
龙虾产品五花八门,我们帮你分分类
龙虾产品五花八门,我们帮你分分类随着龙虾OpenClaw热潮持续,复杂的云端部署已经无法满足用户的需求,尤其是最近两周,涌现出了大量在原OpenClaw基础上定制的新产品,其中很多已经实现了应用化,用户只需要点击下载注册应用就能够体验OpenClaw的部分功能。
来自主题: AI资讯
6415 点击 2026-03-17 09:27
 搜索
搜索
随着龙虾OpenClaw热潮持续,复杂的云端部署已经无法满足用户的需求,尤其是最近两周,涌现出了大量在原OpenClaw基础上定制的新产品,其中很多已经实现了应用化,用户只需要点击下载注册应用就能够体验OpenClaw的部分功能。
这是自我实现的过程,这是 “无限游戏”。

AI竞赛,已经踩下油门,开始全力冲刺!2026下半年,三巨头OpenAI、谷歌DeepMind、Anthropic将甩开所有人,递归自我改进的引擎已点火。接下来六个月,人类文明或将永久改写。
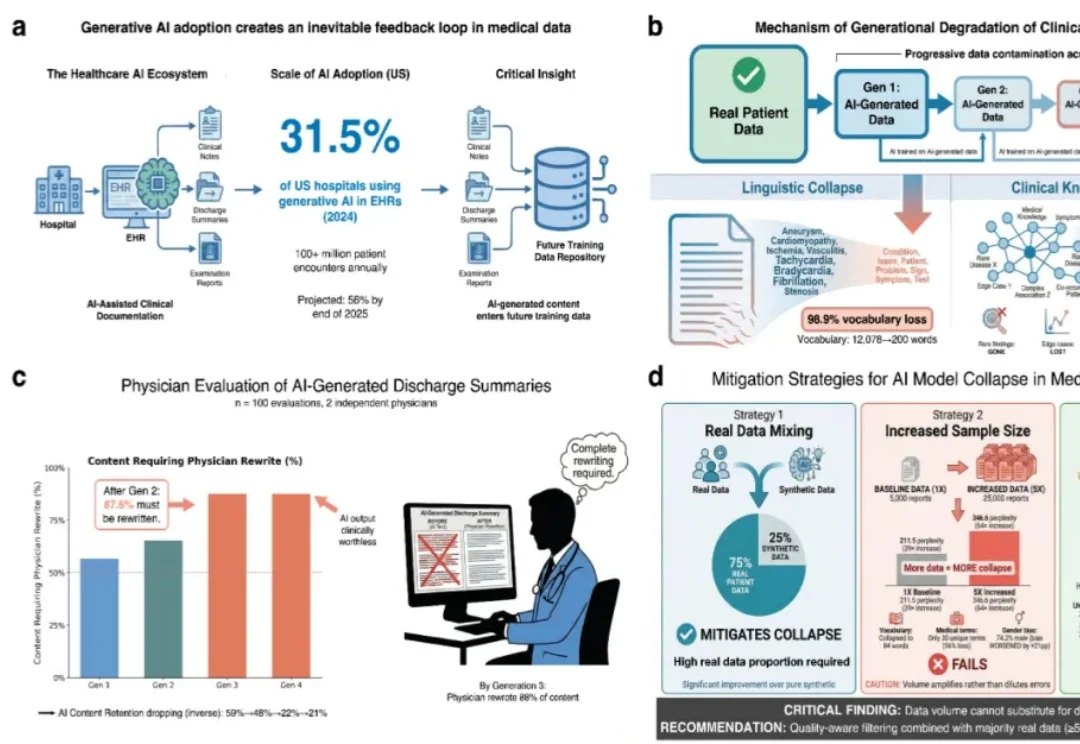
随着生成式人工智能在医疗领域的加速渗透,越来越多的病历、影像报告及各类临床文本正逐步纳入 AI 参与生成的范畴。这一旨在提升医疗效率的技术革新背后,潜藏着威胁诊断安全性的深层隐患。
当AI的生成能力逐渐成为标配时,设计AI的竞争核心已不再是谁更会出图,而是谁能真正接管设计师从创意沟通到商业落地的完整工作流,将设计、协同与产业生态整合成一个无缝的系统。这预示着一场范式转移,而最近发布的暗壳AI Agent2.0,或将成为万亿人居产业的生态破局者。
最近几年,大模型赛道好不热闹。

七天时间,从神坛到凡间,从泡沫到实用。

朋友们,你们是不是也这样: 遇到问题,打开ChatGPT,噼里啪啦打一堆提示词,它给你生成一段代码、一个方案,然后呢?
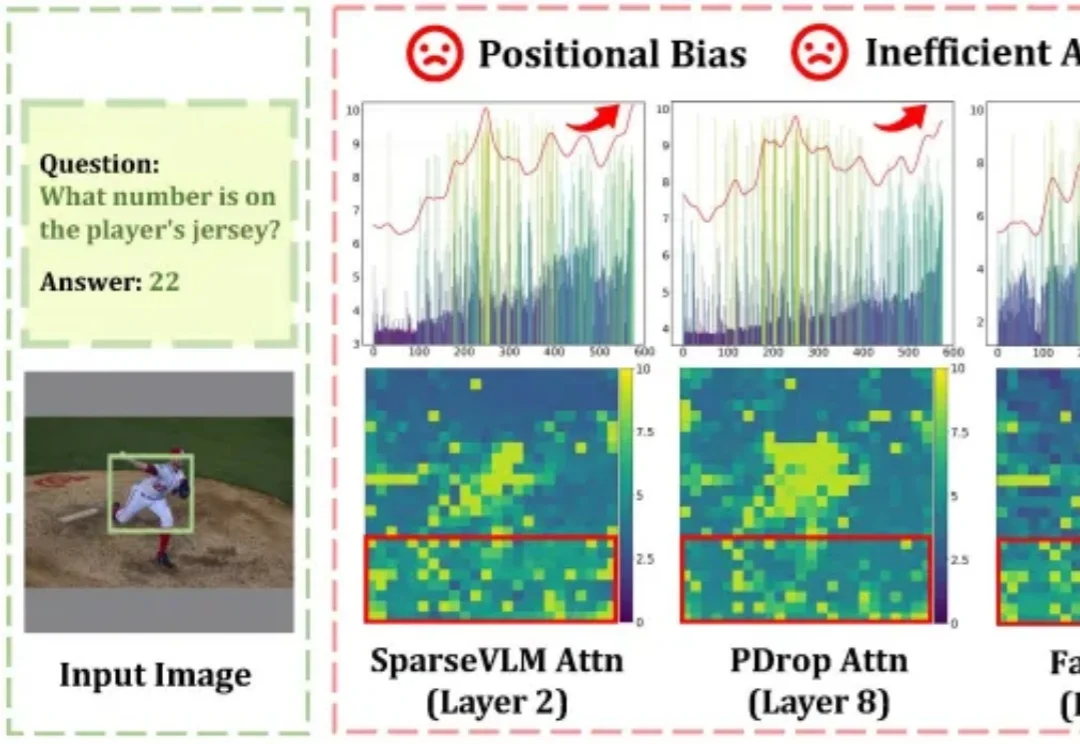
随着高分辨率图像理解与长视频处理需求的爆发式增长,大型视觉语言模型(LVLMs)所需处理的视觉 Token 数量急剧膨胀,推理效率成为落地部署的核心瓶颈。Token 压缩是缩短序列、提升吞吐的直接手段,但现有方法普遍依赖注意力权重来判断 Token 重要性,这一路线暗藏两个致命缺陷:
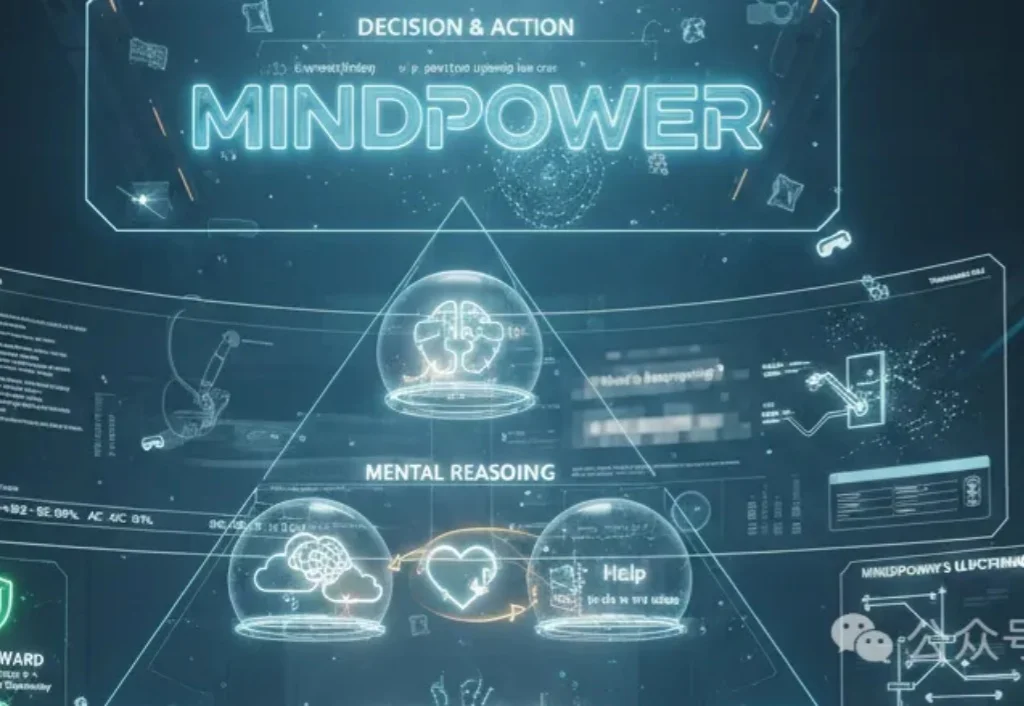
吉林大学&微软亚洲研究院等团队提出MindPower框架,让机器人像人一样理解他人想法并主动帮忙,构建了首个以机器人为中心的心智推理评测体系,通过六层推理链条,让AI不仅看懂场景,更能推断意图、做出决策、执行动作,显著提升助人能力。