
刚刚!Anthropic发布Claude Sonnet 5,价格只有Opus 4.8的六成
刚刚!Anthropic发布Claude Sonnet 5,价格只有Opus 4.8的六成就在刚刚,Claude Sonnet 5来了!代号Fennec,耳廓狐,撒哈拉沙漠里体型最小的狐狸。相较于上一代Sonnet 4.6,Sonnet 5在推理、工具使用、编程和知识工作任务中,性能显著提升。
来自主题: AI资讯
8772 点击 2026-07-01 09:05
 搜索
搜索
就在刚刚,Claude Sonnet 5来了!代号Fennec,耳廓狐,撒哈拉沙漠里体型最小的狐狸。相较于上一代Sonnet 4.6,Sonnet 5在推理、工具使用、编程和知识工作任务中,性能显著提升。

都说AI会写代码了,程序员的饭碗就保不住。但Anthropic的Boris Cherny却说:真正重要的从来不是岗位,而是你这一刻在扮演哪种角色。

AI能提效不假,但账单却越来越看不懂了。

AI圈彻底进入生死时速!OpenAI和Anthropic极限狂飙,平均51天空降一个新模型,直接把谷歌甩在了身后。

GPT-5.6 Sol被拆分、被按住,Fable 5被全球禁用72小时后才戴着镣铐回归。Anthropic和OpenAI最强模型,双双被「切脑」。

封杀两周后,美国突然解禁Anthropic最强AI模型,却只限白名单上的百家巨头!全球用户被拒之门外,GPT-5.6也紧随其后搞「美国专属」。我们还能用到Claude 5吗?

短短四个月,四家中国顶级AI公司被Anthropic接连点名,且没有停手的迹象。Anthropic向美国参议院银行委员会递交了一封信,矛头直指阿里Qwen团队。报告披露了一串数字:从4月22日到6月5日,整整45天,阿里相关运营者利用2.5万个账号,完成了2880万次交互。

如果我们谈到 AI 赋能带来的科学突破,AlphaFold 一定是不可忽略的一项。它解决了困扰生物学界半个多世纪的蛋白质折叠难题,大量压缩了得到蛋白质结构的时间,从原来的一年,到现在的几分钟。它的核心开发者之一 John Jumper 也因这一贡献在 2024 年摘得诺贝尔化学奖。
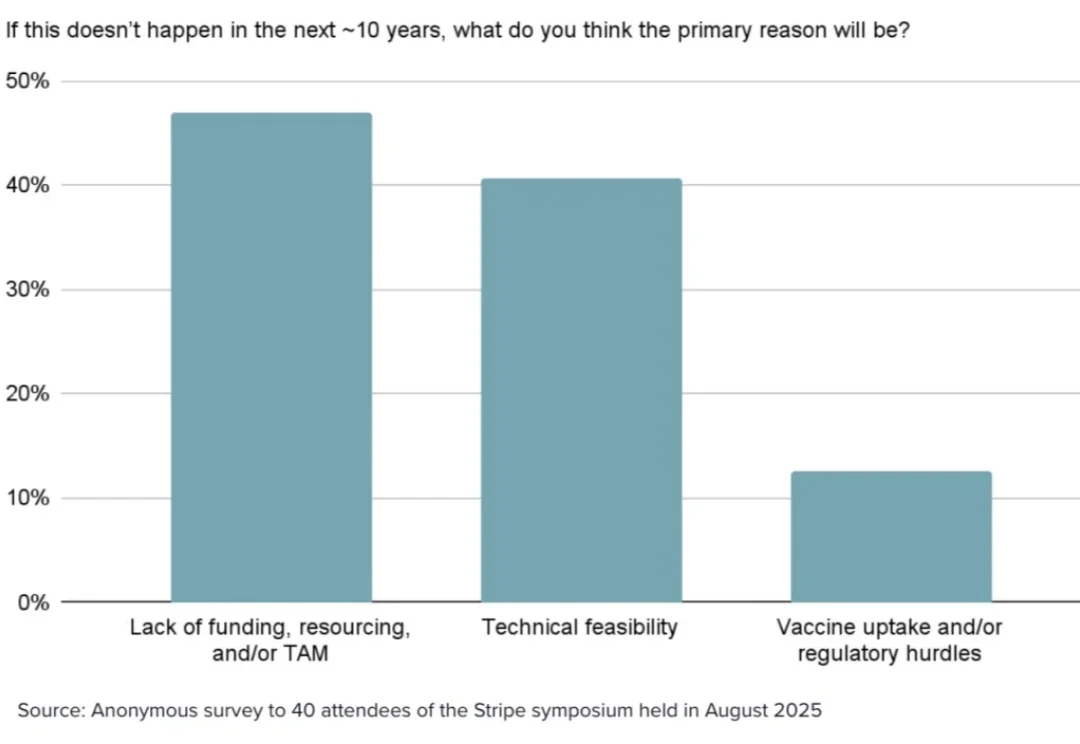
一百年前,霍乱、伤寒、痢疾等水源性疾病曾被视为生活中不可避免的一部分。后来,人类通过药物和净水基础设施,降低了疾病的发生率。

Harsh Mehta 在 Anthropic 的时候,启动了一个后来被称为 autoresearch 的内部平台(不是 Karpathy 那个)。最初这个项目只有他一个人,功能是让 AI 自主完成 AI 研发中的一系列流程环节:提出实验假设、编写代码、调度算力、评估结果,再决定下一步做什么。