Agent的行车记录仪!开源工具Mindwalk把Claude Code和Codex工作路径搬上3D地图,工作全程留痕
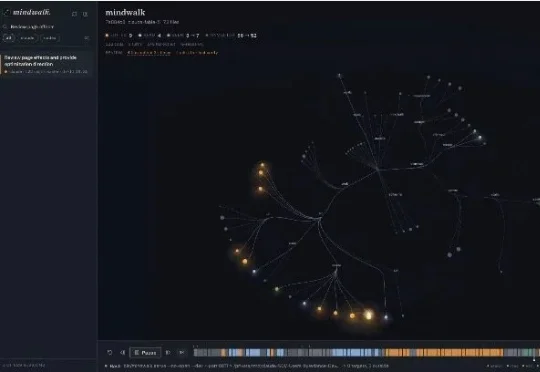
Agent的行车记录仪!开源工具Mindwalk把Claude Code和Codex工作路径搬上3D地图,工作全程留痕把一个Bug交给Claude Code或Codex,十几分钟后它回了一句“Done”和一大片Diff。过程中它读错了什么、为什么反复改同一个文件、最后有没有重新跑测试......开发者想知道就只能去几百行日志里碰运气。7月11日,一个名叫Mindwalk的开源项目发布了v0.1.0。
来自主题: AI资讯
9036 点击 2026-07-14 10:36