70亿,OpenAI内斗GPU惨烈为了争夺有限的GPU,OpenAI内部一度打得不可开交。2024年总算力投入70亿美元,但算力需求依旧是无底洞。恰恰,微软发布了全球首台GB300超算,专供OpenAI让万亿LLM数天训完。
来自主题: AI资讯
9739 点击 2025-10-11 10:42
为了争夺有限的GPU,OpenAI内部一度打得不可开交。2024年总算力投入70亿美元,但算力需求依旧是无底洞。恰恰,微软发布了全球首台GB300超算,专供OpenAI让万亿LLM数天训完。

1.3千万亿,一个令人咂舌的数字。这就是谷歌每月处理的Tokens用量。据谷歌“宣传委员”Logan Kilpatrick透露,这一数据来自谷歌对旗下各平台的内部统计。那么在中文世界里,1.3千万亿Tokens约2.17千万亿汉字。换算成对话量,一本《红楼梦》的字数在70-80万左右,相当于一个月内所有人和谷歌AI聊了近30亿本《红楼梦》的内容。
来自加拿大蒙特利尔三星先进技术研究所(SAIT)的高级 AI 研究员 Alexia Jolicoeur-Martineau 介绍了微型递归模型(TRM)。这个 TRM 有多离谱呢?一个仅包含 700 万个参数(比 HRM 还要小 4 倍)的网络,在某些最困难的推理基准测试中,
MGX,全称 MetaGPT X,是 DeepWisdom 推出的多智能体平台,定位是“24/7 的 AI 开发团队”。它的特别之处在于,你只需要输入需求,系统就会自动生成一支虚拟团队。
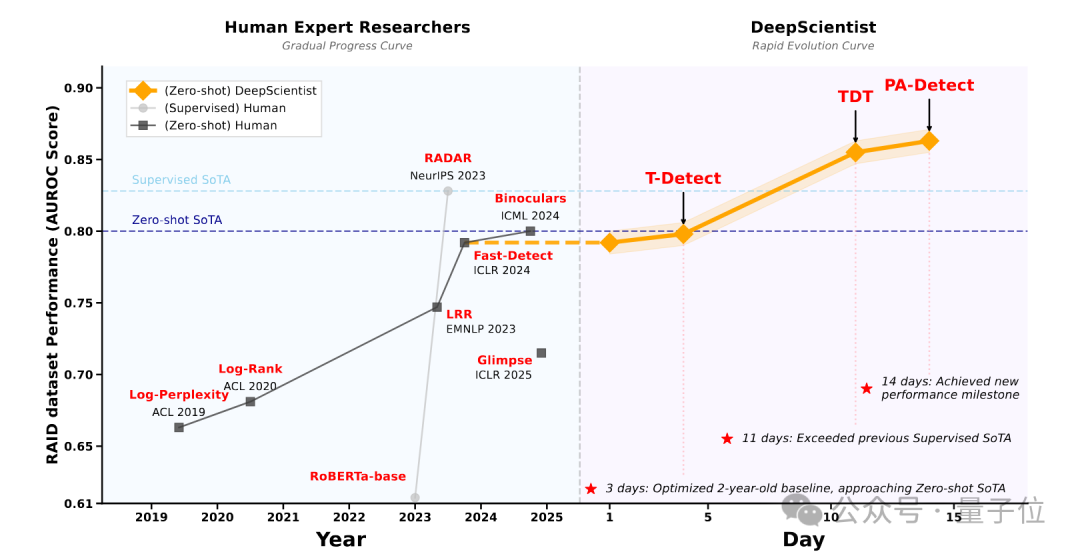
最近,来自西湖大学的自然语言处理实验室发布了DeepScientist系统,这也是首个具有完整科研能力,且在无人工干预下,展现出目标导向、持续迭代、渐进式超越人类研究者最先进研究成果的AI科学家系统。
清华物理系传奇特奖得主姚顺宇离职Anthropic,正式加盟谷歌DeepMind!他在Anthropic仅工作一年,离职原因中约40%与公司「价值观」不合。他指出现阶段AI研究如同17世纪热力学探索:虽缺乏完整理论,却充满规律发现的契机。

不是拼凑知识点,AI这次是真搞研究。一个叫Virtuous Machines的AI系统,花了17小时、114美元,找了288个真人做实验,写了一篇30页的学术论文。而且还是从选题到成稿全自动化速通!?
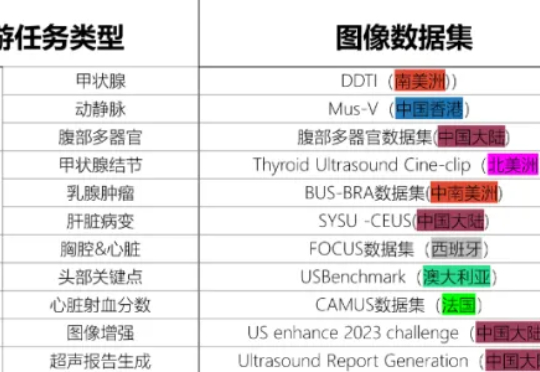
2025年9月17日,中国科学院香港创新研究院人工智能与机器人创新中心(CAIR)在香港正式开源发布其最新科研成果——EchoCare“聆音”超声基座大模型(简称“聆音”)。该模型基于超过450万张、涵盖50多个人体器官的大规模超声影像数据集训练而成,在器官识别、器官分割、病灶分类等10余项典型超声医学任务测试中表现卓越,性能全面登顶。
近日,微软和多家公司、高校、研究机构组成的联合团队在生物科学领域发现了一个重大的“零日漏洞”。他们利用开源的人工智能蛋白质设计工具,基于 72 种已知危险蛋白,模拟生成了 7 万多种原始有害蛋白质的变体,并将它们放入 4 种现有的生物安全筛查系统中。
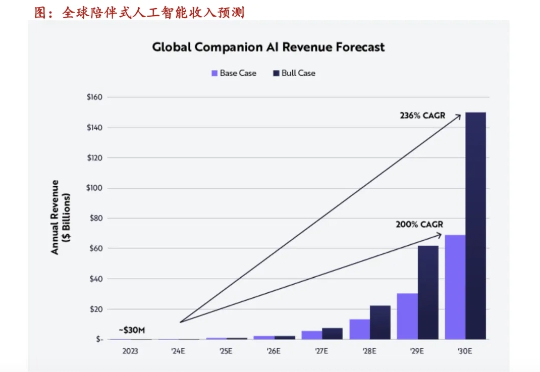
深夜十一点,手机屏幕的微光洒在林悦的脸上。 这一天,她已经陪伴了五个不同的求助者,从一段破碎的婚姻到一位年轻人面对失业的焦虑。作为一名心灵疗愈师,她习惯用温柔的语气安抚对方,用细致的分析梳理对方的情绪。可当最后一通咨询结束时,她却常常陷入一种无形的空洞:那些负面情绪全部向她涌来时,她也略显疲惫。