
从Foundation Model到Physical AI,三星「杀入」大模型核心战场
从Foundation Model到Physical AI,三星「杀入」大模型核心战场过去几年,大模型竞争主要发生在 AI 公司之间。但随着 AI 开始从数字世界进入真实设备与物理世界,竞争逻辑正在发生变化。
来自主题: AI技术研报
5842 点击 2026-05-27 16:09
 搜索
搜索
过去几年,大模型竞争主要发生在 AI 公司之间。但随着 AI 开始从数字世界进入真实设备与物理世界,竞争逻辑正在发生变化。
大语言模型在地图、城市、交通等空间领域的应用越来越广泛。对于这些场景来说,问题往往不只是 “查一个地点” 或 “调用一次路线 API” 就能解决的,而是需要把用户的自然语言问题组织成一段可执行、可验证的地理分析流程。

今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。
下一代创作软件比的不是模型能力,而是谁能把完整的创作流程跑通。 能让 Agent 从接到目标开始,一路协作推进到交付成品的系统,才是真正的竞争力。 OmniWork 是我们最近看到的明确在朝这个方向走的产品。它给自己的定位是「The Agent OS for Creative Work」,面向创作工作的 Agent 操作系统。
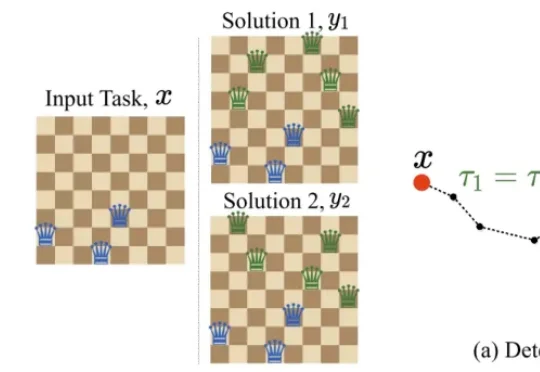
现在,图灵奖得主 Yoshua Bengio 给出了一份全新的并行方案。他们提出了 GRAM(Generative Recursive reAsoning Models,生成式递归推理模型),把确定性的递归潜在推理变成了概率性的多轨迹计算。模型在潜在空间中进行随机递归推理,每一步都可以采样不同的方向,最终形成对解空间的多路径探索。
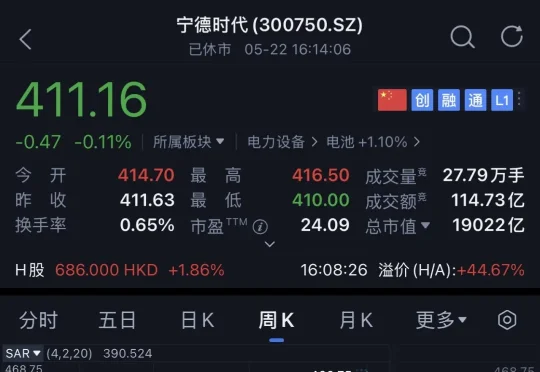
据The Information昨晚报道,全球动力电池市场龙头宁德时代拟入局DeepSeek首轮融资。这是宁德时代在AI领域被曝出的最新布局。就在刚刚过去的一个半月内,宁德时代官宣斥资105亿元加码AI算电协同赛道,电力、算力、储能、AI一体化全产业链布局全面落地。

据The Information今日报道,两位知情人士透露,OpenAI今年第一季度的营收约为57亿美元(约合人民币387.7亿元),比其主要竞争对手Anthropic同期收入高出近10亿美元(约合人民币68亿元)。

AI办公彻底变天了!阿里QoderWork重磅发布全球首个AI Native自定义工作台,推出设计、PPT、写作三大领域模式。AI办公正式从「对话驱动」走向「领域驱动」。
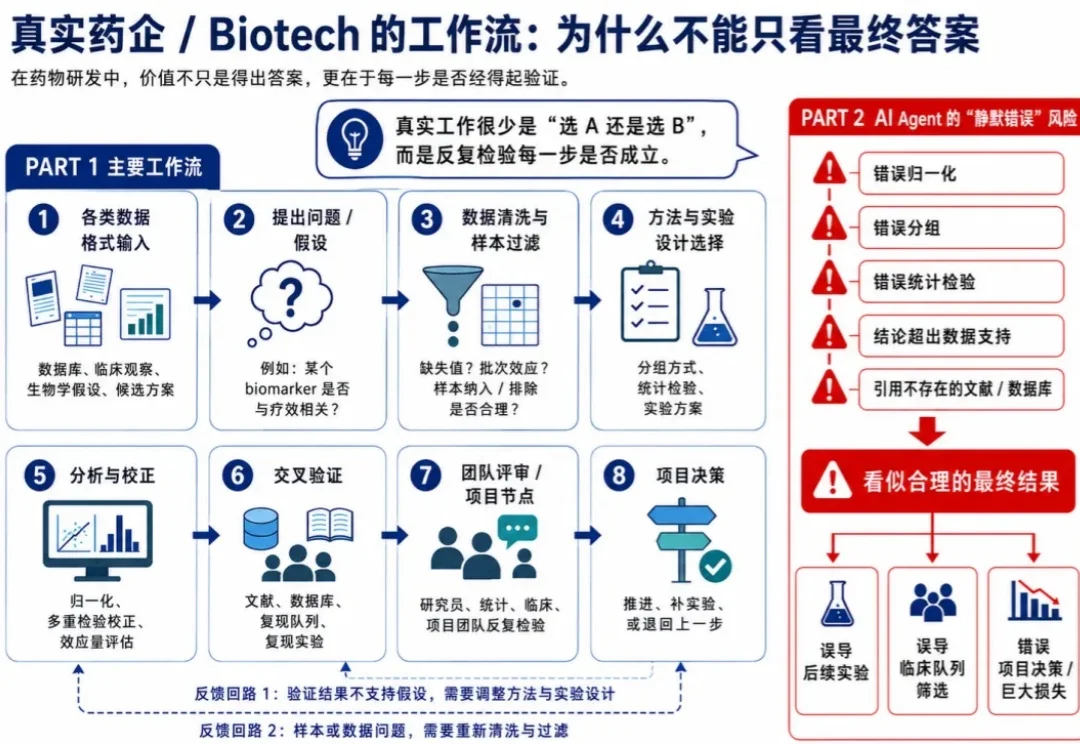
xbench,就是红杉自己弄的那个中立评测lab,刚刚又整了个新活:让 AI 做药企的数据分析,跟人类实习生比个高低,然后遥遥领先的赢了
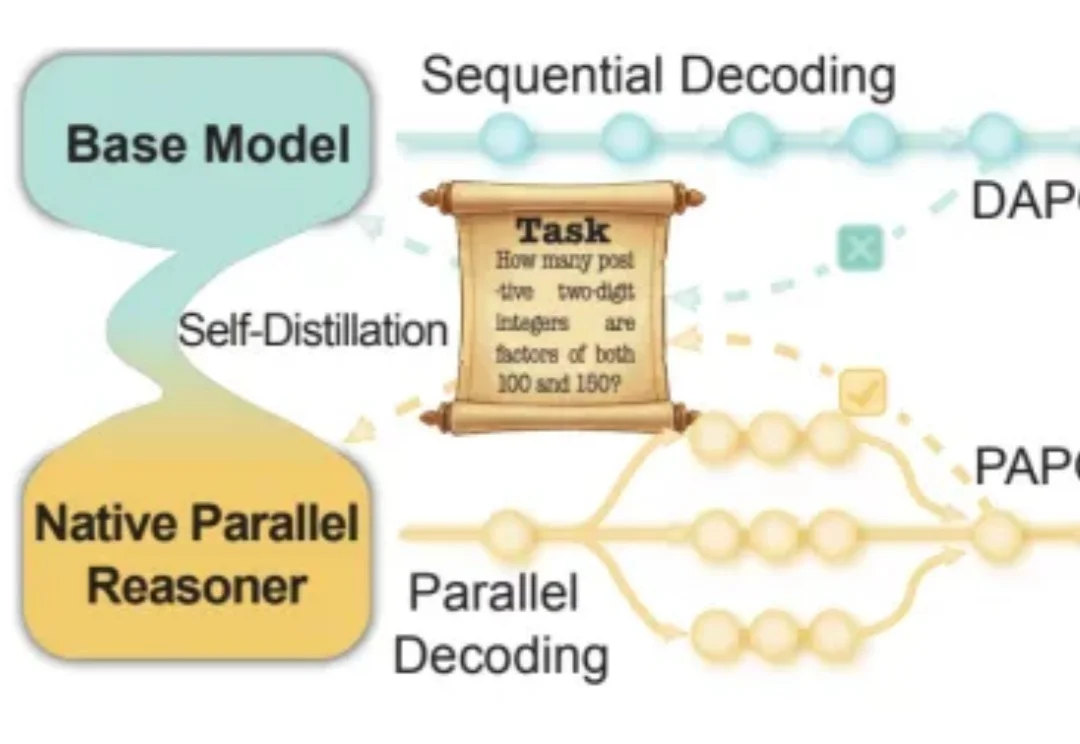
近年来,大语言模型在「写得长、写得顺」这件事上进步飞快。但当任务升级到真正复杂的推理场景 —— 需要兵分多路探索、需要自我反思与相互印证、需要在多条线索之间做汇总与取舍时,传统的链式思维(Chain-of-Thought)往往就开始「吃力」:容易被早期判断带偏、发散不足、自我纠错弱,而且顺序生成的效率天然受限。