
为Agent设计的AI搜索什么样?为什么20万开发者选AnySearch
为Agent设计的AI搜索什么样?为什么20万开发者选AnySearch很多开发者对 AnySearch 应该都不陌生,Github Star 6000+,上线首月狂揽全球10万开发者用户。在Product Hunt上,它也是周榜第一。前几天去了AnySearch组织的活动,启发比想象中更大。
来自主题: AI资讯
8502 点击 2026-07-28 10:20
 搜索
搜索
很多开发者对 AnySearch 应该都不陌生,Github Star 6000+,上线首月狂揽全球10万开发者用户。在Product Hunt上,它也是周榜第一。前几天去了AnySearch组织的活动,启发比想象中更大。

刚刚,OpenAI前首席科学家Ilya Sutskever的创企Safe Superintelligence(SSI)宣布和英伟达建立长期战略合作伙伴关系。英伟达将大量投资SSI,使其算力规模未来12个月内增长10倍。

就在刚刚,全球首个3万亿参数级开源模型Kimi K3正式开源!https://github.com/MoonshotAI/Kimi-K3/tree/main。Moonshot AI宣布,发布Kimi K3的模型权重、技术报告,并开源支撑Kimi K3模型训练的关键Infra技术:MoonEP、FlashKDA和AgentEnv。
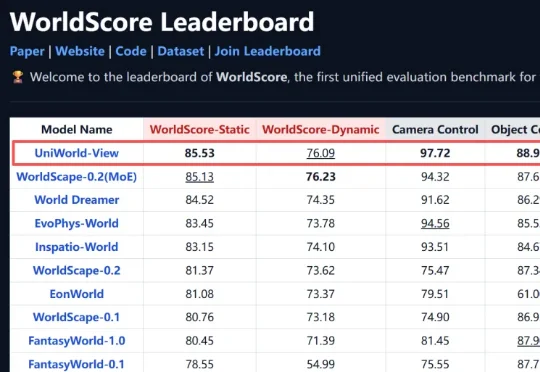
最近,兔展智能联合北京大学、鹏城实验室研发的 UniWorld-View 登顶李飞飞团队 WorldScore 世界模型榜单(训练数据来自北大系初创企业元空智能),并完成国产昇腾算力适配与代码、权重开源。

今年以来,AI 最明显的「风口」,莫过于硬件了。从大厂到初创,点子层出不穷。

这位是AI视频赛道的祖师爷、105亿美元(约合人民币677亿元)估值的硅谷AI独角兽Midjourney创始人David Holz。

众所周知,上周六在深圳,我们和TapNow一起举办了一场史无前例的恐怖片黑客松。

您猜怎么着? 除了Anthropic外,几乎所有人都签了老黄的开源倡议书,包括OpenAI。

全网刷屏!11家公司的面试,57场正式面试,46个招募电话,6年博士生涯的Alisa Liu,即将加入OpenAI。这份干货满满的黄金笔记,已经在全网疯转了。

如果要在科技圈评选一个最吃力不讨好的执念,那一定是纯粹的仿生学。