
对话清华赵昊:物理AI,胜负关键在4D可控的世界模型基模
对话清华赵昊:物理AI,胜负关键在4D可控的世界模型基模今天,世界模型几乎成为 AI 领域最受关注的话题之一,但对于“什么才是真正的世界模型”却依然存在巨大分歧。有人认为它只是视频生成的延伸,也有人认为只有能够理解物理规律、支持机器人行动的系统才是真正的世界模型。
来自主题: AI资讯
8627 点击 2026-07-23 11:02
 搜索
搜索
今天,世界模型几乎成为 AI 领域最受关注的话题之一,但对于“什么才是真正的世界模型”却依然存在巨大分歧。有人认为它只是视频生成的延伸,也有人认为只有能够理解物理规律、支持机器人行动的系统才是真正的世界模型。
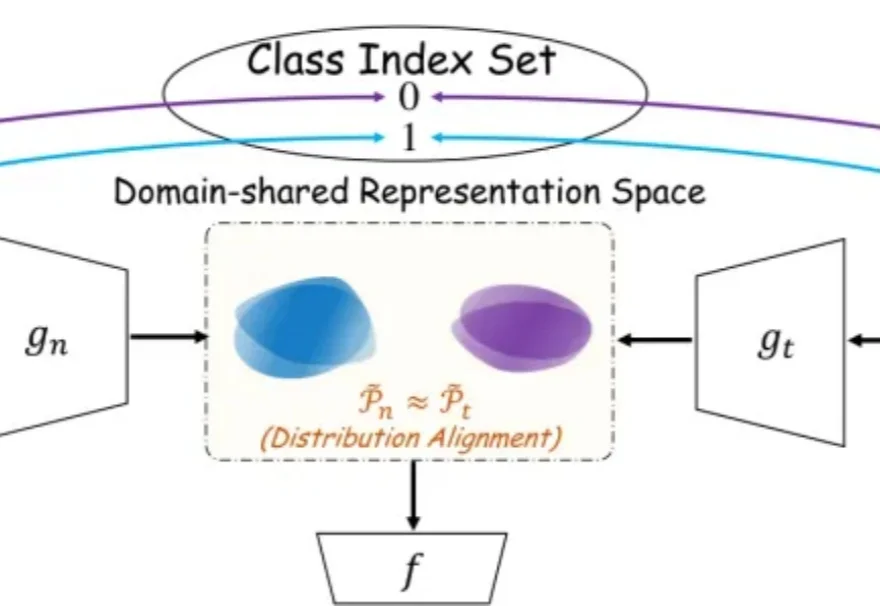
迁移学习里的“源数据”,未必非得是图像、文本或音频。
「帮我把这10万字速记整理一下。」

7 月的上海,世博展览馆 H3 馆的过道比往年拥挤许多。 入口处停着宇树的载人变形机甲 GD01,观众排队坐进驾驶舱拍照。往里走,300 多台机器人真机散在 200 多家具身智能企业的展台之间,具身智
7月19日,讯飞AI大学堂在这里宣布正式升级。新方向定为"From Learning AI to AI Learning"。从学习AI技术,转向AI赋能学习。讯飞AI大学堂,是科大讯飞旗下国内首个AI在线学习平台,成立于2017年。这里汇聚了AI领域众多开发者、爱好者、从业者,他们在这里完成AI学习、交流、培训。

一夜之间,Tokenmaxxing成为硅谷热议话题!

走进一家大型汽车制造商的线束车间,你会看到和整车工厂截然不同的画面。

交互式视频世界模型正在从「一次性生成短片」走向「像游戏一样边操作边生成」。但长轨迹交互会迅速放大上下文、显存和多步去噪开销。Light Interaction不改模型参数、不重新训练,只在推理阶段把相机轨迹变成调度信号,动态选择历史上下文、在回访状态复用去噪输出,并用面向自回归生成的3D稀疏注意力降低计算。
炒股到现在最对不起的,就是家人。

商业地图可以告诉机器人「前方右转」,却无法直接告诉它眼前应该从哪里转、沿哪一侧通过;即使已经生成路线,控制误差、地面变化和动态障碍,也可能让机器人在行进过程中逐渐偏离。