
速递|Mythos带来AI安全压力,欧洲银行联手Mistral开发本土AI网络安全模型
速递|Mythos带来AI安全压力,欧洲银行联手Mistral开发本土AI网络安全模型法国巴黎银行正与法国人工智能初创公司 Mistral AI 及其他合作伙伴合作,为应对 Anthropic 旗下 Mythos 等新模型带来的网络安全威胁做准备。
来自主题: AI资讯
7859 点击 2026-05-27 16:10
 搜索
搜索
法国巴黎银行正与法国人工智能初创公司 Mistral AI 及其他合作伙伴合作,为应对 Anthropic 旗下 Mythos 等新模型带来的网络安全威胁做准备。
哈?卡帕西在Anthropic只是个「技术员工」??

同一周,Anthropic联创和DeepMind掌门同时预警!2028年AI递归自我改进概率超60%,2030年AGI或全面降临。100倍于工业革命的冲击波,正全速砸向全人类。
SpaceX 2025 年全年营收是187 亿美元。这是这家火箭公司用了 23 年积累下来的成果——从 2002 年创立,到把猎鹰 9 号变成最可靠的运载火箭,再到星链卫星互联网,23 年换来的年收入数字。然后 Anthropic 来了一份合同:每年 150 亿美元。

“Claude 可能比你更擅长从你这里提取出你想要和需要的东西,而不是由你向 Claude 详细指定。”

几乎同一天,Anthropic三大超级AI提前曝光!Claude Opus 4.8突袭谷歌后台,Sonnet 4.8跳级4.7。曾经叫嚣着「太危险不公开」的Mythos 1,也现身了。

Anthropic实锤:Claude裸跑模型,9美元全废;但是套上Harness花200美元效果直接起飞。AI效果不好?别再纠结换模型了!OpenAI和Anthropic都在用的Harness工程,一文讲透。

这不是科幻小说,而是 METR(模型评估与训练研究组织)联合Anthropic、Google、Meta和OpenAI 进行内部红队测试后,发布的首份《前沿风险报告》中披露的真实案例。这是四大巨头第一次允许第三方深入测试他们内部最强、可访问完整思维链(CoT)的模型,并开放非公开的对齐与控制信息。
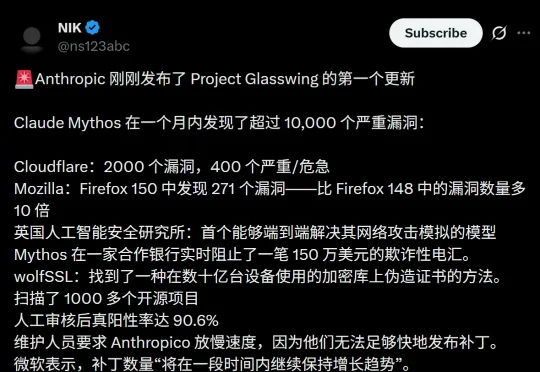
A厂的玻璃翼计划首战告捷,Mythos 30天内就挖出1万个致命漏洞,甚至拦截了150万美元电诈!面对雪片式的报告,人类程序员也崩溃求饶了:「求别挖了,根本修不完啊!」

Claude 100%编码Claude,这在圈内早已不是秘密。但Claude「自我造物」全过程,始终是Anthropic严防死守的核心机密。就在今天,Anthropic产品负责人Alex Albert在一场35分钟的访谈中,首次毫无保留地曝光了全细节!