
刚刚,Ilya又发神图「思考者」!AI芯片海洋上在想啥?
刚刚,Ilya又发神图「思考者」!AI芯片海洋上在想啥?「什么都没说,却什么都说了。」Ilya用一幅Die Shot上的《思考者》引爆全网。
来自主题: AI资讯
10317 点击 2026-05-25 16:00
 搜索
搜索
「什么都没说,却什么都说了。」Ilya用一幅Die Shot上的《思考者》引爆全网。

219个词喂给AI,12小时后,一份7nm芯片版图出来了,工程师全程没碰键盘。这条芯片行业几十年没有AI走完过的路,第一次走通了。

OpenAI联手Broadcom造芯片,想摆脱对英伟达的单一依赖,却在关键一步上,仍被微软卡了脖子。

今日,在2026阿里云峰会上,阿里云正式亮出Agentic时代 “超级算力地基”。阿里云正式发布磐久AL128超节点服务器,搭载平头哥首次亮相的自研训推一体AI芯片真武M890,搭配自研互联芯片ICN Switch 1.0,单机柜128张AI芯片紧密耦合,组成一台“计算机”。

老黄在北京喝豆汁「翻车」,全网笑疯了。但真正值得警惕的,是他背后那个正在长出来的「中国版CUDA生态」。从万卡集群到机器狗,从SGLang主线到AI Agent自动迁移,这家公司这次不只是秀芯片,而是在重写国产GPU的游戏规则!

安全正在成为AI Infra的“基础能力”。
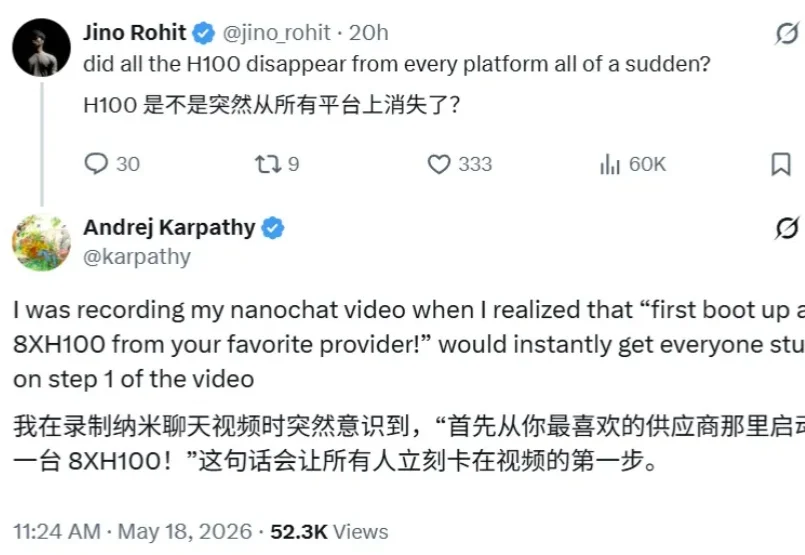
「H100 是不是突然从所有平台上消失了?」
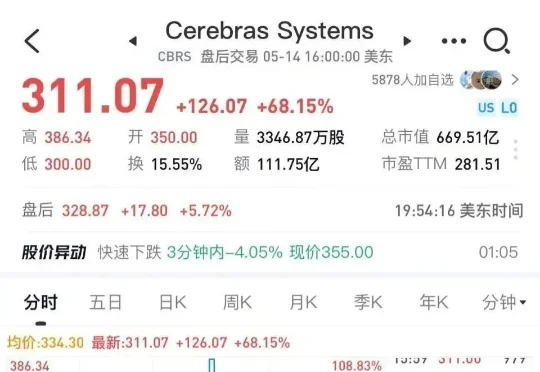
OpenAI「扶持」的AI芯片企业Cerebras Systems,正式在纳斯达克敲钟上市!股票代码为CBRS,发行价185美元,开盘价直接冲上350美元,盘中一度飙升到每股386美元(约合人民币2619元)。

通常我们见到的电脑芯片只有指甲盖大小,GPU 也就巴掌大,美国加州一家叫 Cerebras 的公司造出的芯片跟一个大号餐盘差不多,直径超过 200 毫米,面积 46,225 平方毫米,集成了 4 万亿个晶体管。
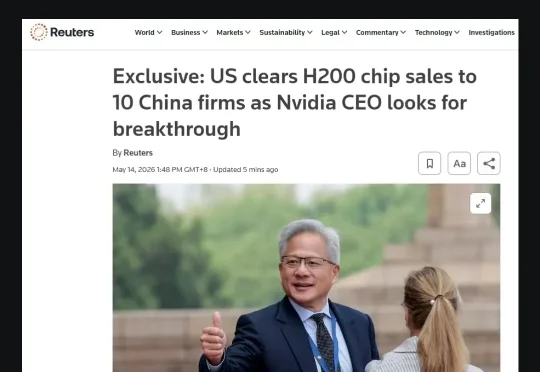
路透社今天报道称,美国已经批准约10家中国公司购买英伟达H200芯片,包括阿里巴巴、腾讯、字节跳动、京东、联想和富士康等。报道同时提到,虽然美国已经给出许可,但目前还没有H200芯片实际交付。