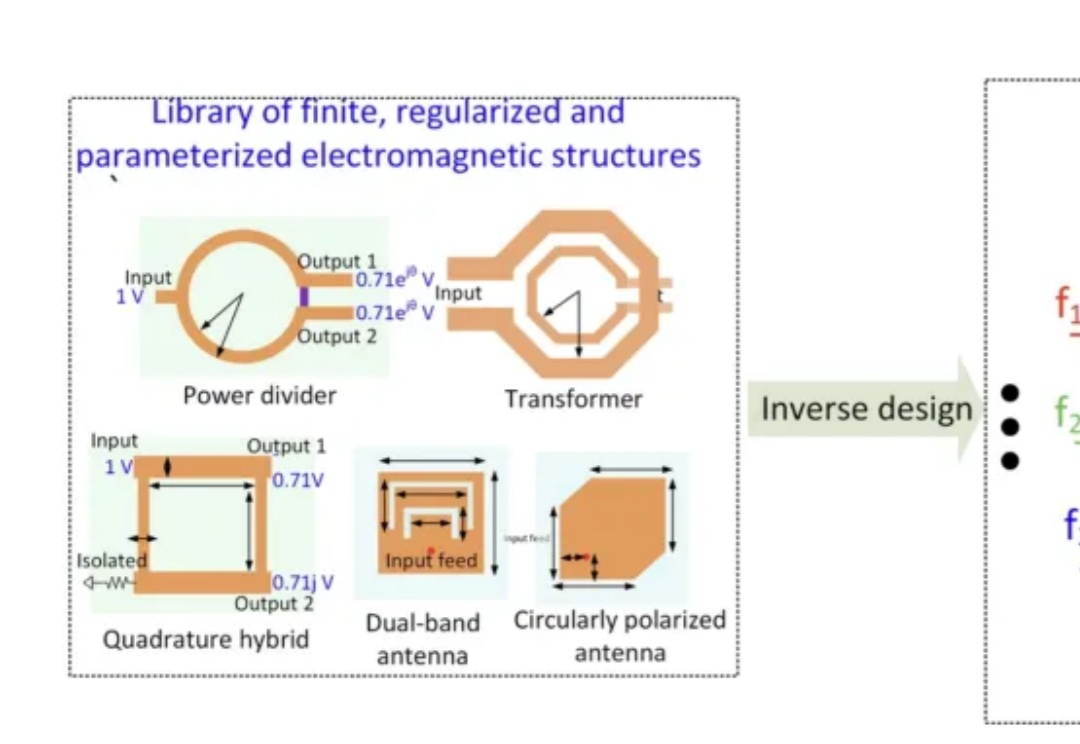
AI逆袭5G芯片设计,几分钟媲美半个月工作量!研究登Nature子刊
AI逆袭5G芯片设计,几分钟媲美半个月工作量!研究登Nature子刊来自普林斯顿和印度技术学院的学者在《自然通讯》发表论文,他们发现,如果给定设计参数,AI可以在90nm的芯片上设计高性能集成电路。过去这是需要花费数周时间的高技能工作,但如今的AI可以在数小时内完成。
来自主题: AI技术研报
4697 点击 2025-03-14 15:54
 搜索
搜索
来自普林斯顿和印度技术学院的学者在《自然通讯》发表论文,他们发现,如果给定设计参数,AI可以在90nm的芯片上设计高性能集成电路。过去这是需要花费数周时间的高技能工作,但如今的AI可以在数小时内完成。

助力半导体激光芯片国产化。

大模型时代,万物皆可AI,通信也不例外。
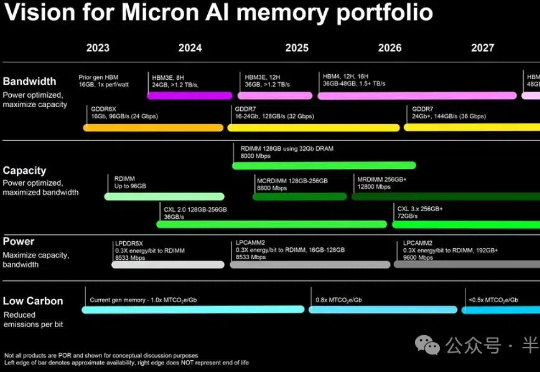
2月26日,美光宣布已率先向生态系统合作伙伴及特定客户出货专为下一代CPU设计的 1γ(1-gamma) 第六代 (10纳米级) DRAM节点DDR5内存样品。

在创始人、已故CEO乔布斯诞辰70周年之际,苹果宣布未来4年在本土投资5000亿美元,加速AI和半导体投资进度,将新建24家工厂,创造2万个就业岗位。
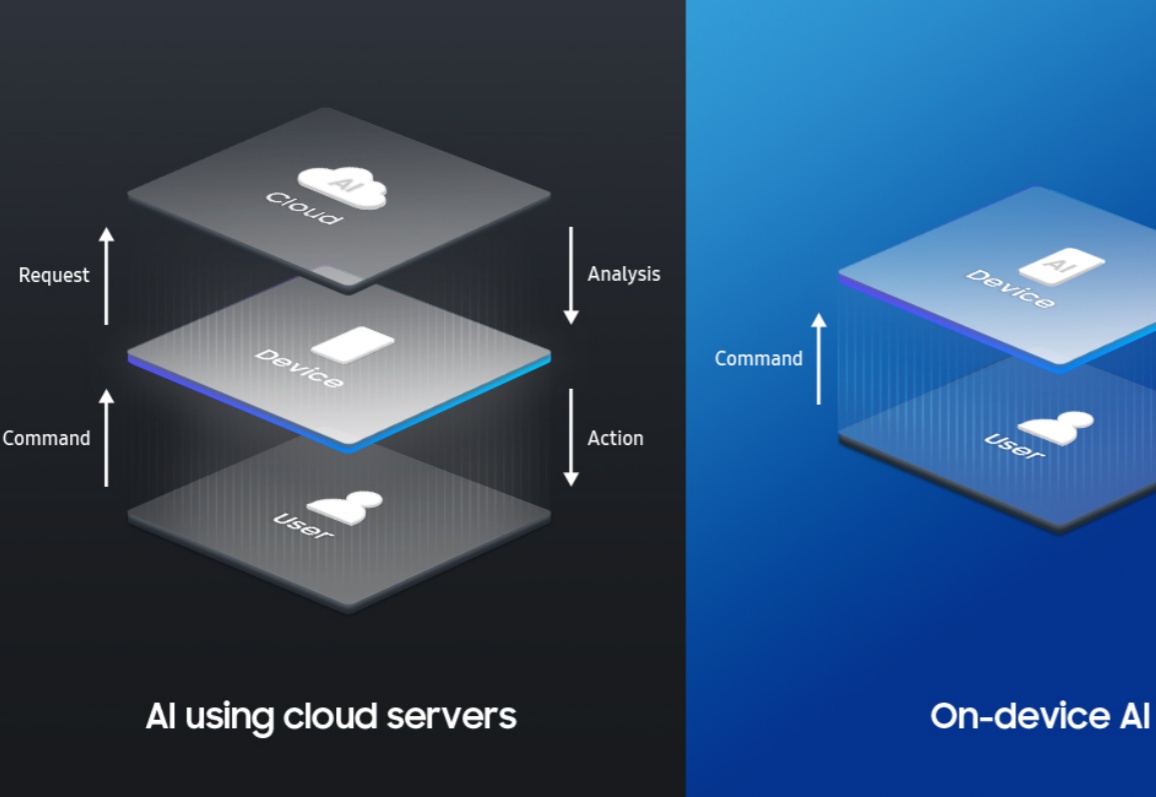
市场对于能适配小尺寸模型运行的端侧AI芯片需求开始水涨船高。
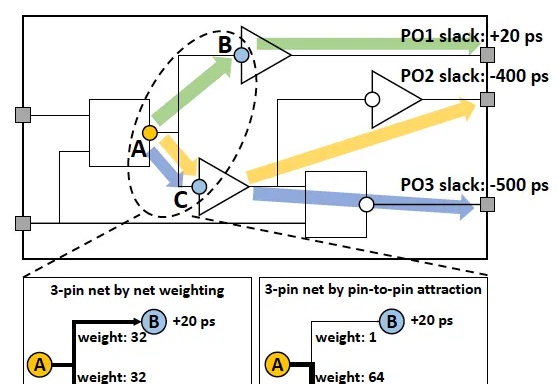
南大AI学院钱超教授团队,荣获EDA顶会2025最佳论文奖!其中,论文一作、四作、五作都是南大人工智能学院的本硕博生。芯片设计领域的传统难题——如何为多达百亿量级晶体管设计最优布局,从此有了一种巧妙的全新方法。

国内芯片设计研究团队,刚刚在国际学术顶会上获奖了。

国产GPU适配DeepSeek,商用前景广阔。

近年来,AI成为了国内手机市场上的最大热点。根据市研机构IDC的定义,AI手机有几个关键指标和特性:算力大于30TOPS的NPU、支持生成式AI模型的SoC、可以端侧运行各种大模型。而就在过去一年,国内AI手机市场迅猛发力。华为、小米、vivo、OPPO、荣耀等手机厂商,均已迅速在旗下产品上接入各自的云端或端侧AI大模型。