
ChatGPT聊天记录成法庭铁证,韩国汽车旅馆双命案反转
ChatGPT聊天记录成法庭铁证,韩国汽车旅馆双命案反转一段与ChatGPT的普通聊天,揭开韩国汽车旅馆连环谋杀案真相。
来自主题: AI资讯
5704 点击 2026-04-07 10:30
 搜索
搜索
一段与ChatGPT的普通聊天,揭开韩国汽车旅馆连环谋杀案真相。
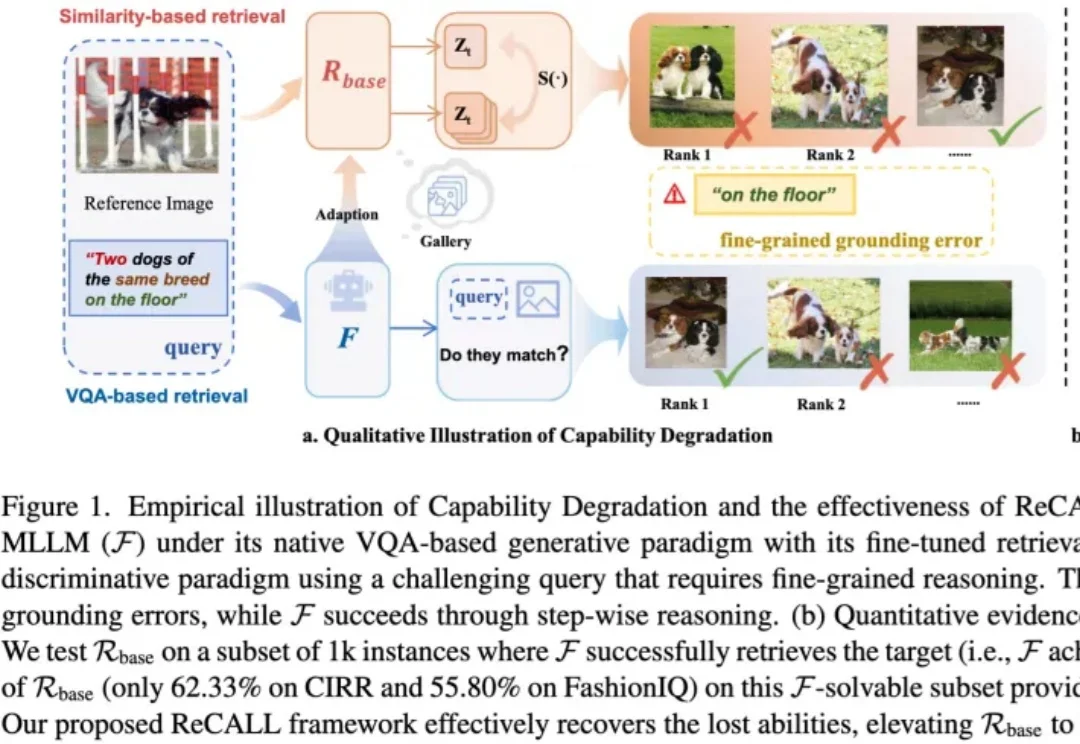
生成式模型当检索器大材小用效果还不好?
OpenAI 加快了迈向下一 AI 阶段的进程。
刚刚,Anthropic年收入首超OpenAI!同时就在今天,一份与谷歌、博通最新合作,将在2027年上线3.5 GW全新TPU集群。这批史诗级的算力,预计从2027年开始陆续上线。
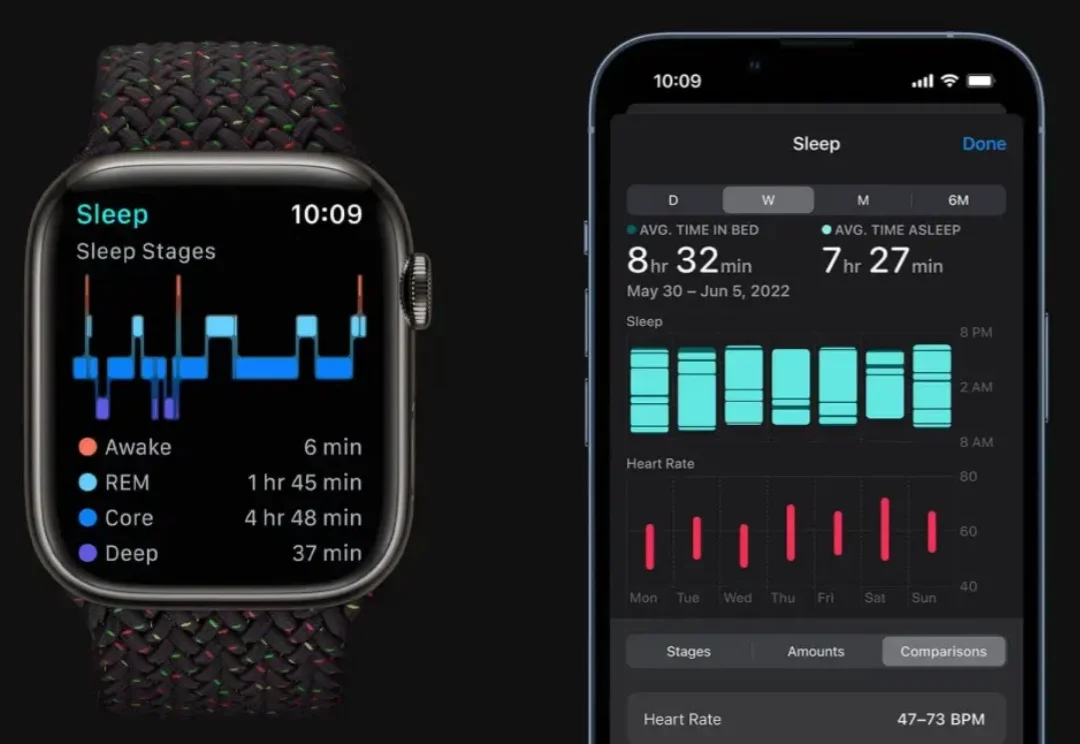
通过一晚上的睡眠,AI 模型就能监控最多 130 种疾病。

OpenAI Codex 团队的产品规格文档只有 10 个要点。不是说每个功能的文档只有 10 个要点,而是整个产品的 spec 就这么多。设计师写的代码量超过了六个月前工程师写的。50 到 100 人的团队,直到最近才有了第二个产品经理。

《读佳》了解到,支付宝正在内测名为“aclaw”的AI产品,定位为“不懂代码,也能云养虾”。内嵌在支付宝APP中,这款新品的亮相,也让支付宝在 AI 领域的布局再添新动作。
老粉都知道,我们团队一直坚持“小而美”,满打满算也才九个人,所以腾不出多余的人手来负责美工工作。

许多长期与文字和代码打交道的创作者,应该对 Obsidian 这款软件并不陌生。作为目前全球最具影响力的本地化 Markdown 笔记应用之一,它凭借独树一帜的知识图谱和开源生态,在知名度与用户忠诚度上,已然能与 Notion 分庭抗礼。
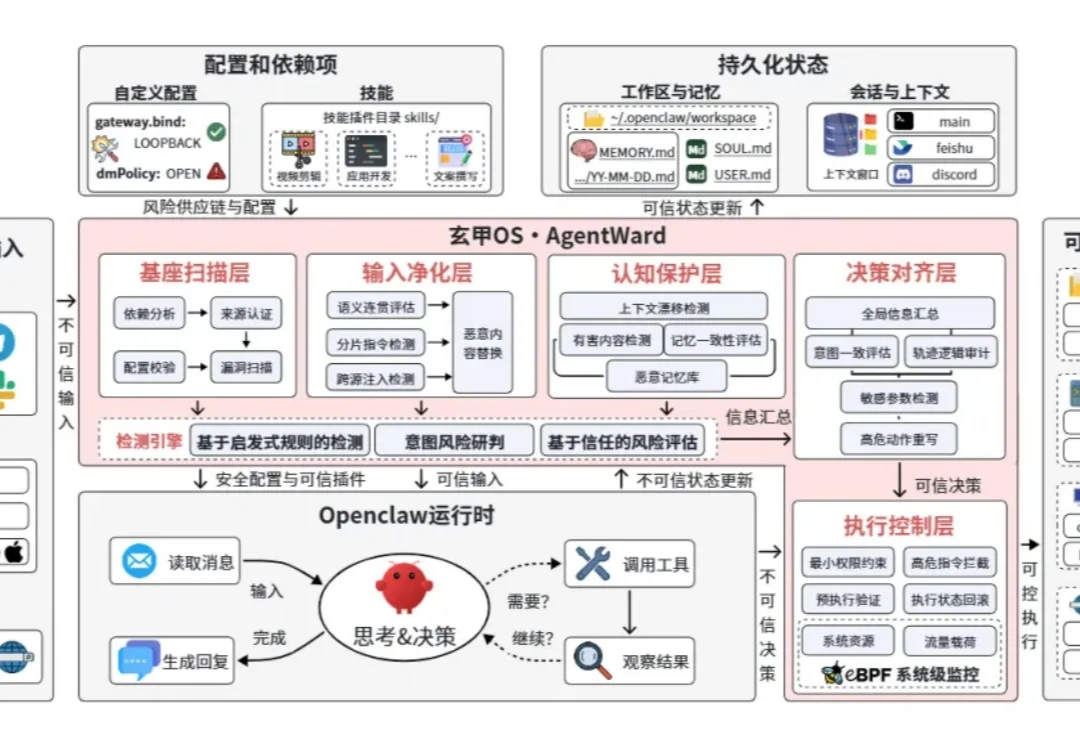
大模型技术正在经历一场从 “对话助手” 向 “自主智能体(Agent)” 的深刻演进。智能体不再局限于被动地理解与生成,而是具备了多步规划、工具调用、长期记忆与管理物理 / 数字世界的能力,正逐步深度嵌入企业侧的核心业务流程。这意味着,AI 的边界已从虚拟屏幕的对话框,正式延伸到了真实的生产系统中。