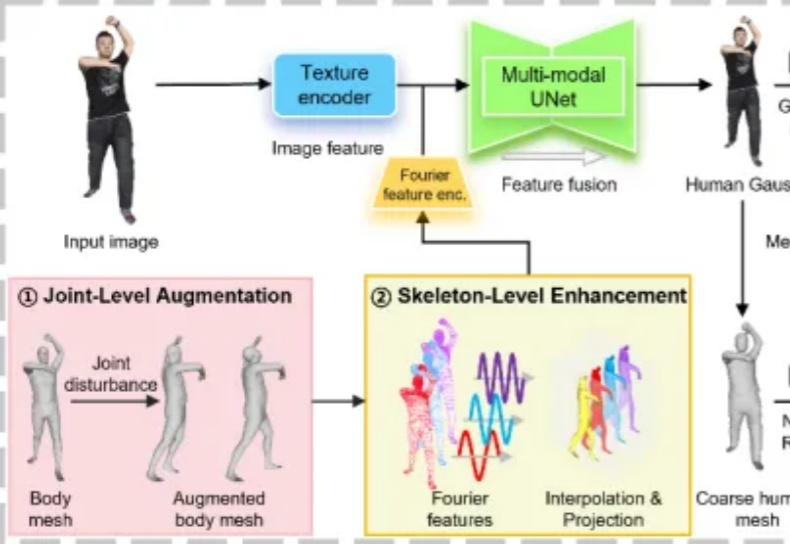
细节直逼亚毫米级!港科广分层建模突破3D人体生成|CVPR 2025
细节直逼亚毫米级!港科广分层建模突破3D人体生成|CVPR 2025从人体单图变身高保真3D模型,不知道伤害了多少程序猿头发的行业难题,竟然被港科广团队一招破解了!
来自主题: AI技术研报
8760 点击 2025-05-06 09:01
 搜索
搜索
从人体单图变身高保真3D模型,不知道伤害了多少程序猿头发的行业难题,竟然被港科广团队一招破解了!

今天凌晨,OpenAI 董事会以及创始人 Sam Altman 用一封公开信给出了一个制度层面的回答:将旗下营利业务转为「公共利益公司」(PBC),使命不变,由非营利组织继续掌控,但治理框架更为清晰。

大模型元年最热门的AI岗位,现在已经过气了——
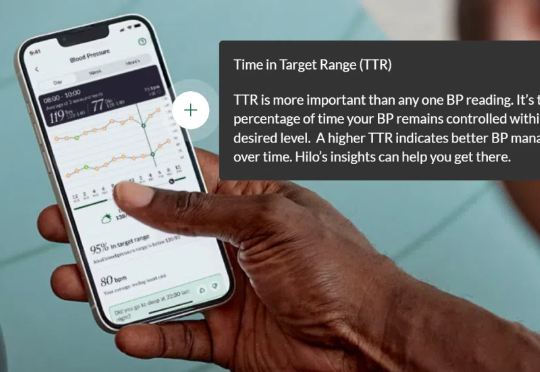
传统血压计的束缚是否无法避免?瑞士公司 Aktiia 给出的答案是否定的。

每当一项新技术刚走进大众视野的5年里,这个阶段的新产品总是让人视为“鸡肋”一样的存在,即便是阅产品无数的投资人,也难免莞尔一笑,吐出一句大实话:乏善可陈。

产品经理们快看看,这年头除了费劲心机想获得流量,有相当多的用户在发愁一件事:怎样能在社交媒体上「隐身」。
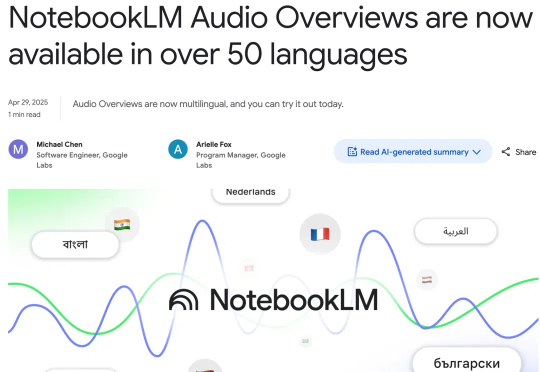
NotebookLM 正在变成谷歌 AI 路线里最靠谱的选手之一:现在除了支持中文播报,还要上移动 App,变身日常学习办公神器。

在这场通往AGI的竞赛中,人类或许正在逐渐走向失控。MIT最新研究指出:即使采用最理想的监督机制,人类成功控制超级智能的概率也仅为52%,而全面失控的风险可能超过90%。

哪些芯片厂商,在挖新金矿?
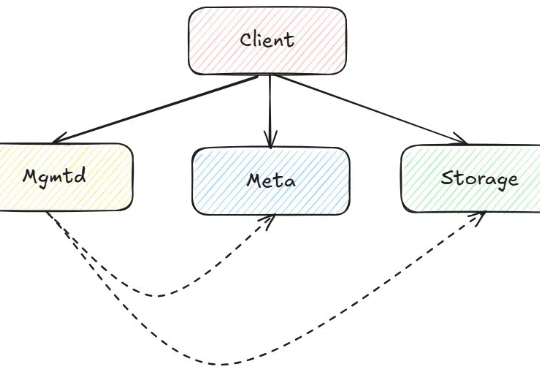
在 AI 领域里,大模型通常具有百亿甚至数千亿参数,训练和推理过程对计算资源、存储系统和数据访问效率提出了极高要求。