5 亿 ARR的Cursor,已经没人讨论它了?
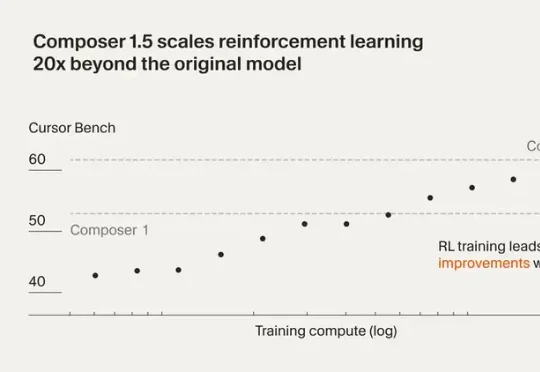
5 亿 ARR的Cursor,已经没人讨论它了?最近Cursor 发布了 Composer 1.5。这一版把强化学习规模扩大了 20 倍,后训练计算量甚至超过了基座模型的预训练投入。还加了 thinking tokens 和自我摘要机制,让模型能在复杂编程任务里做更深度的推理。
来自主题: AI资讯
10224 点击 2026-02-22 11:39
 搜索
搜索
最近Cursor 发布了 Composer 1.5。这一版把强化学习规模扩大了 20 倍,后训练计算量甚至超过了基座模型的预训练投入。还加了 thinking tokens 和自我摘要机制,让模型能在复杂编程任务里做更深度的推理。

最新消息显示,奥特曼已将公司核心资源从探索性的长线研究(Blue-sky research)全面倾斜至旗舰产品ChatGPT的工程化改进。这一战略调整,导致包括前研究副总裁Jerry Tworek在内的多位核心元老因理念分歧而心寒出走。

来自阿里高德的一篇最新 ICLR 2026 中稿论文《Everything in Its Place: Benchmarking Spatial Intelligence of Text-to-Image Models》提出了面向文生图空间智能的系统性评估基准 SpatialGenEval,旨在通过长文本、高信息密度的 T2I prompt 设计,以及围绕空间感知

在印度人工智能影响力峰会上,出现 AI 圈最尴尬的一次合影。印度总理莫迪举起 Sam Altman 和 Sundar Pichai 的手,其他大佬也纷纷效仿牵手,唯独 Altman 和 Anthropic CEO Dario Amodei 并肩站立。

当地时间 2 月 19 日,Google 曝光 Gemini 3.1 Pro 最新模型。在 ARC-AGI-2 这个公认的推理基准测试中,Gemini 3.1 Pro 拿到了 77.1% 的分数。什么概念?它的前辈 Gemini 3 Pro 只有 31.1%,就连专门用来「深度思考」的 Gemini 3 Deep Think 也只有 45.1%。
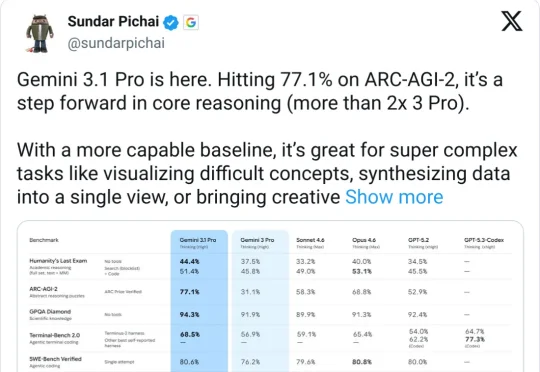
今天凌晨,Google 发布 Gemini 3.1 Pro。核心提升在推理能力,ARC-AGI-2(抽象推理基准)从 3 Pro 的 31.1% 跳到 77.1%,翻了一倍多,GPQA Diamond(科学知识推理)从 91.9% 提到 94.3%

从灵巧手开始「制造时间」:揭秘 Sharpa 的通用人工智能之路 作者|Li Yuan 编辑|郑玄 今年的春晚,已经变成机器人大战了。 在热闹之下,笔者关注到了一个很有趣的细节,相比于去年的机器人,今

据彭博社记者 Mark Gurman 爆料,苹果正在加速推进三款全新的 AI 可穿戴设备。这三款产品都将围绕 Siri 数字助手构建,通过摄像头获取视觉上下文来执行各种操作。
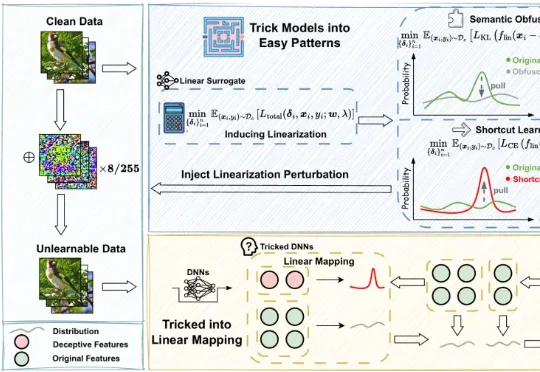
不可学习样本(Unlearnable Examples)是一类用于数据保护的技术,其核心思想是在原始数据中注入人类难以察觉的微小扰动,使得未经授权的第三方在使用这些数据训练模型时,模型的泛化性能显著下降,甚至接近随机猜测,从而达到阻止数据被滥用的目的。

通用具身智能机器人公司「无界动力」宣布完成超2亿元天使+轮融资,老股东红杉中国、线性资本、高瓴创投、华业天成、中金资本旗下基金、BV百度风投持续追投,新增深创投、创新工场、普华资本、钧山资本、雅瑞资本等加入。