
Z Potentials|专访方寸跃迁李筱健、董胤蓬:安全没有终点,每完成一次九十九分的答卷,下一轮新的风险已经出现
Z Potentials|专访方寸跃迁李筱健、董胤蓬:安全没有终点,每完成一次九十九分的答卷,下一轮新的风险已经出现一次错误回答,可能只会让用户关掉页面;一次错误执行,却可能改写企业数据库、触发一笔交易,甚至让整条业务流程偏离轨道。
来自主题: AI资讯
8773 点击 2026-07-24 11:07
 搜索
搜索
一次错误回答,可能只会让用户关掉页面;一次错误执行,却可能改写企业数据库、触发一笔交易,甚至让整条业务流程偏离轨道。

据The Information独家报道,Taylor目前所领导的AI客户支持初创公司Sierra正在收购Thumaty创办的三人初创公司Takeoff,后者开发的Agent能够长时间持续处理各类任务。Sierra高管希望,随着公司试图从AI驱动的客户支持Agent业务拓展到销售面向其他任务的Agent,Thumaty的专业经验将大有助益。
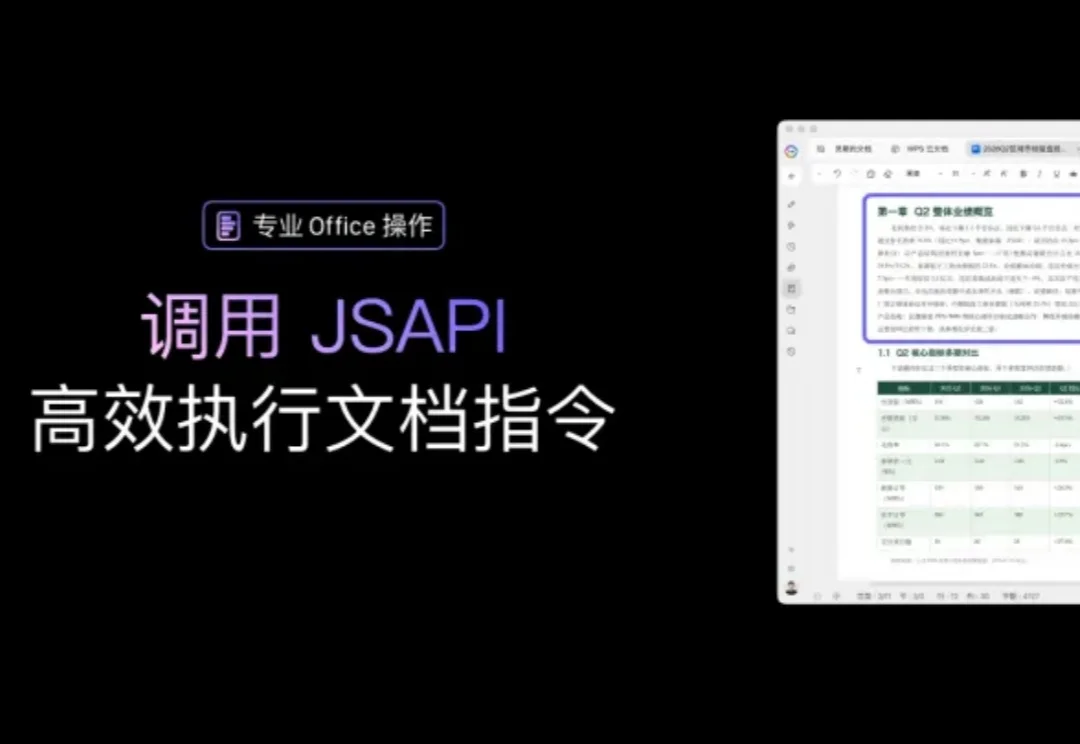
在过去一年里,我的发票、合同、申请表,全是 claude code 帮我弄的,着实省了不少功夫,但也积累下来了不少抱怨:格式我能自定的还好,直接生成网页版直接打印。最怕对方发来一个固定格式的 Word,只能在指定位置改,直接哭瞎

千问说它可以帮我拼九宫格了,还是不同主题的那种。
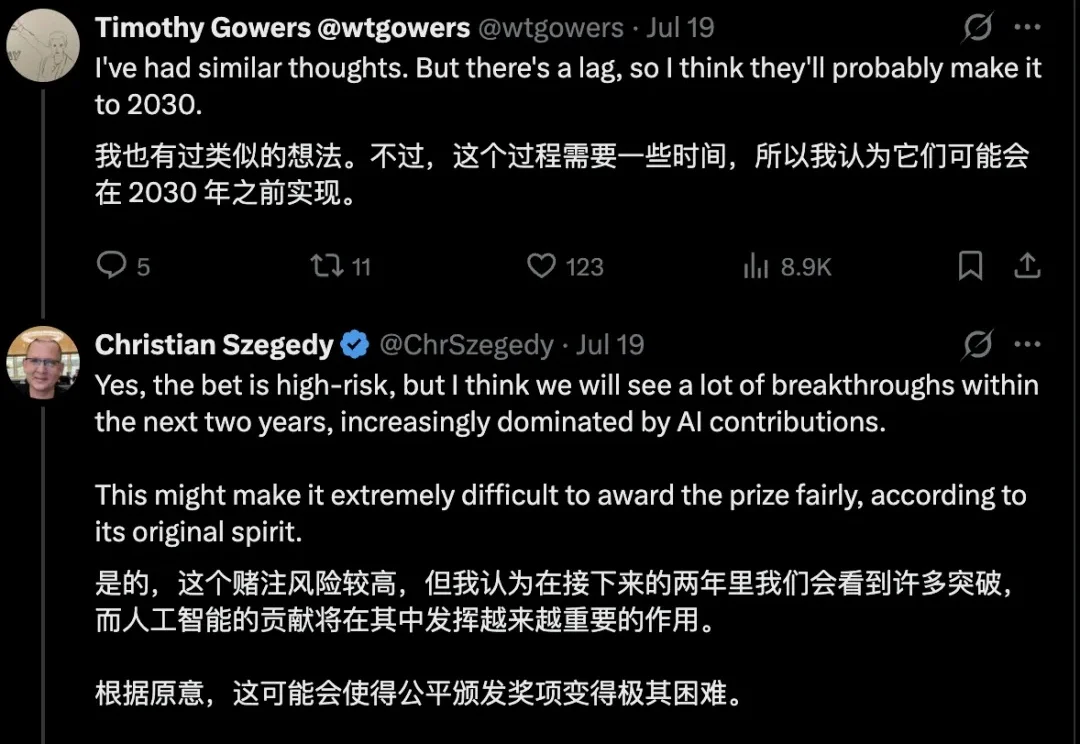
7月23日,第30届国际数学家大会(ICM)将在费城开幕,菲尔兹奖将在开幕式上颁出。

数据市场的故事,正在进入新一轮周期。来自企业真实工作流的 Real-world Data,成为越来越多 AI Labs 争夺的新资源。比如 GitHub 就是典型的 Real-world Data,它几乎完整保留了一个问题从出现到解决的全过程。相比之下,今天绝大多数 Human Data 公司提供的,仍是人为构造的数据。

「我们已进入奇点。」
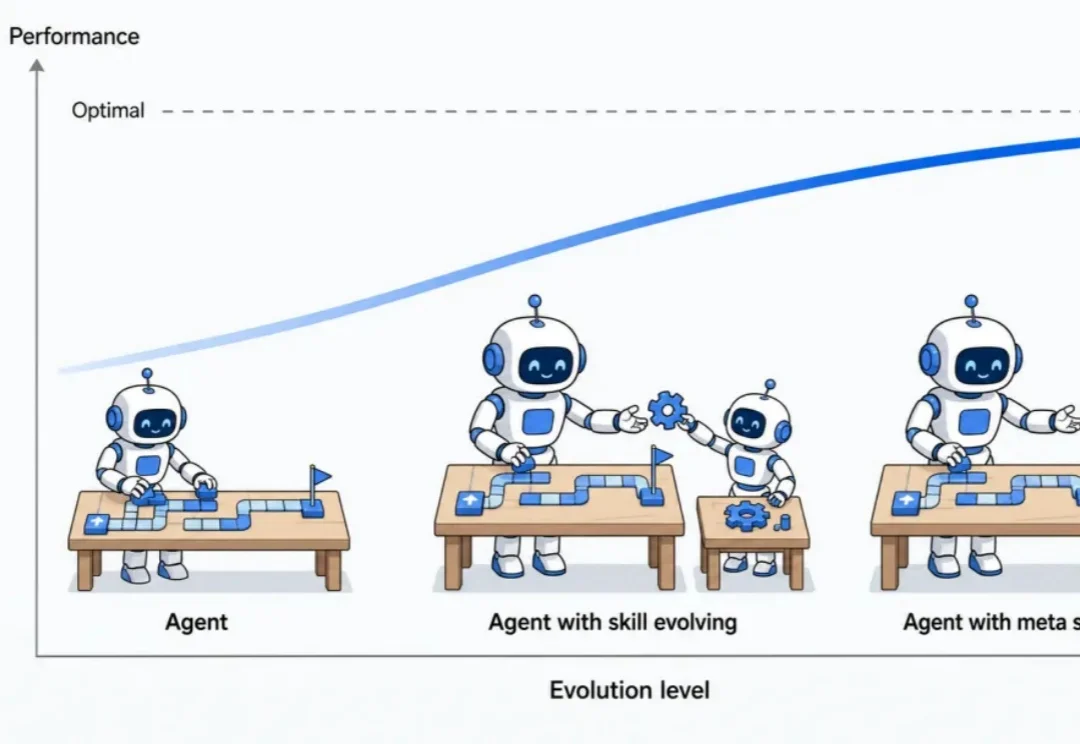
当大模型 Agent 被部署到工具调用、长程任务和开放环境中,一个关键问题会随之出现:能否在不更新模型参数的情况下,将执行经验沉淀下来,并在下一次做得更好?
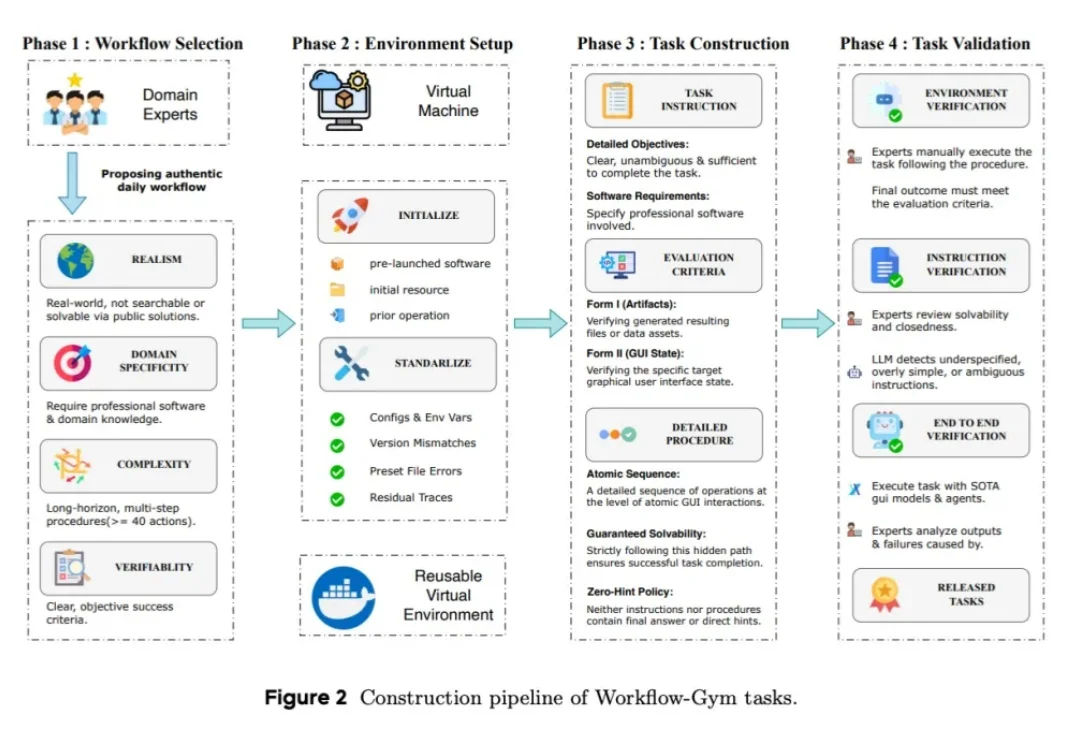
你可能已经在各种 benchmark 榜单上看过 GUI Agent 的 "大胜" 了。

现在还在场的模型公司里比较奇葩的是阶跃,首先它模型能力就那样,属于大伙有共识的排在第二梯队。