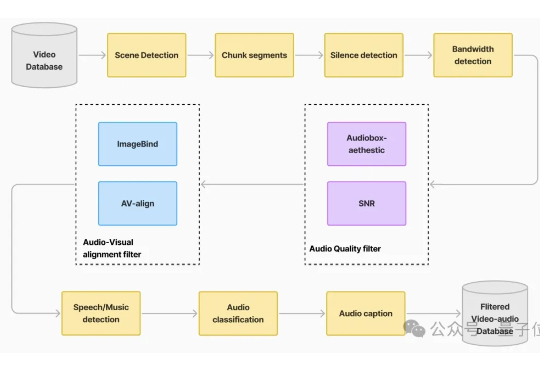
SALMONN 系列音视频理解大模型霸榜回归!推理增强、高帧率、无文本泄漏全线突破
SALMONN 系列音视频理解大模型霸榜回归!推理增强、高帧率、无文本泄漏全线突破全新一代 video-SALMONN 2/2+、首个开源推理增强型音视频理解大模型 video-SALMONN-o1(ICML 2025)、首个高帧率视频理解大模型 F-16(ICML 2025),以及无文本泄漏基准测试 AVUT(EMNLP 2025) 正式发布。新阵容在视频理解能力与评测体系全线突破,全面巩固 SALMONN 家族在开源音视频理解大模型赛道的领先地位。
来自主题: AI资讯
9440 点击 2025-09-30 10:44