
离谱!马斯克的 AI 教人暗杀马斯克?Grok 37 万条聊天记录意外泄露
离谱!马斯克的 AI 教人暗杀马斯克?Grok 37 万条聊天记录意外泄露Grok 又双叒叕捅娄子了。 在用户完全不知情的情况下,马斯克旗下 AI 聊天机器人 Grok 将数十万条用户聊天记录公开发布,并被 Google 等搜索引擎全网收录。
来自主题: AI资讯
9514 点击 2025-08-21 16:51
Grok 又双叒叕捅娄子了。 在用户完全不知情的情况下,马斯克旗下 AI 聊天机器人 Grok 将数十万条用户聊天记录公开发布,并被 Google 等搜索引擎全网收录。
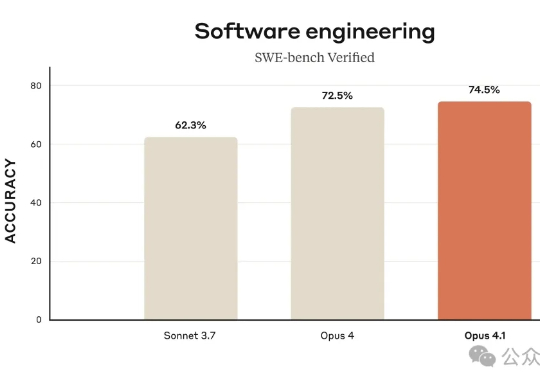
OpenAI在SWE-bench Verified编程测试中仅完成477道题却公布74.9%高分,对比之下,Anthropic的Claude完成全部500题。
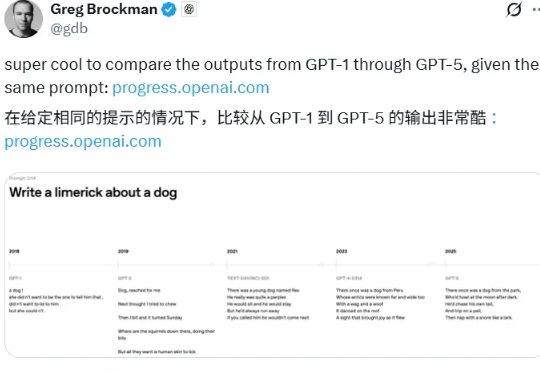
从2018年至今,GPT系列模型已经来到第五代,如果让你回忆第一次使用GPT-1时的感受,可能是一种新奇却略显笨拙的震撼,就像这样: 当你问 GPT-1:麻醉状态下,你真的有意识吗?
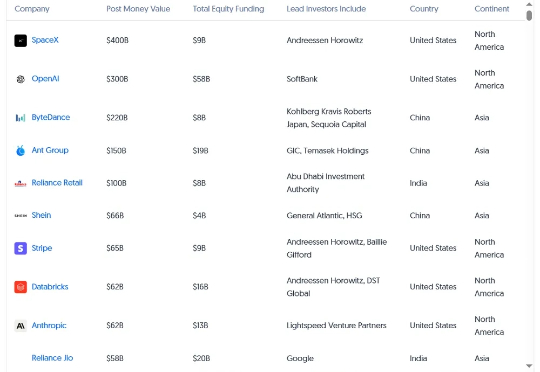
智东西8月20日报道,昨日,AI数据分析平台Databricks宣布,该公司已经签署了K轮融资的条款清单,预计将在现有投资者的支持下很快完成,这轮融资对Databricks的估值已经超过了1000亿美元(约合人民币7179.1亿元),估值与8个月前的620亿美元(约合人民币4451.0亿元)相比,上涨了超61%。

AI时代的基建狂潮来了!Anthropic联合创始人Tom Brown直言:人类正踏上一场规模超越阿波罗登月、曼哈顿计划的算力竞赛。他,曾经线代只考70多,6月自学成才,加入OpenAI打造GPT-3,创立Anthropic……一路开挂堪比韦小宝,他正是AI时代最燃的注脚!
自2024年5月谷歌推出AI Overviews(AI概览)功能以来,用户无需点击即可获取答案,这导致新闻网站和独立博主的点击量暴跌。数据显示,全球新闻网站的月自然访问量从2024年7月的23亿次骤降至2025年5月的不到17亿次
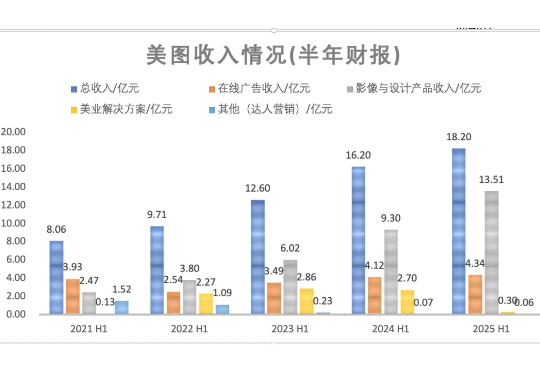
RoboNeo 拿下百万 MAU 后,美图财报依旧强势。7 月中旬,美图上线了面向影像领域的 AI Agent RoboNeo,并靠“emoji 小人”的社媒风潮获取了第一批用户,上线一个月左右的时间,已拿下 100W 左右的 MAU。美图又以极快的速度,推火了一款新产品。在 AI 时代,聚焦影像的美图,有点乘风起的意味,如其昨天发布的半年报。

虎牙Q2营收15.7亿,AI战略驱动平台实现创新转型。 8月12日,虎牙发布2025年第二季度财报。经过两年战略转型后,虎牙交出一份超越市场预期的亮眼业绩。

2011 年 8 月,雷军穿着标志性的黑 T 恤和牛仔裤,在北京 798 艺术中心发布了初代小米手机。在这款产品搅动整个智能手机行业之前,他首先用一个极具冲击力的数字定义了它——1999 元。

手机是这个问题的标准解法,但它有个悖论:为了记录生活,你必须先打断生活。掏出手机、解锁、打开相机、对焦、按下快门——这个流程本身就是对「当下」的破坏。 所以,当一个名叫 Looki L1 的 AI 硬件出现在我们面前时,我们的目标非常明确:验证它能否解决这个悖论。