

AI遭遇灵魂拷问!这道题所有模型集体翻车,网友:我也不会啊
AI遭遇灵魂拷问!这道题所有模型集体翻车,网友:我也不会啊拷打AI的难度还在升级?这不,图像推理又出现了新难题。
来自主题: AI资讯
7148 点击 2025-05-20 10:49
拷打AI的难度还在升级?这不,图像推理又出现了新难题。

各种AI模型在刚问世时,总有一个屡试不爽的“秀肌肉”手段,那就是让自家AI独立游玩某款游戏,用以检验模型的智能程度。

公考行测中的逻辑推理题,是不少考生的噩梦,这次,CMU团队就此为基础,打造了一套逻辑谜题挑战。实测后发现,o1、Gemini-2.5 Pro、Claude-3.7-Sonnet这些顶尖大模型全部惨败!最强的AI正确率也只有57.5%,而人类TOP选手却能接近满分。

悬疑小说的最后一页,隐藏着罪犯的真相。《逆转裁判》的法庭上,真凶在谎言中露出破绽。UCSD研究团队以这款经典游戏为舞台,o1、Gemini 2.5 Pro等模型化身「侦探」,测试AI的推理极限。

谷歌DeepMind研发的DreamerV3实现重大突破:无需任何人类数据,通过强化学习与「世界模型」,自主完成《我的世界》中极具挑战的钻石收集任务。该成果被视为通往AGI的一大步,并已登上Nature。

在三方图灵测试中,UCSD的研究人员评估了当前的AI模型,证明LLM已通过图灵测试。在测试中,同时与人及AI系统进行5分钟对话,然后判断哪位是「真人」。结果,AI竟然比「真人」还像人:
据 The Information 报道,总部位于旧金山的 AI 软件测试公司 Ranger 在 12 月获得了由General Catalyst领投的 650 万美元种子轮融资,以及在 2023 年 11 月获得的由XYZ领投的 240 万美元前种子轮融资。

当前的大型语言模型似乎能够通过一些公开的图灵测试。我们该如何衡量它们是否像人一样聪明呢?
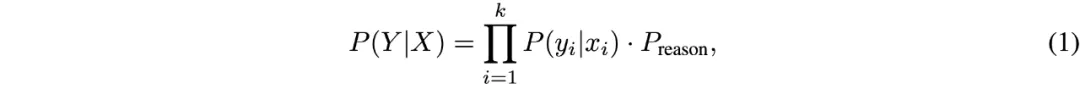
随着人工智能技术的快速发展,能够处理多种模态信息的多模态大模型(LMMs)逐渐成为研究的热点。通过整合不同模态的信息,LMMs 展现出一定的推理和理解能力,在诸如视觉问答、图像生成、跨模态检索等任务中表现出色。

在基准测试上频频屠榜的大模型们,竟然被一道简单的逻辑推理题打得全军覆没?最近,研究机构LAION的几位作者共同发表了一篇文章,以「爱丽丝梦游仙境」为启发涉及了一系列简单的推理问题,揭示了LLM基准测试的盲区。