
告别AI「鬼画符」!一行指令「复活」王羲之、苏轼,带连笔、懂排版,项目已开源丨ICLR'26
告别AI「鬼画符」!一行指令「复活」王羲之、苏轼,带连笔、懂排版,项目已开源丨ICLR'26苦于AI单字拼凑没行气,或是排版秒变“鬼画符”?
来自主题: AI技术研报
6751 点击 2026-03-23 13:44
 搜索
搜索
苦于AI单字拼凑没行气,或是排版秒变“鬼画符”?
AI 驱动的自动化科研正从概念走向真实系统。近期受到广泛关注的 FARS,以及 Karpathy 开源的 autoresearch,都在不同程度上展示了 AI Scientist 自动进行 AI 领域研究的可行性。

多模态大模型,到底有多“嘴硬”? 浙江大学联合阿里巴巴、香港城市大
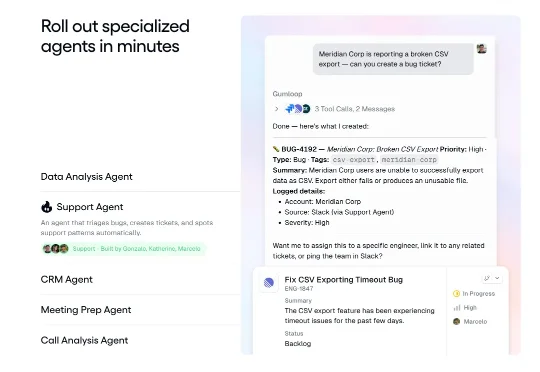
Gumloop 刚刚宣布完成 5000 万美元的 B 轮融资,由 Benchmark 领投,Nexus VP、First Round Capital、Y Combinator、Box Group、The Cannon Project 和 Shopify Ventures 参与跟投。

ACE 的起点,并不是把音乐生成做成一个更轻的娱乐玩具,而是从专业创作工作流里切进去。ACE Studio 2.0 于 2025 年 12 月正式发布,产品形态也从 AI vocal workstation 进一步扩展为 all in one AI music studio,开始把 AI 歌声、乐器、生成、编辑与 DAW 协同整合成一个AI 音乐创作系统。
AI 编码的竞争,已经进入了新的高度。

没有农民,没有农机手,甚至没有一个人站在田间地头。
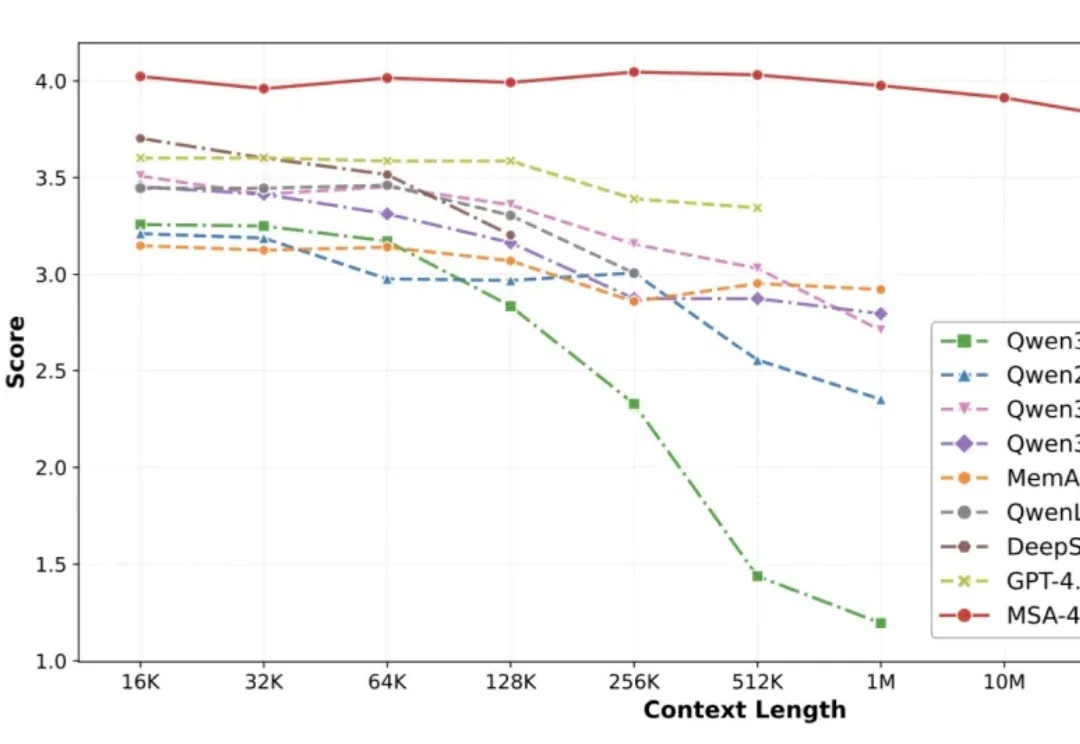
人的智能能力主要由推理能力和长期记忆能力构成。近年来,大模型的推理能力一直处于快速发展过程,但大模型的长期记忆能力一直受限于上下文长度,无法取得突破。在历史上,曾经有多种路线进行尝试,但都无法突破扩展性(Scalability)、精度(Precision)和效率(Efficiency)的不可能三角。
来自天工AI的SkyReels-V4,没打招呼,直接登顶Artificial Analysis文转视频(含音频)全球榜,超越Veo 3.1、Sora 2。一个月前,其Preview版本才刚拿下该榜全球第2。

占领OpenRouter调用量榜单第一的神秘模型Hunter Alpha,终于揭开神秘面纱—— 既不是GPT,也不是DeepSeek,而是来自小米的万亿旗舰模型MiMo-V2-Pro。