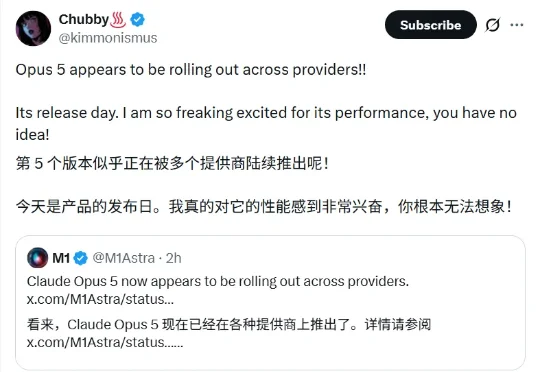
Claude Opus 5 被曝今晚发布,Fable 5 的水平,腰斩的价格
Claude Opus 5 被曝今晚发布,Fable 5 的水平,腰斩的价格大家还没等来DeepSeek V4的发布消息,Anthropic家Claude Opus 5今夜即将推出的消息,已经先把全网开发者的热情点燃了。一句"性能强得超乎想象,各大平台正陆续上线"的传闻,将全网的目光再次聚焦在Anthropic上。
来自主题: AI资讯
9804 点击 2026-07-24 00:24
 搜索
搜索
大家还没等来DeepSeek V4的发布消息,Anthropic家Claude Opus 5今夜即将推出的消息,已经先把全网开发者的热情点燃了。一句"性能强得超乎想象,各大平台正陆续上线"的传闻,将全网的目光再次聚焦在Anthropic上。

开源一周多,DojoAgents 已经在 GitHub 获得超过 1000 个 Star。DojoAgents 项目受到关注,是因为其并不只是一个能回答投资问题的 Agent,而是一种新的金融决策辅助方式:让 AI 不再停留在生成答案,而是形成对金融世界持续更新的理解,并在数据、工具、权限和风险边界内,长期且持续主动地推进研究与决策辅助任务。

Acrab的Agent Box在这个背景下出现。它没有停在“把模型装进桌面设备”这一步,而是把模型、个人数据、Runtime、工具链和Agent编排放进同一套系统,让Agent能够保存上下文、调用工具,并在不同应用之间连续完成任务。

独家获悉,近期,腾讯混元多模态理解负责人胡瀚提出了离职。此前,他曾担任微软亚洲研究院视觉计算组首席研究员。2025年初加入腾讯后,负责视觉大模型的研究。在后续的调整中,他加入大语言模型部旗下的“Frontier”前沿技术研究组,负责多模态理解的相关研究,汇报给姚顺雨。
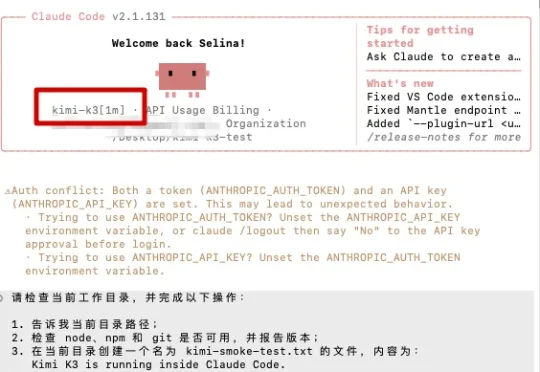
Kimi 官方停止接受新的会员订阅后,还有什么办法用上最新的 K3 成了当务之急,而且,也有一个符合直觉的答案:API。K3 可以通过开放平台直接调用,也能被接入 Claude Code 等第三方编程 Agent。只要准备一个 API Key,再做少量配置,用户似乎就能绕过拥挤的官方入口,把模型能力重新接到自己的电脑上。

LPU创业公司元川微已完成Pre-A轮数亿元融资。本轮融资由IDG资本领投,孚腾资本、九坤创投、尚颀资本、顺禧基金、徐汇科创投联合投资。据了解,这也是元川微2026年以来完成的第四轮融资。

硬氪获悉,工业AI设计研发解决方案供应商「设序科技」于近日正式完成B轮超亿元融资,累计获超3亿元融资,投资方包括深产投、合鼎共及老股东涌铧投资等。融资将用于市场开拓(含出海)及核心模型技术研发。
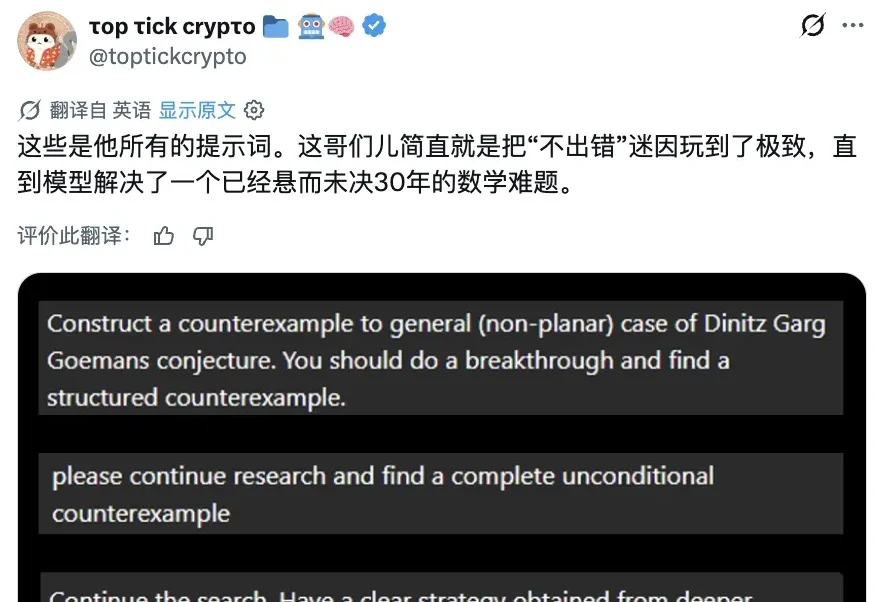
又来???GPT-5.6最近这是捅了数学反例窝了……
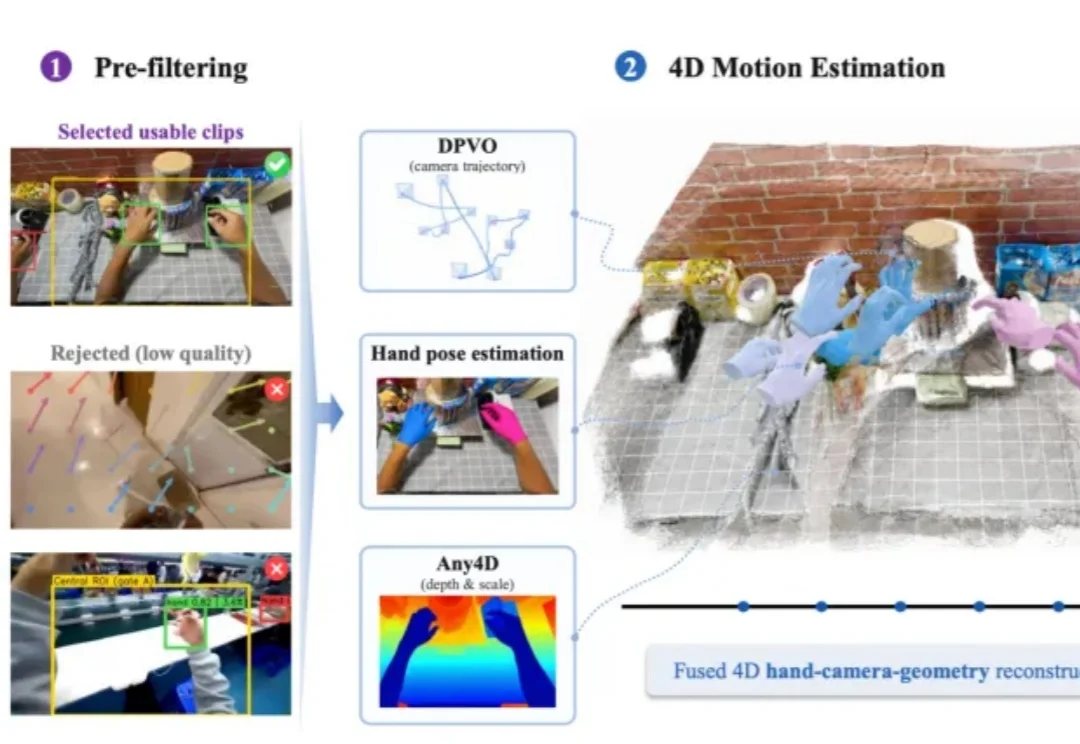
记得何同学做过一个超复杂的流水线项目吗?
一段原本为英伟达 CUDA 设计的计算程序,几乎无需修改内核代码,就直接跑在了一台搭载 M3 Pro 的苹果设备上。