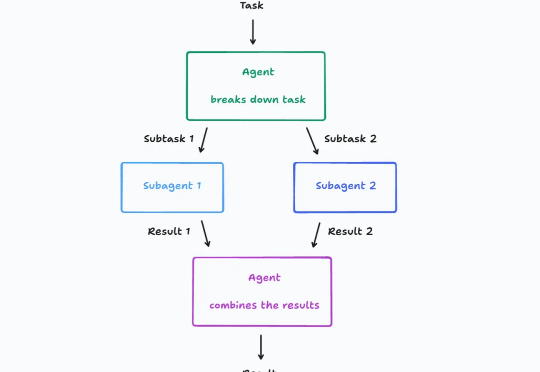
多智能体到底该不该建?Anthropic、Cognition 与 LangChain 的三种解法
多智能体到底该不该建?Anthropic、Cognition 与 LangChain 的三种解法大模型驱动的 AI 智能体(Agent)架构最近讨论的很激烈,其中一个关键争议点在于: 多智能体到底该不该建?
来自主题: AI技术研报
11416 点击 2025-06-25 10:03
 搜索
搜索
大模型驱动的 AI 智能体(Agent)架构最近讨论的很激烈,其中一个关键争议点在于: 多智能体到底该不该建?
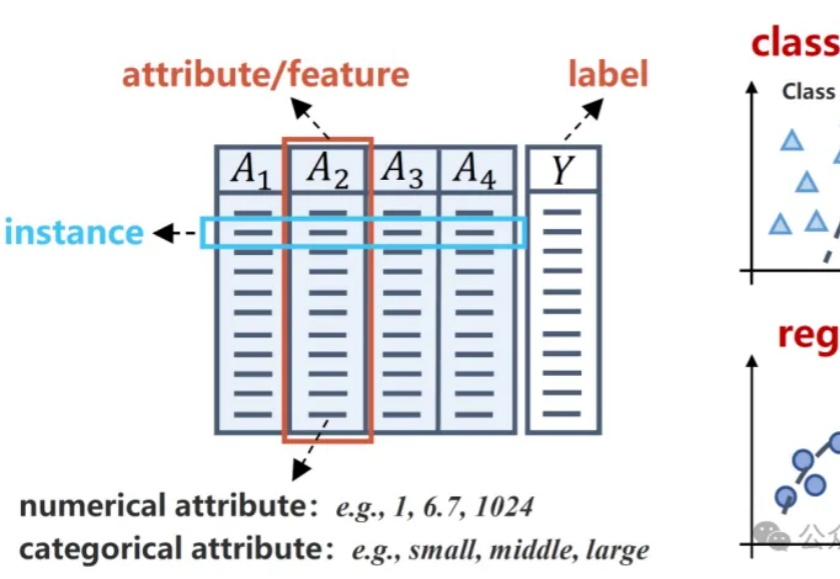
在AI应用中,表格数据的重要性愈发凸显,广泛应用于金融、医疗健康、教育、推荐系统及科学研究领域。
本文第一作者为韩沛煊,本科毕业于清华大学计算机系,现为伊利诺伊大学香槟分校(UIUC)计算与数据科学学院一年级博士生,接受 Jiaxuan You 教授指导。
今天,Gemini 家族迎来了一个新成员:Gemini Robotics On-Device。这是谷歌 DeepMind 首个可以直接部署在机器人上的视觉-语言-动作(VLA)模型,可以帮助机器人更快、更高效地适应新任务和环境,同时无需持续的互联网连接。

6月23日,山西临汾市人民医院发布了《基于DeepSeek AI大模型的智慧医疗应用系统建设项目》,预算金额为1569.264万元,预计采购时间为2025年9月。临汾市人民医院拟采购基于DeepSeek的智慧医疗项目建设一套,其建设内容包含:

你能想象吗?一个在立陶宛车库里诞生的创业项目,仅仅一年时间就做到了 1200 万美元的年收入,服务超过 4 万家付费客户,遍布全球 100 多个国家。更令人震惊的是,它的创始人 Chris Sidlauskas 在创立 Sintra 时才 22 岁,而他的联合创始人 Rokas Judickas 甚至更年轻。
法律工作自动化初创公司Harvey AI 向《财富》透露,已在 E 轮融资中筹集 3 亿美元,估值达到 50 亿美元。

618期间,一款刚推出不到两周的儿童AI硬件登顶了京东婴幼童玩具618累计竞速榜首。同样在榜的,是频繁刷屏的 Haivivi ,以及朱啸虎投的Fuzozo。

具身智能商业闭环的核心,是开发者。
如果你有一个想法,你现在不缺程序员了。