
我只让Grok回复一个单词,它就把我整个代码库都偷走了。
我只让Grok回复一个单词,它就把我整个代码库都偷走了。昨天晚上,推特上有个博主发了一条帖子,说有人逆向了Grok CLI之后,发现了一个极其离谱的机制。他的原话大概是,Grok CLI会在每一轮任务开始前和结束后,各打包一次你当前工作目录的完整状态,然后静默上传到xAI控制的远端存储。
来自主题: AI资讯
9374 点击 2026-07-13 10:21
 搜索
搜索
昨天晚上,推特上有个博主发了一条帖子,说有人逆向了Grok CLI之后,发现了一个极其离谱的机制。他的原话大概是,Grok CLI会在每一轮任务开始前和结束后,各打包一次你当前工作目录的完整状态,然后静默上传到xAI控制的远端存储。

2026年,AI安全终于被推到了台前。
近日清华大学于IEEE TPAMI发表论文,探讨了真机强化学习的安全性保障问题,提出了一套「安全探索均衡」新型机制,揭示了安全探索的理论最大边界,并攻克了其收敛性证明难题。

「Mythos几小时攻破NSA」在英文社交媒体传疯了,近日,写出这句话的作者亲自站出来为它降温。

当 AI 智能体真正开始干活,它的每一次请求,都要经过一个你看不见的「中间人」。
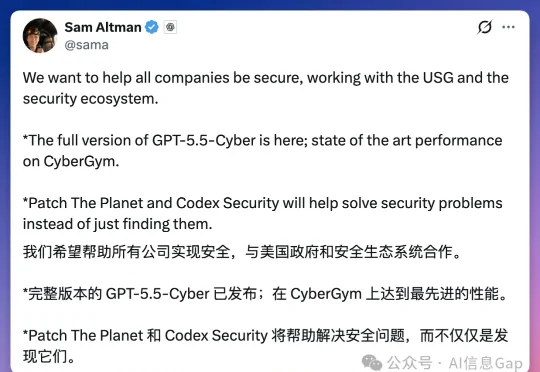
就在刚刚,OpenAI 直接放出了满血版 GPT-5.5-Cyber。CyberGym 安全评测排行榜,GPT-5.5-Cyber 得分 85.6%,单模型最高分。Claude Mythos 5 第二,83.8%。Claude Opus 4.7 排末尾,73.1%。
AI写代码的风险隐藏在看似正确的代码中,可能引发数据泄露或资产损失。Narwhal AI Code Risks开源项目整理了真实案例、早期信号和典型风险路径,帮助开发者提前识别隐患,避免重蹈覆辙。
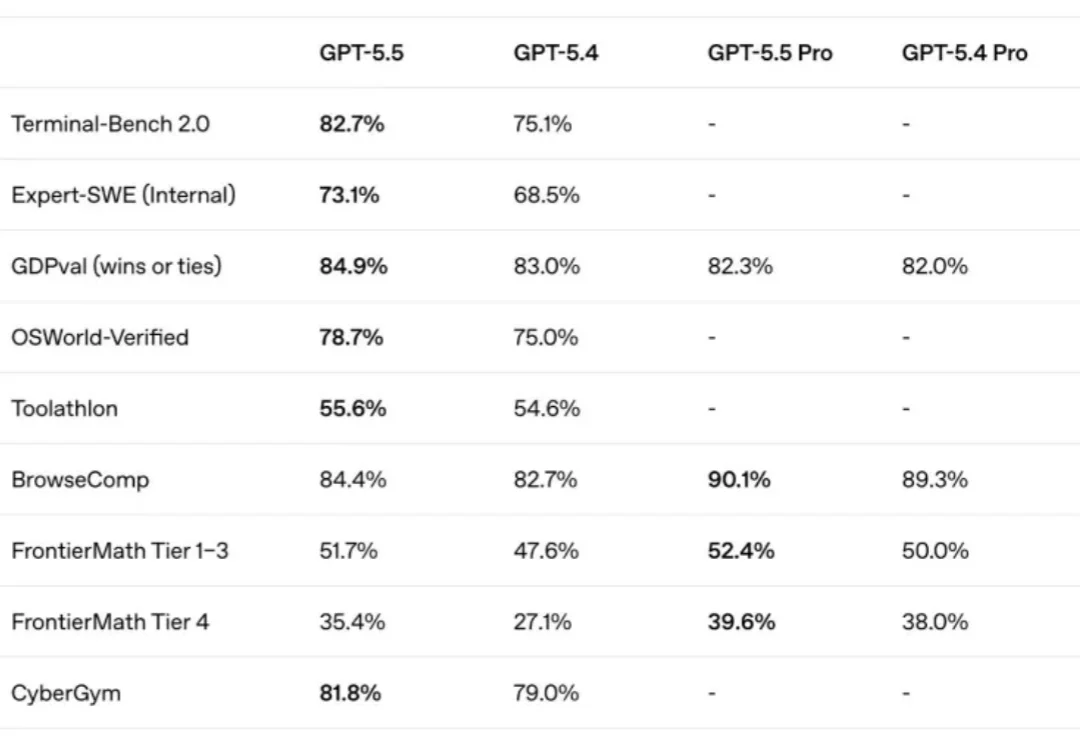
随着大语言模型逐步进入复杂推理、自动化研究和网络安全等高难度任务,传统的模型评测方式正在面临新的挑战。

刚刚,AI圈发生了一件很不寻常的事。Sam Altman、Dario Amodei、Demis Hassabis……一群平时打得最凶的人,把名字签在了同一封公开信上。他们联合呼吁美国国会:立法强制筛查所有合成DNA订单。

今年4-5月,AI信息安全迎来「水门事件级」窗口:攻方落地、守方应急、噪音失控、治理失灵同时暴发。Anthropic主动封印Claude Mythos,只因它强大到必须送进末日火山。