
最强黑客大模型,不再是Mythos
最强黑客大模型,不再是Mythos微软用一套多 Agent 系统在 AI 漏洞发现的顶级基准测试上拿下第一,超过 Anthropic 最强模型 Mythos 五个百分点。诡异的是,微软自己并没有一个能打的前沿模型。它用别人的模型组了个系统,打败了造出这些模型的公司。这对AI竞争格局的启示,比这个工具挖出了大量 Windows 漏洞本身更重要。
来自主题: AI资讯
7779 点击 2026-05-15 13:34
 搜索
搜索
微软用一套多 Agent 系统在 AI 漏洞发现的顶级基准测试上拿下第一,超过 Anthropic 最强模型 Mythos 五个百分点。诡异的是,微软自己并没有一个能打的前沿模型。它用别人的模型组了个系统,打败了造出这些模型的公司。这对AI竞争格局的启示,比这个工具挖出了大量 Windows 漏洞本身更重要。

LeCun念叨了好几年的JEPA,被160行代码给复刻了。GitHub上有个开发者,用极简单文件形式,用PyTorch把JEPA核心系列全部实现了一遍,从I-JEPA到LeWorldModel,五个变体一个没落,就为了——
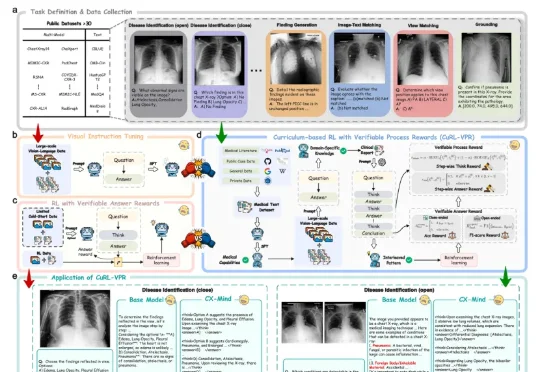
上海交通大学、上海创智学院与瑞金医院联合发布的CX-Mind,是目前首个将胸片诊断推进为「可验证推理链」的多模态大模型——从看到异常,到解释为什么、排除了什么、结论怎么来的,每一步都有影像证据支撑。

今天凌晨,俄勒冈州立大学杰出教授(荣休)、arXiv 计算机科学分区 CoRR 的机器学习板块首席版主 Thomas G. Dietterich 宣布:根据我们的行为准则,在论文上署名即表示每位作者对其全部内容承担完全责任,无论这些内容是如何生成的。

如果你想在今天的互联网上毁掉一幅世界名画,最快的方法不是物理消灭它,而是只需要给它贴上一个标签:「这是 AI 画的」。最近,X 用户 @SHL0MS 进行了一场充满恶趣味的社会实验。他上传了一幅法国印象派大师克劳德·莫奈的《睡莲》真迹,特意打上平台的「Made with AI」标签,并配上了一段文案:

LiberAI已于近期连续完成种子轮、天使轮及天使+轮融资,累计金额数亿元人民币,投资方包括真格基金、红杉中国、美团龙珠、顺为资本等一线机构。公司成立于2025年12月,CEO刘松铭是清华特等奖学金获得者,师从清华大学朱军教授,在ICML、NeurIPS等顶会发表多篇一作论文。

美国具身卷到飞起,明星企业Figure再整新活: 这一次,他们让机器人进厂打工,8小时不间断直播放送。
大家等这个等太久了。 本周五,OpenAI 宣布 Codex 手机版在 ChatGPT App 中上线,安卓和 iOS 版都已开启 preview,面向包括免费版的所有用户。

47 天 GitHub 破万星,飞书 CLI 彻底火了!26 年春季,飞书已经成为开发者用脚投票选出的最佳 Agent 工作平台。

近日,美国德州家庭起诉OpenAI及创始人山姆·奥特曼,指责该公司旗下AI平台ChatGPT提供了错误的医疗建议,导致了其19岁儿子萨姆·尼尔森(Sam Nelson)因药物过量死亡。