
AI 设计终于不靠抽卡了!if Studio 把设计专家做成流水线
AI 设计终于不靠抽卡了!if Studio 把设计专家做成流水线2026 年 7 月 20 至 24 日,硬核少年技术节 5.0 在杭州、北京共同举办。
来自主题: AI资讯
6473 点击 2026-07-23 11:43
 搜索
搜索
2026 年 7 月 20 至 24 日,硬核少年技术节 5.0 在杭州、北京共同举办。

上海的七月,热浪滚滚。
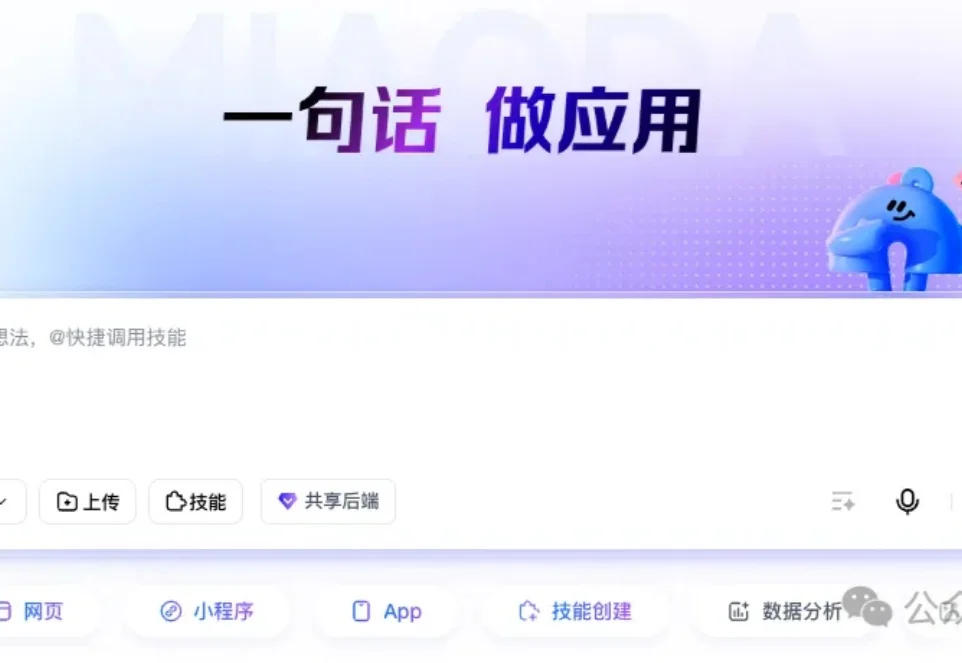
WAIC 2026上,百度秒哒带来了3.5版本。据官方数据,秒哒累计服务超过3500万用户,创造了350万个具有商业价值的应用,每天有近20万人在使用这些应用解决真实问题。

过去一年,具身智能赛道正经历着前所未有的「冰火两重天」。

2026年世界人工智能大会,上海世博展馆人声鼎沸。

智能的下一阶段,已从“模型”转向“系统可靠性和进化性”的比拼。

热热热热热!今年 WAIC 现场,大家对 AI 的热情,像上海的气温一样持续攀升。
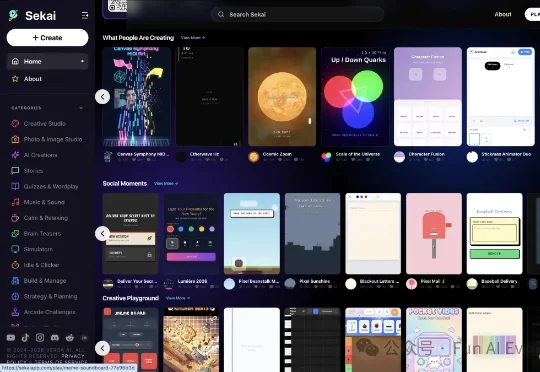
简单来说,你只需要说一句话,Sekai 就能直接帮你做出一个可以玩的“小程序”。比如: “根据今天的天气和我的心情,帮我选一套衣服”。几秒钟后,一个穿衣推荐小程序就做好了。你不用写代码,甚至不用想清楚这个产品到底应该长什么样。

今天,世界模型几乎成为 AI 领域最受关注的话题之一,但对于“什么才是真正的世界模型”却依然存在巨大分歧。有人认为它只是视频生成的延伸,也有人认为只有能够理解物理规律、支持机器人行动的系统才是真正的世界模型。
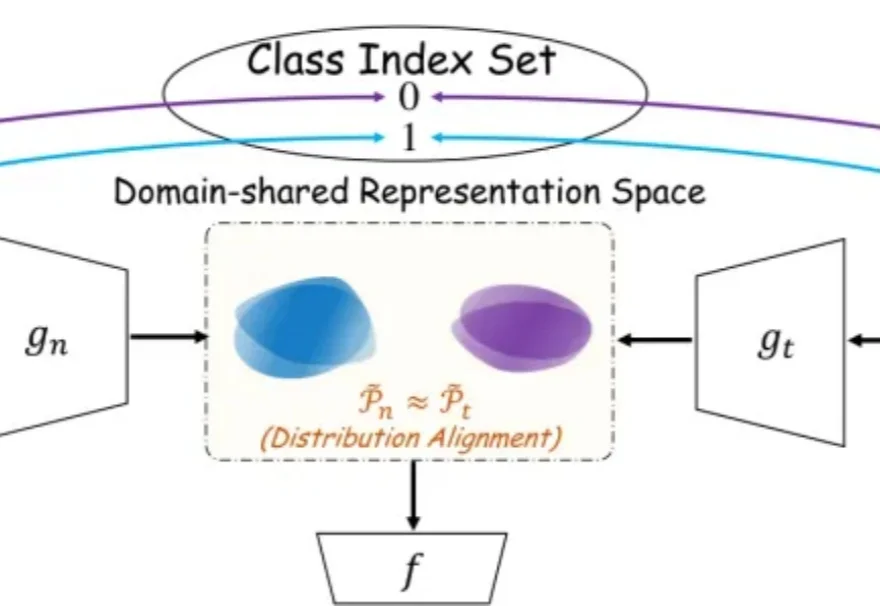
迁移学习里的“源数据”,未必非得是图像、文本或音频。