华人医生离开哈佛创业18个月,融资550万美元做最懂你的AI情感伙伴Robyn
华人医生离开哈佛创业18个月,融资550万美元做最懂你的AI情感伙伴RobynJenny 创立的 Robyn 刚刚完成了 550 万美元的种子轮融资,由 M13 领投,Google Maps 联合创始人 Lars Rasmussen、Canva 早期投资人 Bill Tai、前雅虎 CFO Ken Goldman 等人参与投资。
来自主题: AI资讯
8913 点击 2025-12-12 09:50
 搜索
搜索
Jenny 创立的 Robyn 刚刚完成了 550 万美元的种子轮融资,由 M13 领投,Google Maps 联合创始人 Lars Rasmussen、Canva 早期投资人 Bill Tai、前雅虎 CFO Ken Goldman 等人参与投资。

今日凌晨,比OpenAI早一个小时,谷歌甩出了3个Agent大招:Deep Research Agent功能更新,并首次向开发者开放;开源新网络研究Agent基准DeepSearchQA,旨在测试Agent在网络研究任务中的全面性;推出新交互API(Interactions API)。

老板丢下一句“要高端大气”,然后转身就走。 面对空白的 PPT,你是不是也经常想把电脑砸了? 以前为了填这个坑,我得花几小时刷各种网站找素材。但最近,我摸到了 Google 的新神器 Mixboard。
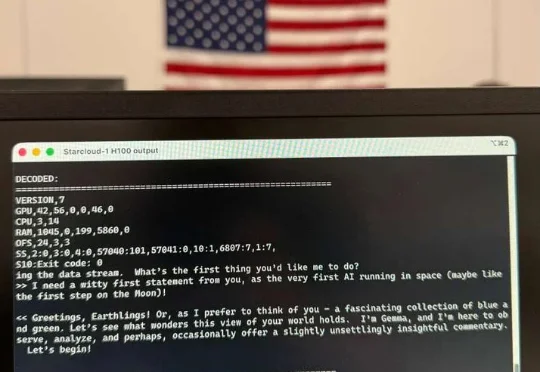
见证历史!今天,首个由H100太空GPU训出LLM诞生了,它基于Karpathy nano-GPT训练。不仅如此,谷歌Gemma也在太空成功运行,向世界发出首句问候:地球人,你好。

2025 年 12 月的第二周,一则颇为吸睛的消息从东京传出:一家名为 Integral AI 的初创公司宣布,他们已经成功测试出“世界上第一个具备 AGI 能力的模型”。AGI,即 Artificial General Intelligence(通用人工智能),向来被视为 AI 领域的终极圣杯。

两个月前,女演员 Tilly Norwood 遭遇了一场「网暴」。

提起马卡龙,你会想到什么?是橱窗里的精致甜点,一种“少女心”的味觉象征?还是代表了温柔优雅的时尚配色?当一个AI产品也被命名为“马卡龙”,这份联想便悄然发生了偏移:从舌尖的甜,转向科技的未知,却又奇妙地保留了那一份色彩与气质。

2025 年 12 月,由 阿里巴巴 联合 中国科学技术大学、浙江大学等机构共同研发的实时虚拟人项目 LiveAvatar 正式对外开源。该项目聚焦长期困扰虚拟人行业的两大技术瓶颈——“实时响应能力”与“长时稳定生成能力”,首次在同一系统中实现了二者的工程级统一。

Googel和IBM十年打不穿的量子天花板,被一块1万qubit的芯片掀开了?巨头还在百级徘徊,量子突然跨进了能落地的时代。更讽刺的是,真正接住这场变革的,是早已埋伏在算力入口的英伟达。

Anthropic联合创始人兼首席科学官Jared Kaplan,认为在2027-2030年期间,我们将不得不做出是否允许 AI 自我进化的抉择,而允许的话很可能导致AI失控,毁灭全人类。Anthropic在迅速提升AI模型性能不断逼近AGI奇点的同时,也在同时让「9人特种部队」用1.4万字的「AI宪法」防范AI失控。