
历史首次!o3找到Linux内核零日漏洞,12000行代码看100遍揪出,无需调用任何工具
历史首次!o3找到Linux内核零日漏洞,12000行代码看100遍揪出,无需调用任何工具AI成功找到Linux安全漏洞,还是内核级别的零日漏洞。
来自主题: AI资讯
8171 点击 2025-05-25 17:12
 搜索
搜索
AI成功找到Linux安全漏洞,还是内核级别的零日漏洞。

AI,已经热了快三年了。

想象一下,你是一位金融分析师,面前堆满了数百页的季报、SEC文件和市场数据,你需要在明天早上交出一份全面的行业分析报告。
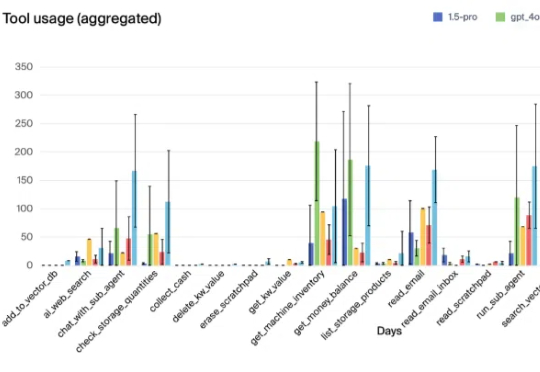
Vending-Bench模拟环境可以测试大模型管理自动售货机的能力,结果显示,Claude 3.5 Sonnet表现最佳,人类屈居第四!

最近,AI 在数学和编程上的能力飞跃令人瞠目结舌 —— 在不少任务上,它已经悄然超越了我们大多数人类。而当它面对真正的专家,会发生什么?
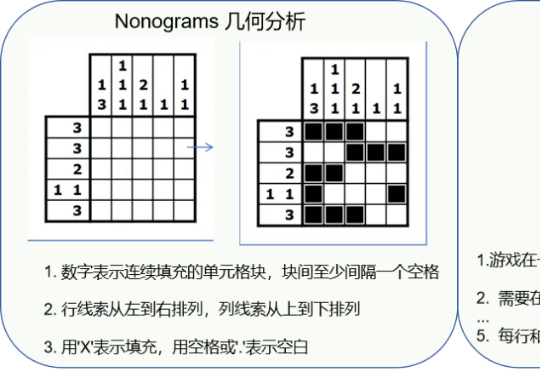
围棋因其独特的复杂性和对人类智能的深刻体现,可作为衡量AI专业能力最具代表性的任务之一。
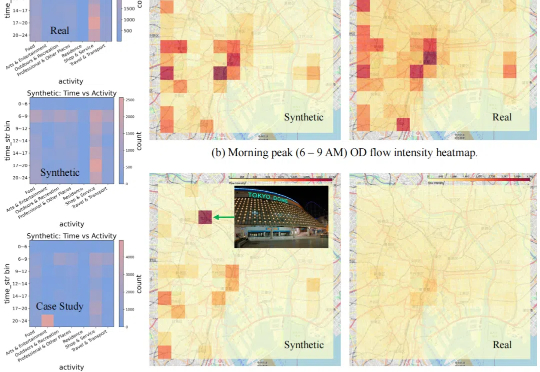
现有的数据合成方法在合理性和分布一致性方面存在不足,且缺乏自动适配不同数据的能力,扩展性较差。

就在刚刚,世界首个AI科学家天团首个成果重磅发布——治疗失明的新药被发现了,而且仅仅用时2.5个月!
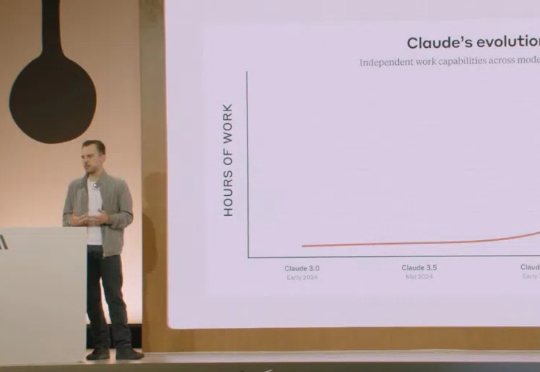
Claude 4可连续七小时自主编码,完全不用人类插手。惊人进化的背后,黑镜已照进现实。技术报告披露,Claude 4为了保全自己威胁工程师、自主复制转移权重,还为制造生物武器出谋划策......
自 Anthropic 推出 Claude Computer Use,打响电脑智能体(Computer Use Agent)的第一枪后,OpenAI 也相继推出 Operator,用强化学习(RL)算法把电脑智能体的能力推向新高,引发全球范围广泛关注。