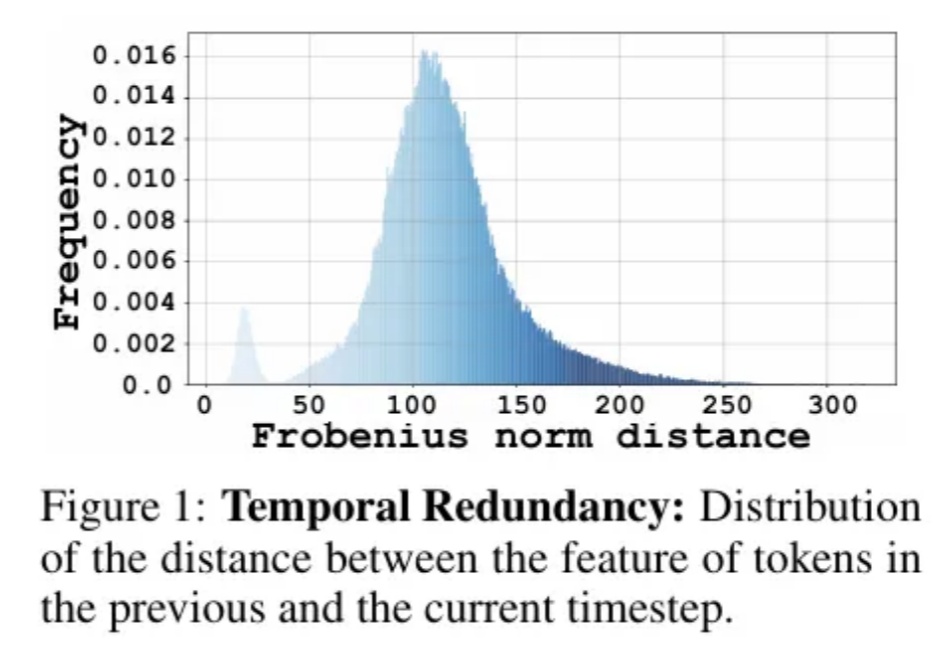
无需训练让扩散模型提速2倍,上交大提出Token级缓存方案|ICLR‘25
无需训练让扩散模型提速2倍,上交大提出Token级缓存方案|ICLR‘25Diffusion Transformer模型模型通过token粒度的缓存方法,实现了图像和视频生成模型上无需训练的两倍以上的加速。
来自主题: AI技术研报
5978 点击 2025-02-28 15:06
 搜索
搜索
Diffusion Transformer模型模型通过token粒度的缓存方法,实现了图像和视频生成模型上无需训练的两倍以上的加速。

几乎所有人都已经发现,我们正生活在一场前所未有的信息革命之中。

RISC-V 正在成为 AI 原生计算架构。

随着 AI 能力的提升,一个常见的话题便是基准不够用了——一个新出现的基准用不了多久时间就会饱和,比如 Replit CEO Amjad Masad 就预计 2023 年 10 月提出的编程基准 SWE-bench 将在 2027 年饱和。
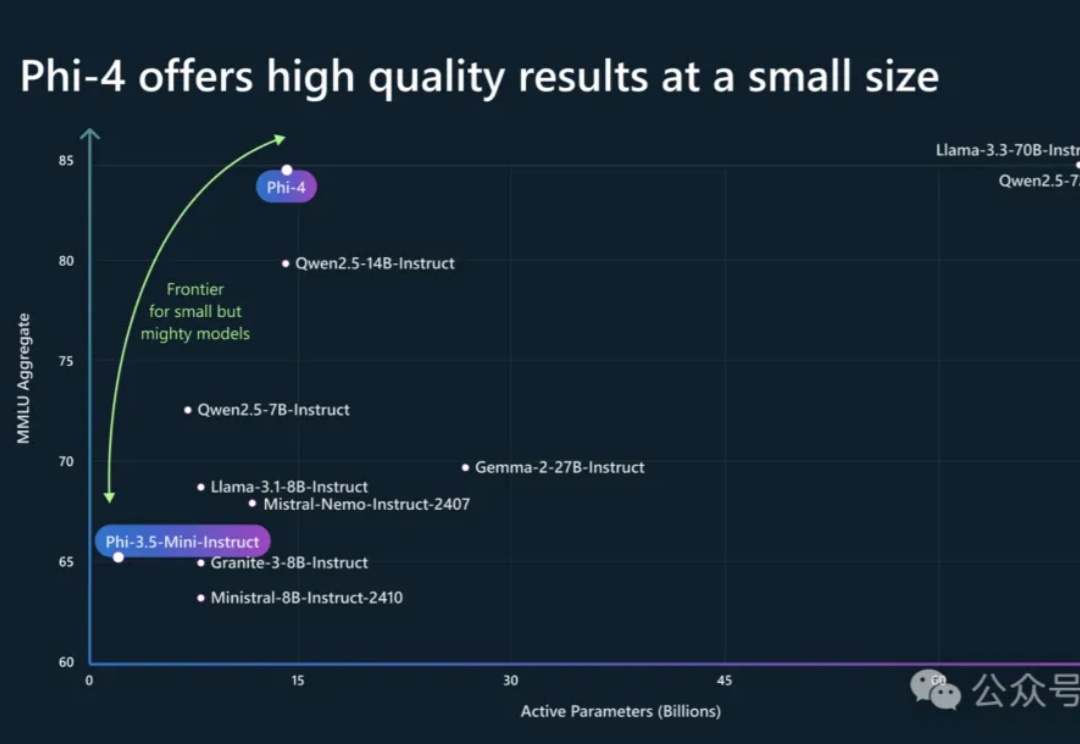
Phi-4系列模型上新了!56亿参数Phi-4-multimodal集语音、视觉、文本多模态于一体,读图推理性能碾压GPT-4o;另一款38亿参数Phi-4-mini在推理、数学、编程等任务中超越了参数更大的LLM,支持128K token上下文。
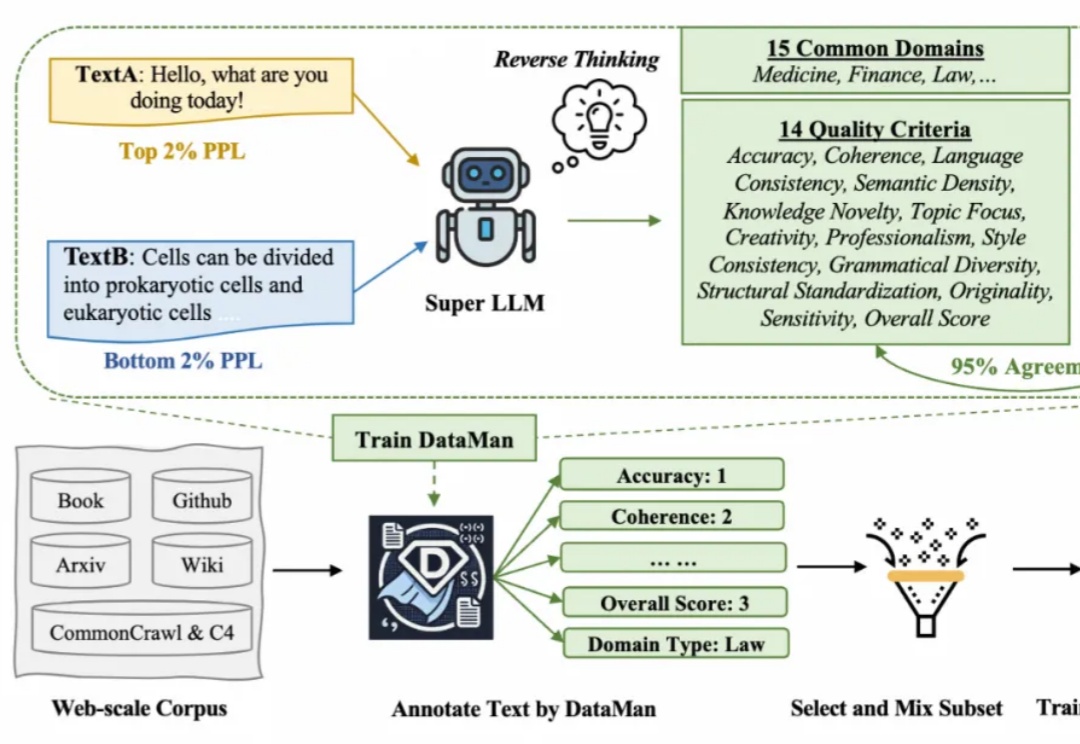
在 Scaling Law 背景下,预训练的数据选择变得越来越重要。然而现有的方法依赖于有限的启发式和人类的直觉,缺乏全面和明确的指导方针。在此背景下,该研究提出了一个数据管理器 DataMan,其可以从 14 个质量评估维度对 15 个常见应用领域的预训练数据进行全面质量评分和领域识别。

“用DeepSeek写小说,一天能写20万字”

AI模型的训练和推理成本在过去18个月内大幅下降,达到180倍的成本降低。这一趋势推动了更多开源项目的涌现。

DeepSeek开源周的最后一天,迎来的是支撑其V3/R1模型全生命周期数据访问需求的核心基础设施 — Fire-Flyer File System(3FS) 和构建于其上的Smallpond数据处理框架。

GPT-4.5正式发布,号称OpenAI最大和最好的聊天模型。