

大事即将发生
大事即将发生Matt Shumer 是 AI 创业者和投资者,已在 AI 领域深耕超过 6 年。他是 OthersideAI 的联合创始人兼 CEO,同时通过个人投资基金 Shumer Capital 投资了 Groq、Etched、OpenRouter 等多家前沿 AI 初创公司。
来自主题: AI资讯
9036 点击 2026-02-23 19:00
Matt Shumer 是 AI 创业者和投资者,已在 AI 领域深耕超过 6 年。他是 OthersideAI 的联合创始人兼 CEO,同时通过个人投资基金 Shumer Capital 投资了 Groq、Etched、OpenRouter 等多家前沿 AI 初创公司。
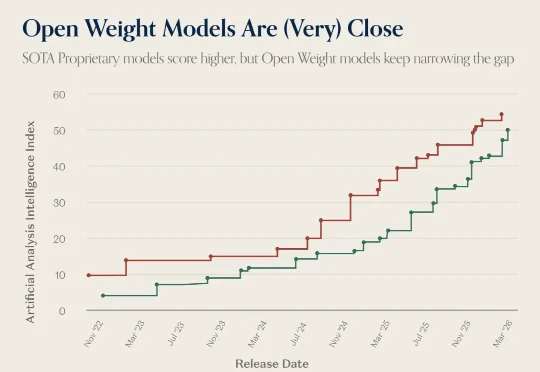
a16z 昨天发了一张图,把 GLM-5 和 Claude Opus 4.6 并排标注在 Artificial Analysis Intelligence Index 的时间线上。原文的说法是: A proprietary model (Claude Opus 4.6) is still the 'most intelligent,' but the gap between

来自阿里高德的一篇最新 ICLR 2026 中稿论文《Everything in Its Place: Benchmarking Spatial Intelligence of Text-to-Image Models》提出了面向文生图空间智能的系统性评估基准 SpatialGenEval,旨在通过长文本、高信息密度的 T2I prompt 设计,以及围绕空间感知

刚刚推出的一款最新芯片,直接冲上硅谷热榜。峰值推理速度高达每秒17000个token。什么概念呢?当前公认最强的Cerebras,速度约为2000 token/s。 速度直接快10倍,同时成本骤减20倍、功耗降低10倍。

谷歌旗下的 Isomorphic Labs 发布新一代 AI 药物设计引擎 IsoDDE,性能全面碾压 AlphaFold 3,能在几秒内发现科学家花 15 年才找到的隐藏结合位点。但与开源的 AlphaFold 不同,IsoDDE 选择完全闭源,代码、论文、方法均不公开。AI 造福科学的开源黄金时代,可能正走向终结。

在印度人工智能影响力峰会上,出现 AI 圈最尴尬的一次合影。印度总理莫迪举起 Sam Altman 和 Sundar Pichai 的手,其他大佬也纷纷效仿牵手,唯独 Altman 和 Anthropic CEO Dario Amodei 并肩站立。

机器之心编译 如果把人生看作一个开放式的大型多人在线游戏(MMO),那么游戏服务器在刚刚完成一次重大更新的时刻,规则改变了。 自 2022 年 ChatGPT 惊艳亮相以来,世界已经发生了深刻变化。在

1970年,一个叫Gordon Gallup的心理学家把一面镜子放进了黑猩猩的笼子里。黑猩猩一开始对着镜子龇牙。它以为那是另一只黑猩猩。它威胁它,拍胸脯,绕到镜子后面找那只不存在的敌人。

近日,微软Bing Ads与DKI团队发表论文《AdNanny: One Reasoning LLM for All Offline Ads Recommendation Tasks》,宣布基于DeepSeek-R1 671B打造了统一的离线推理中枢AdNanny,用单一模型承载所有离线任务。这标志着从维护一系列任务特定模型,转向部署一个统一的、推理中心化的基础模型,从
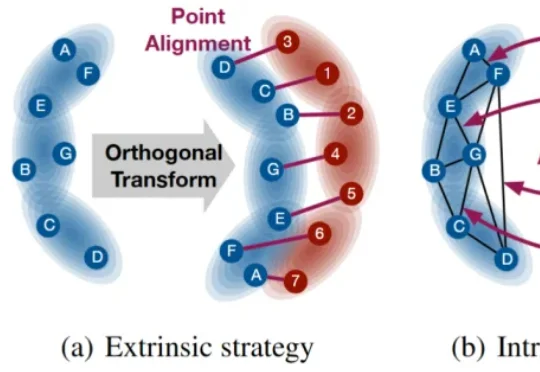
本文提出一种具有 SE(p) 不变传输性质的度量 SEINT:通过构造无需训练的 SE(p) 不变表示,将高维结构信息压缩为可用于 Optimal Transport (OT) 对齐的一维表征,从而在保持不变性与严格度量性质的同时显著提升效率。