
刚刚,千问杀入汽车座舱!阿里不止做超级APP,更要做超级入口
刚刚,千问杀入汽车座舱!阿里不止做超级APP,更要做超级入口就在刚刚,阿里AI助手千问被接入红旗汽车智能座舱!这是通用AI助手首次以「完整形态」登陆车载场景。随着逐步打通PC、手机、智能眼镜与汽车等终端,阿里正在把千问打造为AI时代的超级入口,而不仅仅是一款超级APP。
来自主题: AI资讯
8191 点击 2026-03-26 14:50
 搜索
搜索
就在刚刚,阿里AI助手千问被接入红旗汽车智能座舱!这是通用AI助手首次以「完整形态」登陆车载场景。随着逐步打通PC、手机、智能眼镜与汽车等终端,阿里正在把千问打造为AI时代的超级入口,而不仅仅是一款超级APP。

软硬协同决定成败。

从「被动感知」到「主动预测」,首个视触觉世界模型让机器人真正学会「理解接触」。

3月24日,Anthropic宣布Claude引入“Computer Use”能力,在Claude Cowork和Claude Code中,Claude可以直接操作用户的Mac电脑:打开文件、使用浏览器、运行开发工具,无需任何配置。该功能以研究预览版形式向Pro和Max订阅用户开放。
AI带来最大的惊喜,是帮助你完成很多梦。
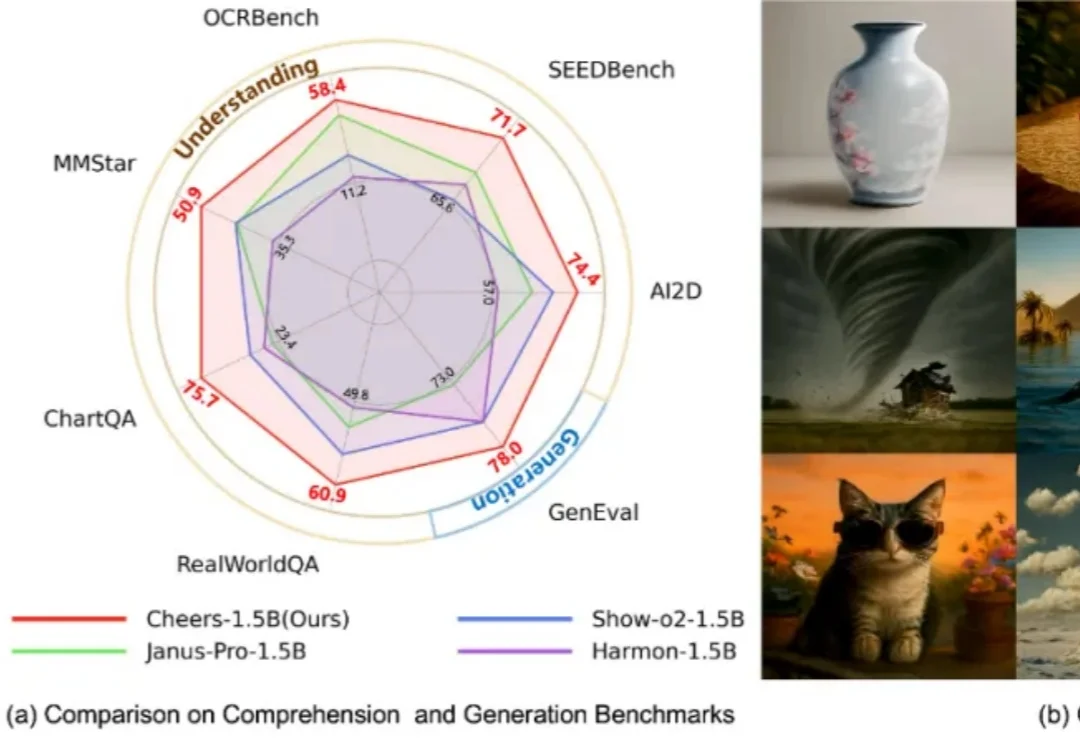
过去几年,多模态模型在理解任务上快速演进,图像问答、OCR、视觉推理、跨模态对话等能力不断提升;与此同时,图像生成模型也在视觉质量、指令遵循和细节表达上持续突破。下一步一个自然的问题是:能否用同一个模型,同时做好理解与生成?这正是统一多模态模型(Unified Multimodal Models, UMMs)正在回答的问题。

一次只持续了不到1小时的投毒事件,撕开了AI基础设施「信任链」的致命裂缝。更魔幻的是,全行业逃过一劫,居然靠黑客自己写出bug。
这两天,字节跳动开源了一个 Agent 产品,直接炸了。

想象一下这样的生活片段:你拿起手机 30 秒,屏幕立刻跳出提醒,“当前心率 78,压力中等,建议深呼吸”;家里的智能摄像头静静看着午睡的宝宝,突然通过 App 提醒你:“宝宝心率偏快,呼吸略显急促,建议进屋查看”;养老院里,巡检机器人通过一次擦身而过的对视,便能感知到老人今天情绪低落,且血氧饱和度略低于往常......

中国是NeurIPS最大的「粮仓」,却被新规一刀切断。CCF回应只有一句话:全体中国计算机领域科学家拒绝为其服务!更狠的还在后面:如不纠正错误,直接移出CCF推荐目录。