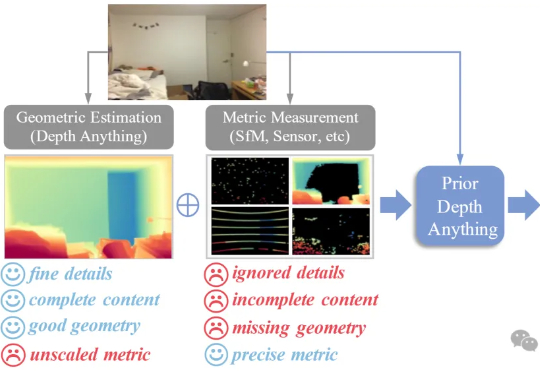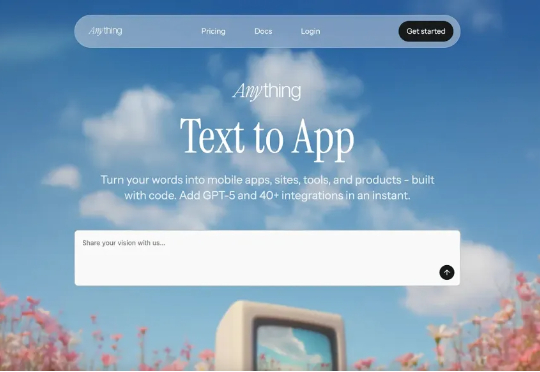
两周冲到200万美元ARR!这家AI创业公司凭什么拿下1亿美元估值?
两周冲到200万美元ARR!这家AI创业公司凭什么拿下1亿美元估值?这不是科幻,这是 Anything 正在发生的真实故事。这家刚刚完成 1100 万美元融资、估值达到 1 亿美元的创业公司,在上线两周内就实现了 200 万美元的年度经常性收入。更让人震惊的是,他们的用户已经开始用这个平台做出真正赚钱的生意。我深入研究了这家公司后,发现他们不只是又一个 AI 编程工具,而是在彻底改变软件开发的游戏规则。
来自主题: AI资讯
7968 点击 2025-10-12 15:03