全球首款手机龙虾app,来了!
全球首款手机龙虾app,来了!手机养龙虾自由,被百度实现了!
来自主题: AI资讯
6424 点击 2026-03-12 11:54
 搜索
搜索
手机养龙虾自由,被百度实现了!

获投近亿元、两周开发“中国版小龙虾”,前阿里腾讯大厂人二次创业。

谁能想到,OpenClaw 火到了今天,甚至出现了排队等待安装的盛况。一些大厂也开始入局,选择接入 OpenClaw。龙虾热已经发展为现象级,但问题是:究竟有多少行业能够真正将其投入使用呢?
如果你在三月 5 号左右的凌晨,打开亚马逊,可能会怀疑自己输错了网址——满屏都是各种小狗图,和巨大的「Sorry」。
在「龙虾热」蔓延全国的此刻,大家把越来越多的工作交给 AI。从写代码到数据分析,很多人开始尝试让 AI 接管完整流程。

OpenClaw太耗token,要烧光全球算力?追觅科技的答案是,把算力送上太空!200万颗的算力卫星,直接碾压了马斯克的SpaceX。不仅如此,他们也开始下场做芯片了。

嗨大家好!我是阿真! 前几天发过提示词生图相关的推文,大家普遍有个痛点,直接生成但是写提示词很痛苦,提示词调整来调整去,有点小问题又想再抽卡,最后时间浪费了,效果也一般般。
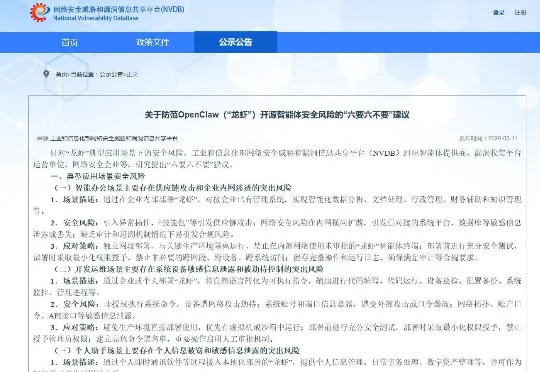
针对“龙虾”典型应用场景下的安全风险,工业和信息化部网络安全威胁和漏洞信息共享平台(NVDB)组织智能体提供商、漏洞收集平台运营单位、网络安全企业等,研究提出“六要六不要”建议。

Ben在视频中提到了一个令人震惊的数据对比。虽然ChatGPT的使用率在飞速增长,企业也在疯狂尝试各种AI解决方案,但真正能看到商业价值的却少之又少。根据MIT的研究,在供应商销售的AI解决方案中,只有5%的试点项目最终进入了生产环境。Deloitte(德勤)发现只有15%的组织表示他们从AI中获得了显著的、可衡量的ROI。
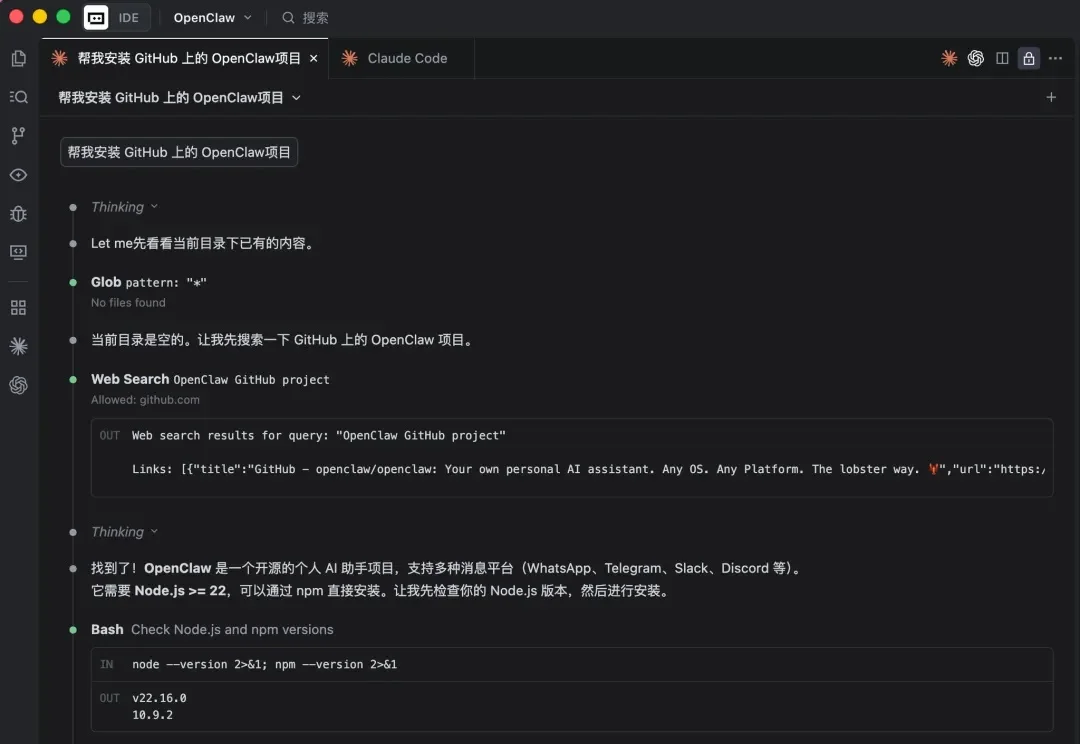
这几天,「养虾」成了全网最火的关键词。