
用子模优化法为DeepResearch生成多样性查询
用子模优化法为DeepResearch生成多样性查询在开发DeepResearch时,生成多样化的查询 (query) 是一个关键细节。我们在开发时会在至少两处遇到这个问题。
来自主题: AI技术研报
10549 点击 2025-07-07 15:25
 搜索
搜索
在开发DeepResearch时,生成多样化的查询 (query) 是一个关键细节。我们在开发时会在至少两处遇到这个问题。

1997 年,AI 正处于第二次寒冬,这次寒潮的时间有点长,从 20 世纪 90 年代直至 21 世纪的第一个十年。

你有没有想过,一家只有四个员工的公司,能做到年收入600万美元?这听起来像是天方夜谭,但 Oleve 正在让这个看似不可能的故事成为现实。我最近深入研究了这家由 Sid Bendre 领导的创业公司,发现了一个令人震撼的事实:他们不仅实现了这个惊人的财务数据,还在短短两年内服务了超过500万用户,从第九个月开始就实现了盈利。

当 VC 还在计算估值模型时,似乎产线已经给出了更诚实的投票。
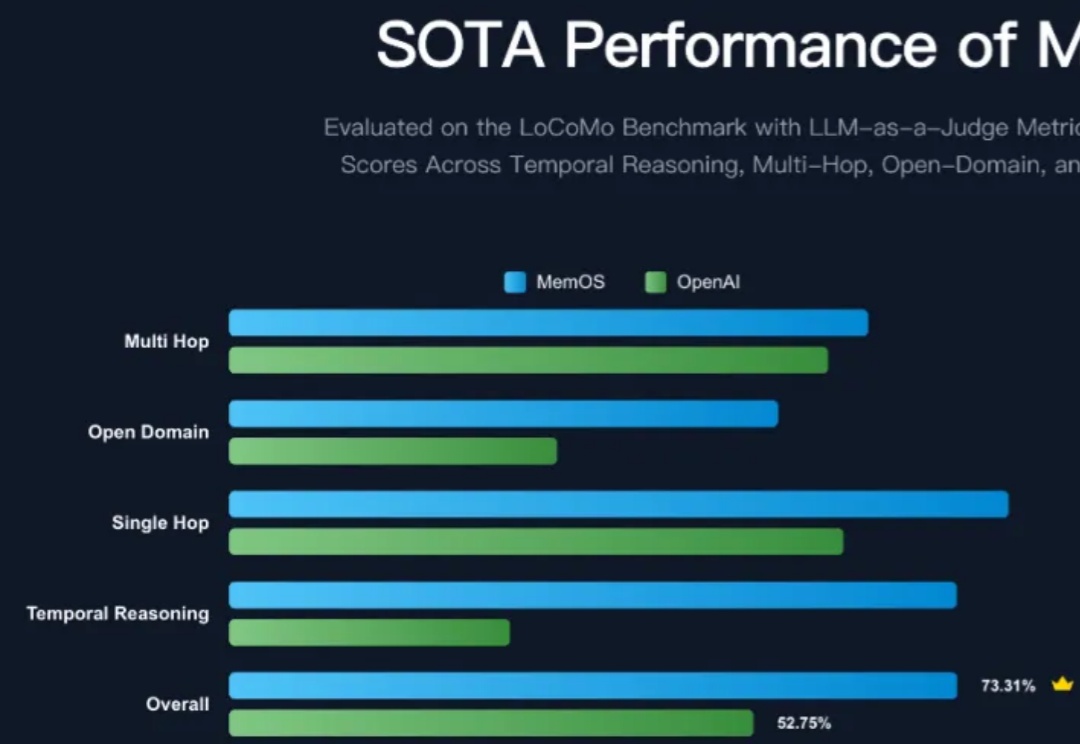
大模型记忆管理和优化框架是当前各大厂商争相优化的热点方向,MemOS 相比现有 OpenAI 的全局记忆在大模型记忆评测集上呈现出显著的提升,平均准确性提升超过 38.97%,Tokens 的开销进一步降低 60.95%,一举登顶记忆管理的 SOTA 框架,特别是在考验框架时序建模与检索能力的时序推理任务上,提升比例更是达到了 159%,相当震撼!

好用到让我有点儿不敢用了……
Stream-Omni:同时支持各种模态组合交互的文本-视觉-语音多模态大模型

在生成式 AI 的汹涌浪潮里,“让技术奔跑得更快”似乎已成行业共识;而无障碍领域一直关心的是另一端——“让每个人都跟得上”。当这两股力量在今年的第七届科技无障碍发展大会(2025 TADC)相遇,一场以“AI+无障碍:探索、实践”为主题的圆桌会议吸引了全场目光。

作为一名科技内容创作者,我的日常就是追踪最新的技术和商业进展。
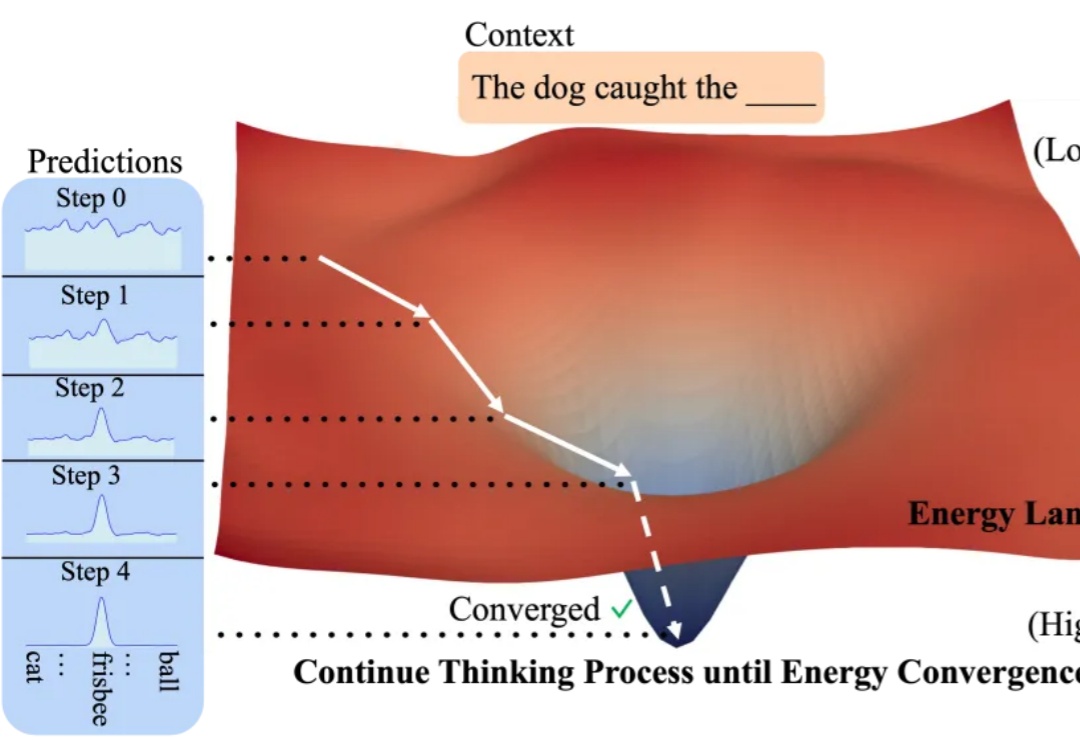
是否可以在不依赖额外监督的前提下,仅通过无监督学习让模型学会思考? 答案有了。